Last week I spoke in Montreal at a session of the Philosophy of Science Association meeting. Here are some notes for it. Later on I’ll do a post about the other talks at the meeting.
Right now, though, the meeting slowed me down from describing a recent talk in the seminar here at IST. This was Gonçalo Rodrigues’ talk on categorifying measure theory. It was based on this paper here, which is pretty long and goes into some (but not all) of the details. Apparently an updated version that fills in some of what’s not there is in the works.
In any case, Gonçalo takes as the starting point for categorifying ideas in analysis the paper “Measurable Categories” by David Yetter, which is the same point where I started on this topic, although he then concludes that there are problems with that approach. Part of the reason for saying this has to do with the fact that the category of Hilbert spaces has many bad properties – or rather, fails to have many of the good ones that it should to play the role one might expect in categorifying ideas from analysis.
Yetter’s idea can be described, very roughly, as follows: we would like to categorify the concept of a function-space on a measure space 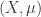 . That is, spaces like
. That is, spaces like  or
or  . The reason for this is that the 2-vector-spaces of Kapranov and Voevodsky are very elegant, but intrinsically finite-dimensional, categorifications of “vector space”. An infinite-dimensional version would be important for representation theory, particularly of noncompact Lie groups or 2-groups, but even just infinite ones, since there are relatively few endomorphisms of KV 2-vector spaces. Yetter’s paper constructs analogs to the space of measurable functions
. The reason for this is that the 2-vector-spaces of Kapranov and Voevodsky are very elegant, but intrinsically finite-dimensional, categorifications of “vector space”. An infinite-dimensional version would be important for representation theory, particularly of noncompact Lie groups or 2-groups, but even just infinite ones, since there are relatively few endomorphisms of KV 2-vector spaces. Yetter’s paper constructs analogs to the space of measurable functions  , where “functions” take values in Hilbert spaces.
, where “functions” take values in Hilbert spaces.
A measurable field of Hilbert spaces is, roughly, a family of Hilbert spaces indexed by points of  , together with a nice space of “measurable sections”. This is supposed to be an infinite-dimensional, measure-theoretic counterpart to an object in a KV 2-vector space, which always looks like
, together with a nice space of “measurable sections”. This is supposed to be an infinite-dimensional, measure-theoretic counterpart to an object in a KV 2-vector space, which always looks like  for some natural number
for some natural number 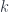 , which is now being replaced by . One of the key tools in Yetter’s paper is the direct integral of a field of Hilbert spaces, which is similarly the counterpart to the direct sum
, which is now being replaced by . One of the key tools in Yetter’s paper is the direct integral of a field of Hilbert spaces, which is similarly the counterpart to the direct sum  in the discrete world. It just gives the space of measurable sections (taken up to almost-everywhere equivalence, as usual). This was the main focus of Gonçalo’s talk.
in the discrete world. It just gives the space of measurable sections (taken up to almost-everywhere equivalence, as usual). This was the main focus of Gonçalo’s talk.
The direct integral has one major problem, compared to the (finite) direct sum it is supposed to generalize – namely, the direct sum is a categorical coproduct, in 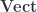 or any other KV 2-vector space. Actually, it is both a product and a coproduct ( is abelian), so it is defined by a nice universal property. The direct integral, on the other hand, is not. It doesn’t have any similarly nice universal property. (In the infinite-dimensional case, colimits and limits would be expected to become different in any case, but the direct integral is neither). This means that many proofs in analysis will be hard to reproduce in the categorified setting – universal properties mean one doesn’t have to do nearly as much work to do this, among their other good qualities. This is related to the issue that the category
or any other KV 2-vector space. Actually, it is both a product and a coproduct ( is abelian), so it is defined by a nice universal property. The direct integral, on the other hand, is not. It doesn’t have any similarly nice universal property. (In the infinite-dimensional case, colimits and limits would be expected to become different in any case, but the direct integral is neither). This means that many proofs in analysis will be hard to reproduce in the categorified setting – universal properties mean one doesn’t have to do nearly as much work to do this, among their other good qualities. This is related to the issue that the category  does not have all limits and colimits
does not have all limits and colimits
Gonçalo’s paper and talk outline a program where one can categorify a lot of the proofs in analysis, by using a slightly different framework which uses a bigger category than , namely  , whose objects are Banach spaces and whose maps are (linear) contractions. A Banach Category is a category enriched in . Now, Banach spaces have a norm, but not necessarily an inner product, and this small weakening makes them much worse than Hilbert spaces as objects. Many intuitions from Hilbert spaces, like the one that says any subspace has a complement, just fail: the corresponding notion for Banach spaces is the quasicomplement ( and
, whose objects are Banach spaces and whose maps are (linear) contractions. A Banach Category is a category enriched in . Now, Banach spaces have a norm, but not necessarily an inner product, and this small weakening makes them much worse than Hilbert spaces as objects. Many intuitions from Hilbert spaces, like the one that says any subspace has a complement, just fail: the corresponding notion for Banach spaces is the quasicomplement ( and 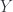 are quasicomplements if they intersect only at zero, and their sum is dense in the whole space), and it’s quite possible to have subspaces which don’t have one. Other unpleasant properties abound.
are quasicomplements if they intersect only at zero, and their sum is dense in the whole space), and it’s quite possible to have subspaces which don’t have one. Other unpleasant properties abound.
Yet is a much nicer category than 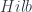 . (So we follow the general dictum that it’s better to have a nice category with bad objects than a bad category with nice objects – the same motivation behind “smooth spaces” instead of manifolds, and the like.) It’s complete and cocomplete (i.e. has all limits and colimits), as well as monoidal closed – for Banach spaces
. (So we follow the general dictum that it’s better to have a nice category with bad objects than a bad category with nice objects – the same motivation behind “smooth spaces” instead of manifolds, and the like.) It’s complete and cocomplete (i.e. has all limits and colimits), as well as monoidal closed – for Banach spaces  and
and  , the space
, the space  is also in . None of these facts holds for . On the other hand, the space of bounded maps between Hilbert spaces is a Banach space (with the operator norm), but not necessarily a Hilbert space. So even is already a Banach category.
is also in . None of these facts holds for . On the other hand, the space of bounded maps between Hilbert spaces is a Banach space (with the operator norm), but not necessarily a Hilbert space. So even is already a Banach category.
It also turns out that, unlike in , limits and colimits (where those exist in ) are not necessarily isomorphic. In particular, in , the coproduct and product  and
and 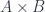 both have the same underlying vector space
both have the same underlying vector space  , but the norms are different. For Hilbert spaces, the inner product comes from the Pythagorean formula in either case, but for Banach spaces, the coproduct gets the sum of the two norms, and the product gets the supremum. It turns out that coproducts are the more important concept, and this is where the direct integral comes in.
, but the norms are different. For Hilbert spaces, the inner product comes from the Pythagorean formula in either case, but for Banach spaces, the coproduct gets the sum of the two norms, and the product gets the supremum. It turns out that coproducts are the more important concept, and this is where the direct integral comes in.
First, we can talk about Banach 2-spaces (the analogs of 2-vector spaces): these are just Banach categories which are cocomplete (have all weighted colimits). Maps between them are cocontinuous functors – that is, colimit-preserving ones. (Though properly, functors between Banach categories ought to be contractions on Hom-spaces). Then there are categorified analogs of all sorts of Banach space structure in a familiar way – the direct sum (coproduct) is the analog of vector addition, the category is the analog of the base field (say,  ), and so on.
), and so on.
This all gives the setting for categorified measure theory. Part of the point of choosing is that you can now reason out at least some of how it works by analogy. To start with, one needs to fix a Boolean algebra  – this is to be the
– this is to be the 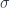 -algebra of measurable sets for some measure space, though it’s important that it needn’t have any actual points (this is a notion of measure space akin to the notion of locale in the topological world). This part of the theory isn’t categorified (arguably a limitation of this approach, but not one that’s any different from Yetter’s). Instead, we categorify the definition of measure itself.
-algebra of measurable sets for some measure space, though it’s important that it needn’t have any actual points (this is a notion of measure space akin to the notion of locale in the topological world). This part of the theory isn’t categorified (arguably a limitation of this approach, but not one that’s any different from Yetter’s). Instead, we categorify the definition of measure itself.
A measure is a function  – it assigns a number to each measurable set. The pair
– it assigns a number to each measurable set. The pair  is a measure algebra, and relates to a measure space the way a locale relates to a topological space. So a categorified measure
is a measure algebra, and relates to a measure space the way a locale relates to a topological space. So a categorified measure  should be a functor from (seen now as a category) into . (We can generalize this: the measure could be valued in some vector space over , and a categorified measure could be a functor into some other Banach 2-space.) Since we’re thinking of as a lattice of subsets, it makes some sense to call a presheaf, or rather co-presheaf. What’s more, just as a measure is additive (
should be a functor from (seen now as a category) into . (We can generalize this: the measure could be valued in some vector space over , and a categorified measure could be a functor into some other Banach 2-space.) Since we’re thinking of as a lattice of subsets, it makes some sense to call a presheaf, or rather co-presheaf. What’s more, just as a measure is additive (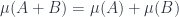 , for disjoint sets, where
, for disjoint sets, where  is the union), so also the categorical measure should be (finitely) additive up to isomorphism. So we’re assigning Banach spaces to all the measurable sets. This is a “co”-presheaf – which is to say, a covariant functor, so the spaces “nest”: when for measurable sets, we have
is the union), so also the categorical measure should be (finitely) additive up to isomorphism. So we’re assigning Banach spaces to all the measurable sets. This is a “co”-presheaf – which is to say, a covariant functor, so the spaces “nest”: when for measurable sets, we have  , then
, then  also.
also.
An intuition for how this works comes from a special case (not at all exhaustive), where we start with an actual, uncategorified, measure space . Then one categorified measure will arise by taking 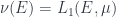 : the Banach space associated to a measurable set
: the Banach space associated to a measurable set 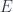 is the space of integrable functions. We can take any “scalar” multiple of this, too: given a fixed Banach space , let
is the space of integrable functions. We can take any “scalar” multiple of this, too: given a fixed Banach space , let  . But there are lots of examples that aren’t like this.
. But there are lots of examples that aren’t like this.
All this is fine, but the point here is to define integration. The usual way to go about this when you learn analysis is to start with characteristic functions of measurable sets, then define a sequence through simple functions, measurable functions, and so forth. Eventually one can define 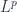 spaces based on the convergence of various integrals. Something similar happens here.
spaces based on the convergence of various integrals. Something similar happens here.
The analog of a function here is a sheaf: a (compatible) assignment of Banach spaces to measurable sets. (Technically, to get to sheaves, we need an idea of “cover” by measurable sets, but it’s pretty much the obvious one, modulo the subtlety that we should only allow countable covers.) The idea will be to start with characteristic sheaves for measurable sets, then take some kind of completion of the category of all of these as a definition of “measurable sheaf”. Then the point will be that we can extend the measure from characteristic sheaves to all measurable sheaves using a limit (actually, a colimit), analogous to the way we define a Lebesgue integral as a limit of simple functions approximating a measurable one.
A characteristic sheaf 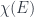 for a measurable set
for a measurable set  might be easiest to visualize in terms of a characteristic bundle, which just puts a copy of the base field (we’ve been assuming it’s ) at each point of , and the zero vector space everywhere else. (This is a bundle in the measurable sense, not the topological one – assuming has a topology other than itself.) Very intuitively, to turn this into a sheaf, one can just use brute force and take a set the product of all the spaces lying in . A little less crudely, one should take a space of sections with decent properties – so that assigns to a space of functions on
might be easiest to visualize in terms of a characteristic bundle, which just puts a copy of the base field (we’ve been assuming it’s ) at each point of , and the zero vector space everywhere else. (This is a bundle in the measurable sense, not the topological one – assuming has a topology other than itself.) Very intuitively, to turn this into a sheaf, one can just use brute force and take a set the product of all the spaces lying in . A little less crudely, one should take a space of sections with decent properties – so that assigns to a space of functions on 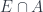 . In particular, the functor
. In particular, the functor  which picks out all the (measurable) bounded sections is a universal way to do this.
which picks out all the (measurable) bounded sections is a universal way to do this.
Now the point is that the algebra of measurable sets, , thought of as a category, embeds into the category of presheaves on it by  , taking a set to its characteristic sheaf. Given a measure valued in some Banach category,
, taking a set to its characteristic sheaf. Given a measure valued in some Banach category,  , we can find the left Kan extension
, we can find the left Kan extension  , such that
, such that 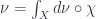 . The Kan extension is a universal way to extend to all of
. The Kan extension is a universal way to extend to all of 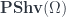 so that this is true, and it can be calculated as a colimit.
so that this is true, and it can be calculated as a colimit.
The essential fact here is that the characteristic sheaves are dense in : any presheaf can be found as a colimit of the characteristic ones. This is analogous to how any function can be approximated by linear combinations of characteristic functions. This means that the integral defined above will actually give interesting results for all the sheaves one might expect.
I’m glossing over some points here, of course – for example, the distinction between sheaves and presheaves, the role of sheafification, etc. If you want to get a more accurate picture, check out the paper I linked to up above.
All of this granted, however, many of the classical theorems of measure theory have analogs that are proved in essentially the same way as the standard versions. One can see the presheaf category as a categorified analog of  , and get the Fubini theorem, for instance: there is a canonical equivalence (no longer isomorphism) between (a suitable) tensor product of
, and get the Fubini theorem, for instance: there is a canonical equivalence (no longer isomorphism) between (a suitable) tensor product of 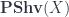 and
and  on one hand, and on the other
on one hand, and on the other 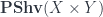 . Doing integration, one can then do all the usual things – exchange order of integration between and , say – in analogous conditions. The use of universal properties to define integrals etc. means that one doesn’t need to fuss about too much with coherence laws, and so the proofs of the categorified facts are much the same as the original proofs.
. Doing integration, one can then do all the usual things – exchange order of integration between and , say – in analogous conditions. The use of universal properties to define integrals etc. means that one doesn’t need to fuss about too much with coherence laws, and so the proofs of the categorified facts are much the same as the original proofs.

November 12, 2010 at 2:14 pm
Isn’t this “categorified measure theory” equivalent to the theory of Hilbert W*-modules over a commutative von Neumann algebra?
The category of measurable spaces and their morphisms is contravariantly equivalent
to the category of commutative von Neumann algebras.
Now for every commutative von Neumann algebra M there is a notion of Hilbert W*-module over M,
which can be thought informally as a bundle of Hilbert spaces over Spec M.
Sheaf-theoretically, we can think of a W*-module X over M as a sheaf of W*-modules (or Banach spaces) over the site Spec M (contrary to your claim,
open covers need not be countable and Spec M is a real site).
A characteristic sheaf is simply a line bundle
over a measurable subset.
Every W*-module is a colimit of such sheaves,
and the category of W*-modules is cocomplete.
The same is true for limits and completeness.
The integration is given by the global sections map.
Fubini theorem is also true in this setting.
November 12, 2010 at 3:22 pm
I’m not sure if the theories are exactly equivalent, though they’re clearly related, as one might expect – since as you say, a commutative von Neumann algebras “is” exactly a measure space (depending on what the meaning of the word “is” is). Goncalo Rodrigues’ statement that the relevant site here requires that covers be countable seems to suggest the theories are not identical, but perhaps that assumption is stronger than is needed. Other than that, the points you mention certainly seem to match up with the slightly different language he’s using, so I wouldn’t be surprised if they were equivalent formulations described in two different languages. Assuming they do, I still think there’s some conceptual value-added in understanding this theory as a categorification, looking at additive co-presheaves as analogous to measures, etc. If nothing else, knowing that allows you to import proofs from standard theory of integration without having to think much further. Moreover, it suggests ways of using the theory – namely, to produce categorified analogues of everything you can do with standard function spaces. (You might have to be convinced first that categorification in general is a good idea for this to sound like much of a reason, admittedly.)
I do agree that it’s nice to describe things in terms of von Neumann algebras. For example, suppose we assume the Baez-Baratin-Freidel-Wise premise that a general 2-Hilbert space is the representation category of some von Neumann algebra – not necessarily commutative, but we can assume they are if need be. (I’m not entirely convinced this classification is complete, but in any case all of these should be examples of 2-Hilbert spaces.) These representations, if I understand the definition correctly, are thus Hilbert W*-modules. Then 2-linear maps between these 2-Hilbert spaces (i.e. additive functors compatible with the enrichment, etc.) will arise whenever there’s a Hilbert bimodule between the two algebras (it’s less clear to me that this is exhaustive in the infinite dimensional case, as it is in finite dimensions). Then natural transformations between such functors can be described in terms of bimodule maps, and there’s a bunch of potentially interesting physics (e.g.) involved there. The 2-Hilbert space jargon just emphasises the formal analogy between the object-and-morphism level in 2Hilb and Hilb, where a more direct reading would instead look at the morphisms and 2-morphisms in 2Hilb in terms of bi-equivariant Hilbert (or Banach) spaces, and both are presumably relevant to properly understanding the 2-category in which these things live (2Hilb).
Incidentally, can you suggest a good reference to look at for more details on the theory of Hilbert W*-modules? I know a little of that stuff, but I’m not immediately able to find anything that gives details on the points you mentioned (just a reference to Takesaki’s book on operator algebras, which I don’t have ATM).
November 12, 2010 at 4:34 pm
Apparently you need countable open covers because you don’t factor out the sets of measure 0.
Once you do this, the theories become equivalent.
The ideas in the second paragraph of your reply can be expressed rigorously as follows:
There is an equivalence between the bicategory of von Neumann algebras, Hilbert W*-bimodules, and intertwiners
and the bicategory of W*-categories with a generator, directs sums, and sufficient subobjects,
normal *-functors, and bounded natural transformations.
A good reference for this is a paper by Ghez, Lima, and Roberts: W*-categories.
(See Proposition 7.6.)
Alternatively, instead of Hilbert W*-bimodules
you can take Hilbert spaces with two actions
of von Neumann algebras and Connes’ fusion as composition.
This yields an equivalent bicategory.
Concerning sites in measure theory, see also this answer of mine:
http://mathoverflow.net/questions/20740/is-there-an-introduction-to-probability-theory-from-a-structuralist-categorical-p/20820#20820
November 14, 2010 at 2:36 pm
Yes, the Connes fusion product seems to be just the general form of composition for 2-linear maps. In the finite-dimensional case, the irreducible parts of the Hilbert bimodules assemble into the matrix elements in the Kapranov-Voevodsky classification for those functors. The infinite dimensional case is trickier but analogous.
The 2-category in question seems to be a good candidate for 2Hilb, though there might be other possibilities (for example, module categories for quantales could be another possible classification for 2-Hilbert spaces). That choice should probably be made on (pseudo-)physical grounds, as the 2-category that supports the right kind of models. The BBFW premise that I mentioned was intended to describe the right setting for representation theory of categorical groups such as the Poincare 2-group, which is supposed to be used for spin foam models.
At any rate, thanks for the reference – I’ve started reading the Ghez-Lima-Roberts paper, which looks good, and no doubt sheds some more light on the issue.
November 22, 2010 at 2:46 pm
A bit late to the party, but here goes my take on this anyway. My express purpose in writing “Categorifying measure theory” was to take another look at some very classical material (direct integrals) and interpret it as a categorification of measure theory. There is very little in it that is truly original. But to answer your question more directly, the answer is yes: where the two theories intersect they are morally (if not actually, I have not worked out all the details) the same.
There are some some minor, technical differences and some more substantial ones. I will just point out that the (symmetric) difference of the two theories is non-empty. For example, there is a notion of categorified measure, a cosheaf for an appropriate Grothendieck topology on a Boolean algebra, and we can define the direct integral against any such cosheaf. Such cosheaves can take values in any category enriched in Banach spaces that is cocomplete (in the enriched sense). There are *many* cosheaves out there that do not come from scalar measures on the base space. This is the categorified analogue of the integral of scalar functions against vector measures. By bitensoring, we can define the analogue of the integral of vector functions against scalar measures. With this generalization in hand, such theorems as Fubini or Fubini-Tonelli are essentially trivial: their proofs are not only straightforward, but they are straightforward “categorifications” of the straightforward proofs of the corresponding results in ordinary measure theory.
An analogy can be drawn with the concept of space and its two generalizations given by NCG and Topos theory. Categorified measure theory corresponds roughly to travelling up the topos theory axis of generalization.
Note: let me just clarify a technical point. For reasons both of convenience and necessity, the more important Grothendieck topology is the one that has for basis the *finite* covering families. If you take *complete* Boolean algebras and *arbitrary* covering families then you are in the terrain of Von-Neumann algebras, otherwise, the L_{\infty}-Banach algebra (note: this can be defined independently, but it is isomorphic to the Banach algebra of continuous functions of the Stone space, which in its turn is just the spectrum of L_{\infty}) is just a C*-star algebra. Of course, if the Boolean algebra is sigma-additive and you have a sigma-additive measure, then modding out the null-ideal, the countable chain condition kicks in and ensures order completeness.
September 19, 2013 at 7:35 am
I tried to skim through the paper, but most of the analysis is either way over my head or long forgotten. I couldn’t figure out how classical measure theory embeds into its categorified version — it should, right? I’d be very grateful for any hints on that. Another very naive question is whether the paper succeeds in viewing standard integrals as a particular case of coend.
September 19, 2013 at 3:02 pm
I haven’t looked at this in a while, but I’ll take the best stab I can here… To begin with, as he notes in the paper, the sense of “categorified measure theory” being used here is maybe more clearly expressed as a categorification of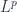 spaces, and Banach spaces generally. The idea of spaces and measures themselves are still in use – it’s a question of categorifying what sorts of things they’re used to integrate. He’s following the paper by Yetter on measurable fields of Hilbert spaces – which are taken to be the categorified analog of measurable functions.
spaces, and Banach spaces generally. The idea of spaces and measures themselves are still in use – it’s a question of categorifying what sorts of things they’re used to integrate. He’s following the paper by Yetter on measurable fields of Hilbert spaces – which are taken to be the categorified analog of measurable functions.
I suppose there are also different views of what you should expect in the way of an uncategorified theory embedding into a categorified theory. This case is taking the view that a “categorification” of a structure in the universe of sets is a somehow analogous structure in the universe of categories. Thus, a “2-vector space” is a kind of category (abelian, enriched in vector spaces, etc) – the category of measurable fields of Hilbert spaces being an infinite-dimensional generalization of this kind of category.
The way ordinary vector spaces embed into 2Vect is as an object: the category of vector spaces is a 2-vector space. In particular, it’s the 1-dimensional 2-vector space, the way you can find the complex numbers embedded in Vect as the 1D vector space, and so regard Vect as a categorification of the complex numbers (or some people might prefer to think of the embedding of its endomorphism space as the really salient one – but they’re isomorphic, so this is mostly an aesthetic preference).
So, as with 2-vector spaces, given a measure space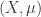 , you can find the ordinary space of measurable functions as, in some sense, one very specific object in the category of measurable fields of Hilbert spaces. Namely, the one which assigns the 1-dimensional space of complex numbers (or real numbers if we’re in that world) to each point of
, you can find the ordinary space of measurable functions as, in some sense, one very specific object in the category of measurable fields of Hilbert spaces. Namely, the one which assigns the 1-dimensional space of complex numbers (or real numbers if we’re in that world) to each point of  . Then the space of measurable sections of this field is exactly the space of measurable functions.
. Then the space of measurable sections of this field is exactly the space of measurable functions.
This is different from the kind of embedding people often think of in “categorification” – for instance, by finding a set-theoretic structure as, for instance, the Grothendieck ring, or set of isomorphism classes, of some “categorified” structure. That, I think, is the kind of embedding you’d need to be able to expect to interpret integrals as coends (or coends that have been somehow decategorified) – rather than as merely analogous to coends. (Unless I’m overlooking something critical.)
Okay, that’s the most sense I can make of this question at the moment. Hope it’s useful.
September 19, 2013 at 3:37 pm
Hi Tom Hirschowitz,
Jeffrey already said the most important things, so let me just emphasize a couple points.
(1) As Jeffrey mentioned, in the common cases of categorification, the “embedding” is not straightforward. For example, take the case of linear spaces: one starts with the category of linear spaces Vect and notices that, not only it has properties formally similar to that of linear spaces, you can pin-down what those properties are and then define what is a vector 2-space. As a consequence (and a test that the definition is a good one), one then notes that one has a 2-category of 2-vector spaces in which the category Vect plays a similar role that the scalar field plays in the category of linear spaces.
(2) I had a very specific target in mind in writing the paper: to make conceptual sense of the paper by Yetter and the constructions in it. The tack was to concentrate on the “properties formally similar” route and forget about the other parts usually associated to a categorification. In the background, at work is the following, admittedly vague idea: suppose you have some theory T you want to categorify. Categorification, whatever it turns out to be, should be of such a nature that for some statement p of the theory T there should exist a statement (or family of statements) p*, the categorification of p, such that the categorified proof of the proof of p yields a proof of p*. I do not know how to make sense of this (although, the guys working in homotopy type theory can probably tell you something how one goes about doing something like this), so I just took the path that makes the most sense if you have been trained in category-theoretic thinking: follow the universal properties.
(3) Coends appear because just as the integral of function is an extension of the measure (in a certain technical sense explained in the paper), the integral (of a sheaf) is a left Kan extension of the categorified notion of measure (a cosheaf) — the universal properties and constructions involved are even closer than this summary may indicate — and left Kan extensions have a particularly neat expression in terms of coends.
note: if you want to contact me, you can do so at grodrigues dot math at the domain gmail dot com.