John Huerta visited here for about a week earlier this month, and gave a couple of talks. The one I want to write about here was a guest lecture in the topics course Susama Agarwala and I were teaching this past semester. The course was about topics in category theory of interest to geometry, and in the case of this lecture, “geometry” means supergeometry. It follows the approach I mentioned in the previous post about looking at sheaves as a kind of generalized space. The talk was an introduction to a program of seeing supermanifolds as a kind of sheaf on the site of “super-points”. This approach was first proposed by Albert Schwartz, though see, for instance, this review by Christophe Sachse for more about this approach, and this paper (comparing the situation for real and complex (super)manifolds) for more recent work.
It’s amazing how many geometrical techniques can be applied in quite general algebras once they’re formulated correctly. It’s perhaps less amazing for supermanifolds, in which commutativity fails in about the mildest possible way. Essentially, the algebras in question split into bosonic and fermionic parts. Everything in the bosonic part commutes with everything, and the fermionic part commutes “up to a negative sign” within itself.
Supermanifolds
Supermanifolds are geometric objects, which were introduced as a setting on which “supersymmetric” quantum field theories could be defined. Whether or not “real” physics has this symmetry (the evidence is still pending, though ), these are quite nicely behaved theories. (Throwing in extra symmetry assumptions tends to make things nicer, and supersymmetry is in some sense the maximum extra symmetry we might reasonably hope for in a QFT).
Roughly, the idea is that supermanifolds are spaces like manifolds, but with some non-commuting coordinates. Supermanifolds are therefore in some sense “noncommutative spaces”. Noncommutative algebraic or differential geometry start with various dualities to the effect that some category of spaces is equivalent to the opposite of a corresponding category of algebras – for instance, a manifold  corresponds to the
corresponds to the 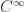 algebra
algebra  . So a generalized category of “spaces” can be found by dropping the “commutative” requirement from that statement. The category
. So a generalized category of “spaces” can be found by dropping the “commutative” requirement from that statement. The category  of supermanifolds only weakens the condition slightly: the algebras are
of supermanifolds only weakens the condition slightly: the algebras are  -graded, and are “supercommutative”, i.e. commute up to a sign which depends on the grading.
-graded, and are “supercommutative”, i.e. commute up to a sign which depends on the grading.
Now, the conventional definition of supermanifolds, as with schemes, is to say that they are spaces equipped with a “structure sheaf” which defines an appropriate class of functions. For ordinary (real) manifolds, this would be the sheaf assigning to an open set 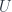 the ring
the ring  of all the smooth real-valued functions. The existence of an atlas of charts for the manifold amounts to saying that the structure sheaf locally looks like
of all the smooth real-valued functions. The existence of an atlas of charts for the manifold amounts to saying that the structure sheaf locally looks like  for some open set
for some open set  . (For fixed dimension
. (For fixed dimension  ).
).
For supermanifolds, the condition on the local rings says that, for fixed dimension  , a
, a  -dimensional supermanifold has structure sheaf in which $they look like
-dimensional supermanifold has structure sheaf in which $they look like

In this, 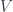 is as above, and the notation
is as above, and the notation

refers to the exterior algebra, which we can think of as polynomials in the  , with the wedge product, which satisfies
, with the wedge product, which satisfies  . The idea is that one is supposed to think of this as the algebra of smooth functions on a space with ordinary dimensions, and
. The idea is that one is supposed to think of this as the algebra of smooth functions on a space with ordinary dimensions, and  “anti-commuting” dimensions with coordinates . The commuting variables, say
“anti-commuting” dimensions with coordinates . The commuting variables, say  , are called “bosonic” or “even”, and the anticommuting ones are “fermionic” or “odd”. (The term “fermionic” is related to the fact that, in quantum mechanics, when building a Hilbert space for a bunch of identical fermions, one takes the antisymmetric part of the tensor product of their individual Hilbert spaces, so that, for instance,
, are called “bosonic” or “even”, and the anticommuting ones are “fermionic” or “odd”. (The term “fermionic” is related to the fact that, in quantum mechanics, when building a Hilbert space for a bunch of identical fermions, one takes the antisymmetric part of the tensor product of their individual Hilbert spaces, so that, for instance,  ).
).
The structure sheaf picture can therefore be thought of as giving an atlas of charts, so that the neighborhoods locally look like “super-domains”, the super-geometry equivalent of open sets .
In fact, there’s a long-known theorem of Batchelor which says that any real supermanifold is given exactly by the algebra of “global sections”, which looks like  . That is, sections in the local rings (“functions on” open neighborhoods of ) always glue together to give a section in
. That is, sections in the local rings (“functions on” open neighborhoods of ) always glue together to give a section in  .
.
Another way to put this is that every supermanifold can be seen as just bundle of exterior algebras. That is, a bundle over a base manifold 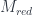 , whose fibres are the “super-points”
, whose fibres are the “super-points” 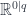 corresponding to
corresponding to  . The base space is called the “reduced” manifold. Any such bundle gives back a supermanifold, where the algebras in the structure sheaf are the algebras of sections of the bundle.
. The base space is called the “reduced” manifold. Any such bundle gives back a supermanifold, where the algebras in the structure sheaf are the algebras of sections of the bundle.
One shouldn’t be too complacent about saying they are exactly the same, though: this correspondence isn’t functorial. That is, the maps between supermanifolds are not just bundle maps. (Also, Batchelor’s theorem works only for real, not for complex, supermanifolds, where only the local neighborhoods necessarily look like such bundles).
Why, by the way, say that is a super “point”, when  is a whole vector space? Since the fermionic variables are anticommuting, no term can have more than one of each , so this is a finite-dimensional algebra. This is unlike
is a whole vector space? Since the fermionic variables are anticommuting, no term can have more than one of each , so this is a finite-dimensional algebra. This is unlike  , which suggests that the noncommutative directions are quite different. Any element of is nilpotent, so if we think of a Taylor series for some function – a power series in the
, which suggests that the noncommutative directions are quite different. Any element of is nilpotent, so if we think of a Taylor series for some function – a power series in the  – we see note that no term has a coefficient for greater than 1, or of degree higher than in all the – so imagines that only infinitesimal behaviour in these directions exists at all. Thus, a supermanifold is like an ordinary -dimensional manifold , built from the ordinary domains , equipped with a bundle whose fibres are a sort of “infinitesimal fuzz” about each point of the “even part” of the supermanifold, described by the .
– we see note that no term has a coefficient for greater than 1, or of degree higher than in all the – so imagines that only infinitesimal behaviour in these directions exists at all. Thus, a supermanifold is like an ordinary -dimensional manifold , built from the ordinary domains , equipped with a bundle whose fibres are a sort of “infinitesimal fuzz” about each point of the “even part” of the supermanifold, described by the .
But this intuition is a bit vague. We can sharpen it a bit using the functor of points approach…
Supermanifolds as Manifold-Valued Sheaves
As with schemes, there is also a point of view that sees supermanifolds as “ordinary” manifolds, constructed in the topos of sheaves over a certain site. The basic insight behind the picture of these spaces, as in the previous post, is based on the fact that the Yoneda lemma lets us think of sheaves as describing all the “probes” of a generalized space (actually an algebra in this case). The “probes” are the objects of a certain category, and are called “superpoints“.
This category is just  , the opposite of the category of Grassman algebras (i.e. exterior algebras) – that is, polynomial algebras in noncommuting variables, like
, the opposite of the category of Grassman algebras (i.e. exterior algebras) – that is, polynomial algebras in noncommuting variables, like  . These objects naturally come with a -grading, which are spanned, respectively, by the monomials with even and odd degree:
. These objects naturally come with a -grading, which are spanned, respectively, by the monomials with even and odd degree:  latex \mathbf{SMan}$ (\Lambda_q)_0 \oplus (\Lambda_q)_1$
latex \mathbf{SMan}$ (\Lambda_q)_0 \oplus (\Lambda_q)_1$

and

This is a -grading since the even ones commute with anything, and the odd ones anti-commute with each other. So if 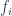 and
and  are homogeneous (live entirely in one grade or the other), then
are homogeneous (live entirely in one grade or the other), then  .
.
The should be thought of as the  -dimensional supermanifold: it looks like a point, with a -dimensional fermionic tangent space (the “infinitesimal fuzz” noted above) attached. The morphisms in
-dimensional supermanifold: it looks like a point, with a -dimensional fermionic tangent space (the “infinitesimal fuzz” noted above) attached. The morphisms in 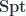 from to $llatex \Lambda_r$ are just the grade-preserving algebra homomorphisms from
from to $llatex \Lambda_r$ are just the grade-preserving algebra homomorphisms from  to . There are quite a few of these: these objects are not terminal objects like the actual point. But this makes them good probes. Thi gets to be a site with the trivial topology, so that all presheaves are sheaves.
to . There are quite a few of these: these objects are not terminal objects like the actual point. But this makes them good probes. Thi gets to be a site with the trivial topology, so that all presheaves are sheaves.
Then, as usual, a presheaf on this category is to be understood as giving, for each object  , the collection of maps from to a space . The case
, the collection of maps from to a space . The case 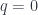 gives the set of points of , and the various other algebras
gives the set of points of , and the various other algebras  give sets of “-points”. This term is based on the analogy that a point of a topological space (or indeed element of a set) is just the same as a map from the terminal object
give sets of “-points”. This term is based on the analogy that a point of a topological space (or indeed element of a set) is just the same as a map from the terminal object  , the one point space (or one element set). Then an “-point” of a space
, the one point space (or one element set). Then an “-point” of a space  is just a map from another object . If is not terminal, this is close to the notion of a “subspace” (though a subspace, strictly, would be a monomorphism from ). These are maps from in , or as algebra maps,
is just a map from another object . If is not terminal, this is close to the notion of a “subspace” (though a subspace, strictly, would be a monomorphism from ). These are maps from in , or as algebra maps,  consists of all the maps
consists of all the maps  .
.
What’s more, since this is a functor, we have to have a system of maps between the . For any algebra maps  , we should get corresponding maps
, we should get corresponding maps  . These are really algebra maps
. These are really algebra maps  , of which there are plenty, all determined by the images of the generators
, of which there are plenty, all determined by the images of the generators  .
.
Now, really, a sheaf on is actually just what we might call a “super-set”, with sets for each  . To make super-manifolds, one wants to say they are “manifold-valued sheaves”. Since manifolds themselves don’t form a topos, one needs to be a bit careful about defining the extra structure which makes a set a manifold.
. To make super-manifolds, one wants to say they are “manifold-valued sheaves”. Since manifolds themselves don’t form a topos, one needs to be a bit careful about defining the extra structure which makes a set a manifold.
Thus, a supermanifold is a manifold constructed in the topos  . That is, must also be equipped with a topology and a collection of charts defining the manifold structure. These are all construed internally using objects and morphisms in the category of sheaves, where charts are based on super-domains, namely those algebras which look like
. That is, must also be equipped with a topology and a collection of charts defining the manifold structure. These are all construed internally using objects and morphisms in the category of sheaves, where charts are based on super-domains, namely those algebras which look like 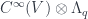 , for an open subset of
, for an open subset of 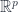 .
.
The reduced manifold which appears in Batchelor’s theorem is the manifold of ordinary points  . That is, it is all the
. That is, it is all the  -points, where is playing the role of functions on the zero-dimensional domain with just one point. All the extra structure in an atlas of charts for all of to make it a supermanifold amounts to putting the structure of ordinary manifolds on the – but in compatible ways.
-points, where is playing the role of functions on the zero-dimensional domain with just one point. All the extra structure in an atlas of charts for all of to make it a supermanifold amounts to putting the structure of ordinary manifolds on the – but in compatible ways.
(Alternatively, we could have described as sheaves in 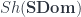 , where
, where  is a site of “superdomains”, and put all the structure defining a manifold into . But working over super-points is preferable for the moment, since it makes it clear that manifolds and supermanifolds are just manifestations of the same basic definition, but realized in two different toposes.)
is a site of “superdomains”, and put all the structure defining a manifold into . But working over super-points is preferable for the moment, since it makes it clear that manifolds and supermanifolds are just manifestations of the same basic definition, but realized in two different toposes.)
The fact that the manifold structure on the must be put on them compatibly means there is a relatively nice way to picture all these spaces.
Values of the Functor of Points as Bundles
The main idea which I find helps to understand the functor of points is that, for every superpoint 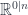 (i.e. for every Grassman algebra
(i.e. for every Grassman algebra  ), one gets a manifold . (Note the convention that is the odd dimension of , and
), one gets a manifold . (Note the convention that is the odd dimension of , and  is the odd dimension of the probe superpoint).
is the odd dimension of the probe superpoint).
Just as every supermanifold is a bundle of superpoints, every manifold is a perfectly conventional vector bundle over the conventional manifold of ordinary points. So for each , we get a bundle,  .
.
Now this manifold, , consists exactly of all the “points” of – this tells us immediately that is not a category of concrete sheaves (in the sense I explained in the previous post). Put another way, it’s not a concrete category – that would mean that there is an underlying set functor, which gives a set for each object, and that morphisms are determined by what they do to underlying sets. Non-concrete categories are, by nature, trickier to understand.
However, the functor of points gives a way to turn the non-concrete into a tower of concrete manifolds , and the morphisms between various amount to compatible towers of maps between the various for each . The fact that the compatibility is controlled by algebra maps explains why this is the same as maps between these bundles of superpoints.
Specifically, then, we have
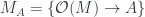
This splits into maps of the even parts, and of the odd parts, where the grassman algebra  has even and odd parts:
has even and odd parts:  , as above. Similarly, splits into odd and even parts, and since the functions on are entirely even, this is:
, as above. Similarly, splits into odd and even parts, and since the functions on are entirely even, this is:

and

Now, the duality of “hom” and tensor means that  , and algebra maps preserve the grading. So we just have tensor products of these with the even and odd parts, respectively, of the probe superpoint. Since the even part
, and algebra maps preserve the grading. So we just have tensor products of these with the even and odd parts, respectively, of the probe superpoint. Since the even part  includes the multiples of the constants, part of this just gives a copy of itself. The remaining part of is nilpotent (since it’s made of even-degree polynomials in the nilpotent , so what we end up with, looking at the bundle over an open neighborhood
includes the multiples of the constants, part of this just gives a copy of itself. The remaining part of is nilpotent (since it’s made of even-degree polynomials in the nilpotent , so what we end up with, looking at the bundle over an open neighborhood  , is:
, is:

The projection map  is the obvious projection onto the first factor. These assemble into a bundle over .
is the obvious projection onto the first factor. These assemble into a bundle over .
We should think of these bundles as “shifting up” the nilpotent part of (which are invisible at the level of ordinary points in ) by the algebra . Writing them this way makes it clear that this is functorial in the superpoints : given choices and 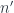 , and any morphism between the corresponding and
, and any morphism between the corresponding and  , it’s easy to see how we get maps between these bundles.
, it’s easy to see how we get maps between these bundles.
Now, maps between supermanifolds are the same thing as natural transformations between the functors of points. These include maps of the base manifolds, along with maps between the total spaces of all these bundles. More, this tower of maps must commute with all those bundle maps coming from algebra maps . (In particular, since 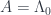 , the ordinary point, is one of these, they have to commute with the projection to .) These conditions may be quite restrictive, but it leaves us with, at least, a quite concrete image of what maps of supermanifolds
, the ordinary point, is one of these, they have to commute with the projection to .) These conditions may be quite restrictive, but it leaves us with, at least, a quite concrete image of what maps of supermanifolds
Super-Poincaré Group
One of the main settings where super-geometry appears is in so-called “supersymmetric” field theories, which is a concept that makes sense when fields live on supermanifolds. Supersymmetry, and symmetries associated to super-Lie groups, is exactly the kind of thing that John has worked on. A super-Lie group, of course, is a supermanifold that has the structure of a group (i.e. it’s a Lie group in the topos of presheaves over the site of super-points – so the discussion above means it can be thought of as a big tower of Lie groups, all bundles over a Lie group  ).
).
In fact, John has mostly worked with super-Lie algebras (and the connection between these and division algebras, though that’s another story). These are -graded algebras with a Lie bracket whose commutation properties are the graded version of those for an ordinary Lie algebra. But part of the value of the framework above is that we can simply borrow results from Lie theory for manifolds, import it into the new topos  , and know at once that super-Lie algebras integrate up to super-Lie groups in just the same way that happens in the old topos (of sets).
, and know at once that super-Lie algebras integrate up to super-Lie groups in just the same way that happens in the old topos (of sets).
Supersymmetry refers to a particular example, namely the “super-Poincaré group”. Just as the Poincaré group is the symmetry group of Minkowski space, a 4-manifold with a certain metric on it, the super-Poincaré group has the same relation to a certain supermanifold. (There are actually a few different versions, depending on the odd dimension.) The algebra is generated by infinitesimal translations and boosts, plus some “translations” in fermionic directions, which generate the odd part of the algebra.
Now, symmetry in a quantum theory means that this algebra (or, on integration, the corresponding group) acts on the Hilbert space 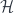 of possible states of the theory: that is, the space of states is actually a representation of this algebra. In fact, to make sense of this, we need a super-Hilbert space (i.e. a graded one). The even generators of the algebra then produce grade-preserving self-maps of , and the odd generators produce grade-reversing ones. (This fact that there are symmetries which flip the “bosonic” and “fermionic” parts of the total is why supersymmetric theories have “superpartners” for each particle, with the opposite parity, since particles are labelled by irreducible representations of the Poincaré group and the gauge group).
of possible states of the theory: that is, the space of states is actually a representation of this algebra. In fact, to make sense of this, we need a super-Hilbert space (i.e. a graded one). The even generators of the algebra then produce grade-preserving self-maps of , and the odd generators produce grade-reversing ones. (This fact that there are symmetries which flip the “bosonic” and “fermionic” parts of the total is why supersymmetric theories have “superpartners” for each particle, with the opposite parity, since particles are labelled by irreducible representations of the Poincaré group and the gauge group).
To date, so far as I know, there’s no conclusive empirical evidence that real quantum field theories actually exhibit supersymmetry, such as detecting actual super-partners for known particles. Even if not, however, it still has some use as a way of developing toy models of quite complicated theories which are more tractable than one might expect, precisely because they have lots of symmetry. It’s somewhat like how it’s much easier to study computationally difficult theories like gravity by assuming, for instance, spherical symmetry as an extra assumption. In any case, from a mathematician’s point of view, this sort of symmetry is just a particularly simple case of symmetries for theories which live on noncommutative backgrounds, which is quite an interesting topic in its own right. As usual, physics generates lots of math which remains both true and interesting whether or not it applies in the way it was originally suggested.
In any case, what the functor-of-points viewpoint suggests is that ordinary and super- symmetries are just two special cases of “symmetries of a field theory” in two different toposes. Understanding these and other examples from this point of view seems to give a different understanding of what “symmetry”, one of the most fundamental yet slippery concepts in mathematics and science, actually means.
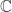


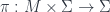
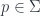
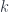

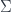
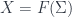
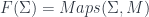

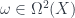

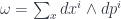
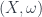
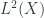


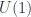
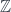 -graded group: that is, a tower of groups of “cocycles”, one group for each
-graded group: that is, a tower of groups of “cocycles”, one group for each 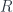 is a cohomology theory, it can be “twisted” over
is a cohomology theory, it can be “twisted” over  into the “
into the “ “… and yet there aren’t all that many examples, and very few large ones, known.
“… and yet there aren’t all that many examples, and very few large ones, known.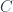 acted on by a group
acted on by a group 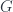 is supposed to be a generalization of the notion of the set of fixed points for a group acting on a set. The category
is supposed to be a generalization of the notion of the set of fixed points for a group acting on a set. The category 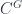 has objects which consist of an object
has objects which consist of an object 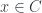 which is fixed by the action of
which is fixed by the action of 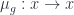 for each
for each  , satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in
, satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in  for some group
for some group 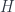 ) – or a weakened version of such a thing (it’s Morita equivalent to ).
) – or a weakened version of such a thing (it’s Morita equivalent to ).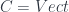 , then
, then 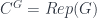 (in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in
(in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in  , we get an adjoint pair of functors between
, we get an adjoint pair of functors between 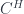 , which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a
, which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a  . The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.
. The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.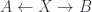
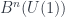 , the classifying space for
, the classifying space for  -gerbes. That is, we don’t just have these “spaces”, but these spaces equipped with one of those pieces of cohomological twisting data discussed up above. That enters the quantization like an action (it’s WHAT you integrate in a path integral).
-gerbes. That is, we don’t just have these “spaces”, but these spaces equipped with one of those pieces of cohomological twisting data discussed up above. That enters the quantization like an action (it’s WHAT you integrate in a path integral). -rings.
-rings. which have all the properties of the category of Sets which make it useful for doing most of ordinary mathematics. Thus, a topos in this sense is a category with a bunch of properties – there are various equivalent definitions, but for example, toposes have all finite limits (in particular, products), and all colimits.
which have all the properties of the category of Sets which make it useful for doing most of ordinary mathematics. Thus, a topos in this sense is a category with a bunch of properties – there are various equivalent definitions, but for example, toposes have all finite limits (in particular, products), and all colimits. are objects of
are objects of  , with an “evaluation map”
, with an “evaluation map” 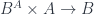 , which makes it possible to think of
, which makes it possible to think of  is an equivalence class of monomorphisms into
is an equivalence class of monomorphisms into 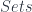 , whose elements we can tall “true” and “false”. Then every subset of
, whose elements we can tall “true” and “false”. Then every subset of 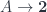 . In general, a subobject classifies is an object
. In general, a subobject classifies is an object  together with a map from the terminal object,
together with a map from the terminal object, 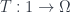 , such that every inclusion of subobject is a pullback of
, such that every inclusion of subobject is a pullback of 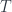 along a characteristic function.
along a characteristic function.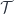 together with a “topology”
together with a “topology” 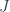 , which is a rule which, for each
, which is a rule which, for each  , picks out
, picks out  , a set of collections of maps into
, a set of collections of maps into 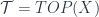 . Given a topological space,
. Given a topological space,  is the category whose objects are the open sets
is the category whose objects are the open sets 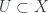 , and the morphisms are all the inclusions. Then that each collection in
, and the morphisms are all the inclusions. Then that each collection in 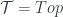 , the category of topological spaces, the usual choice of
, the category of topological spaces, the usual choice of  . That is, it’s a way of assigning a set to each
. That is, it’s a way of assigning a set to each  , which assigns to each open set
, which assigns to each open set  , which assigns the set of all continuous functions.
, which assigns the set of all continuous functions.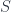 which are sheaves – namely, those which satisfy some “gluing” conditions. Thus, suppose we’re, given an open cover
which are sheaves – namely, those which satisfy some “gluing” conditions. Thus, suppose we’re, given an open cover  , and a choice of one element
, and a choice of one element 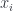 from each
from each  , which form a “matching family” in the sense that they agree when restricted to any overlaps. Then the sheaf condition says that there’s a unique “amalgamation” of this family – that is, one element
, which form a “matching family” in the sense that they agree when restricted to any overlaps. Then the sheaf condition says that there’s a unique “amalgamation” of this family – that is, one element 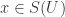 which restricts to all the
which restricts to all the  .
.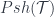 . Namely, the objects appear as the representable presheaves,
. Namely, the objects appear as the representable presheaves,  , and the morphisms
, and the morphisms  show up as the induced natural transformations between these functors. This map
show up as the induced natural transformations between these functors. This map  is called the Yoneda embedding. If
is called the Yoneda embedding. If 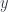 lands in
lands in  .
. , and any
, and any 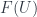 is naturally isomorphic to
is naturally isomorphic to 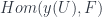 : that is,
: that is,  , for all choices of
, for all choices of  . Given a nontrivial bundle
. Given a nontrivial bundle  , there is a sheaf of sections – on each
, there is a sheaf of sections – on each  to be all the one-sided inverses
to be all the one-sided inverses  which are one-sided inverses of
which are one-sided inverses of 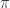 . For a generic sheaf, we can imagine a sort of “generalized bundle” over
. For a generic sheaf, we can imagine a sort of “generalized bundle” over  – so it consists of a “blue” copy of X and a “green” copy of X, but the underlying set functor ignores the colouring.
– so it consists of a “blue” copy of X and a “green” copy of X, but the underlying set functor ignores the colouring.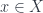 where they are – they form the stabilizer subgroup
where they are – they form the stabilizer subgroup 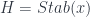 . When the space is homogeneous, it is isomorphic to the coset space,
. When the space is homogeneous, it is isomorphic to the coset space, 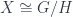 . So Klein’s idea is to say that any time you have a Lie group
. So Klein’s idea is to say that any time you have a Lie group 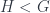 , this quotient will be called a “homogeneous space”. A familiar example would be Euclidean space,
, this quotient will be called a “homogeneous space”. A familiar example would be Euclidean space,  , where
, where 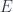 is the Euclidean group and
is the Euclidean group and 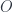 is the orthogonal group, but there are plenty of others.
is the orthogonal group, but there are plenty of others.![Imm(-,N) : [Spaces] \rightarrow [Spaces]](https://s0.wp.com/latex.php?latex=Imm%28-%2CN%29+%3A+%5BSpaces%5D+%5Crightarrow+%5BSpaces%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
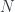 . Given a manifold
. Given a manifold 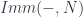 means, among other things, looking at the various spaces
means, among other things, looking at the various spaces  of immersions of each
of immersions of each 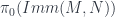 nonempty?
nonempty? is at least
is at least  , then there is an embedding of
, then there is an embedding of 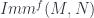 . It consists of all
. It consists of all 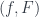 , where
, where 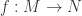 is smooth, and
is smooth, and  is a map of tangent spaces which restricts to
is a map of tangent spaces which restricts to  , and is injective. These are “formally” like immersions, and indeed
, and is injective. These are “formally” like immersions, and indeed  . (This “homotopy” of functors makes sense because we’re talking about an enriched functor – the source and target categories are enriched in spaces, where the concepts of homotopy theory are all available).
. (This “homotopy” of functors makes sense because we’re talking about an enriched functor – the source and target categories are enriched in spaces, where the concepts of homotopy theory are all available). -dimensional manifolds and whose morphisms are embeddings (which, of course, are necessarily codimension 0). Now, the point here is that if
-dimensional manifolds and whose morphisms are embeddings (which, of course, are necessarily codimension 0). Now, the point here is that if  is an embedding in
is an embedding in  has an immersion into
has an immersion into ![Imm(-,N) : \mathcal{E}^{op} \rightarrow [Spaces]](https://s0.wp.com/latex.php?latex=Imm%28-%2CN%29+%3A+%5Cmathcal%7BE%7D%5E%7Bop%7D+%5Crightarrow+%5BSpaces%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
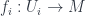 such that the union of all the images
such that the union of all the images 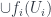 is just
is just 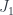 , because it has the property that given any open cover and choice of 1 point in
, because it has the property that given any open cover and choice of 1 point in  of the cover.
of the cover. only allows those covers with the property that given any choice of
only allows those covers with the property that given any choice of 
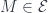 , and a cover, there’s a diagram consisting of the inclusions of all the double-overlaps of sets in the cover into the original sets. Then the descent condition for sheaves of spaces is that
, and a cover, there’s a diagram consisting of the inclusions of all the double-overlaps of sets in the cover into the original sets. Then the descent condition for sheaves of spaces is that into $latex PSh( \mathcal{E} )$. The reflection has a left adjoint,
into $latex PSh( \mathcal{E} )$. The reflection has a left adjoint,  to a sheaf which is the “best approximation” to it. It’s the fact this is an adjoint which makes the inclusion “reflective”, and provides the sense in which the sheafification is an approximation to the original functor.
to a sheaf which is the “best approximation” to it. It’s the fact this is an adjoint which makes the inclusion “reflective”, and provides the sense in which the sheafification is an approximation to the original functor.
 is the intersection of two sets in a cover, and the maps here are the inclusions of that intersection). This and the various other diagrams involving these inclusions are special, given the topology
is the intersection of two sets in a cover, and the maps here are the inclusions of that intersection). This and the various other diagrams involving these inclusions are special, given the topology 
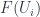 and
and  on the overlap to get one on the union. That is,
on the overlap to get one on the union. That is,  is a colimit of the diagram above (intuitively, by “gluing on the overlap”). In a presheaf, it would come equipped with some maps into the
is a colimit of the diagram above (intuitively, by “gluing on the overlap”). In a presheaf, it would come equipped with some maps into the  which does this, essentially by taking all these colimits. More accurately, since these sheaves are valued in spaces, what we really want are homotopy sheaves, where we can replace “colimit” with “homotopy colimit” in the above – which satisfies a universal property only up to homotopy, and which has a slightly weaker notion of “gluing”. This (homotopy) sheaf is called
which does this, essentially by taking all these colimits. More accurately, since these sheaves are valued in spaces, what we really want are homotopy sheaves, where we can replace “colimit” with “homotopy colimit” in the above – which satisfies a universal property only up to homotopy, and which has a slightly weaker notion of “gluing”. This (homotopy) sheaf is called  . Whichever functor we use, we get a tower of functors connected by natural transformations:
. Whichever functor we use, we get a tower of functors connected by natural transformations:
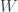 which has higher dimension. Then there’s an orthogonal projection onto the smaller space, which is an adjoint (as a map of inner product spaces) to the inclusion – so these are like our reflective inclusions. So the smaller space can “reflect” the bigger one, while not being able to capture anything in the orthogonal complement. Now suppose we have a tower of inclusions
which has higher dimension. Then there’s an orthogonal projection onto the smaller space, which is an adjoint (as a map of inner product spaces) to the inclusion – so these are like our reflective inclusions. So the smaller space can “reflect” the bigger one, while not being able to capture anything in the orthogonal complement. Now suppose we have a tower of inclusions  , where each space is of higher dimension, such that each of the
, where each space is of higher dimension, such that each of the  , we can take a sequence of approximations
, we can take a sequence of approximations  in the
in the  was “nice” to begin with, this series of approximations will eventually at least converge to it – but it may be that our tower of
was “nice” to begin with, this series of approximations will eventually at least converge to it – but it may be that our tower of  . So the point is, functors satisfying the axioms of a generalized cohomology theory are represented by spectra, whereas
. So the point is, functors satisfying the axioms of a generalized cohomology theory are represented by spectra, whereas  , the classifying space of a group, and we drop the requirement that the map be an immersion, then we’re looking at the functor that gives the moduli space of
, the classifying space of a group, and we drop the requirement that the map be an immersion, then we’re looking at the functor that gives the moduli space of  of diffeological spaces as a setting for homotopy theory. Just to make things scan more nicely, I’m going to say “smooth space” for “diffeological space” here, although this term is in fact ambiguous (see Andrew Stacey’s “
of diffeological spaces as a setting for homotopy theory. Just to make things scan more nicely, I’m going to say “smooth space” for “diffeological space” here, although this term is in fact ambiguous (see Andrew Stacey’s “ ).
). , the space of all maps of the circle into
, the space of all maps of the circle into  can even be defined. Likewise, the irrational torus is hard to talk about as a manifold: you take a torus, thought of as
can even be defined. Likewise, the irrational torus is hard to talk about as a manifold: you take a torus, thought of as  . Then take a direction in
. Then take a direction in  with irrational slope, and identify any two points which are translates of each other in
with irrational slope, and identify any two points which are translates of each other in  (of “plots”) for every n and open
(of “plots”) for every n and open  such that:
such that: is a plot, and
is a plot, and  is a smooth map,
is a smooth map, 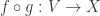 is a plot
is a plot is an open cover of
is an open cover of  is a map, whose restrictions
is a map, whose restrictions  are all plots, so is
are all plots, so is ![I= [0,1]](https://s0.wp.com/latex.php?latex=I%3D+%5B0%2C1%5D&bg=ffffff&fg=29303b&s=0&c=20201002) which passes through them must stop at that point (have derivative zero – or higher derivatives, if you like). Along the same lines, there’s a nonstandard diffeology on
which passes through them must stop at that point (have derivative zero – or higher derivatives, if you like). Along the same lines, there’s a nonstandard diffeology on  itself with the property that any smooth map from this
itself with the property that any smooth map from this  from the terminal object, so that any monomorphism (subobject)
from the terminal object, so that any monomorphism (subobject)  is the pullback of
is the pullback of  along some map
along some map  (the classifying map). In the topos of sets, this is just the inclusion of a one-element set
(the classifying map). In the topos of sets, this is just the inclusion of a one-element set  into a two-element set
into a two-element set  : the classifying map for a subset
: the classifying map for a subset  sends everything in
sends everything in  , and everything else to
, and everything else to  of a pointed space. It’s a theorem by Dan and Enxin that several possible ways of doing this are equivalent. But, for example, Iglesias-Zimmour defines them inductively, so that
of a pointed space. It’s a theorem by Dan and Enxin that several possible ways of doing this are equivalent. But, for example, Iglesias-Zimmour defines them inductively, so that 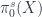 is the set of path-components of
is the set of path-components of 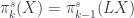 is defined recursively using loop spaces, mentioned above. The point is that this all works in
is defined recursively using loop spaces, mentioned above. The point is that this all works in  for standard theorems like the
for standard theorems like the  , but saying a diffeological bundle is “locally trivial” doesn’t mean “over open neighborhoods”, but “under pullback along any plot”. (Either of these converts a bundle over a whole space into a bundle over part of
, but saying a diffeological bundle is “locally trivial” doesn’t mean “over open neighborhoods”, but “under pullback along any plot”. (Either of these converts a bundle over a whole space into a bundle over part of  , these classes have to satisfy some axioms (including an abstract form of the lifting properties). There are slightly different formulations, but for instance, the “2 of 3” axiom says that if two of
, these classes have to satisfy some axioms (including an abstract form of the lifting properties). There are slightly different formulations, but for instance, the “2 of 3” axiom says that if two of 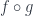 are weak equivalences, so is the third. Or, again, there should be a factorization for any morphism into a fibration and an acyclic cofibration (i.e. one which is also a weak equivalence), and also vice versa (that is, moving the adjective “acyclic” to the fibration). Defining some classes of maps isn’t hard, but it tends to be that proving they satisfy all the axioms IS hard.
are weak equivalences, so is the third. Or, again, there should be a factorization for any morphism into a fibration and an acyclic cofibration (i.e. one which is also a weak equivalence), and also vice versa (that is, moving the adjective “acyclic” to the fibration). Defining some classes of maps isn’t hard, but it tends to be that proving they satisfy all the axioms IS hard. itself – only in the larger setting
itself – only in the larger setting 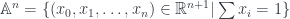 . These aren’t literally simplexes: they’re affine planes, which we understand as smooth spaces – with the subspace diffeology from
. These aren’t literally simplexes: they’re affine planes, which we understand as smooth spaces – with the subspace diffeology from  . But they behave like simplexes: there are face and degeneracy maps for them, and the like. They form a “cosimplicial object”, which we can think of as a functor
. But they behave like simplexes: there are face and degeneracy maps for them, and the like. They form a “cosimplicial object”, which we can think of as a functor  , where
, where 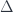 is the
is the  : it’s a simplicial set where the sets are sets of smooth maps from the affine simplex into
: it’s a simplicial set where the sets are sets of smooth maps from the affine simplex into  . These give two functors
. These give two functors  and
and  is the left adjoint). And then, weak equivalences and fibrations being defined in simplicial sets (w.e. are homotopy equivalences of the realization in
is the left adjoint). And then, weak equivalences and fibrations being defined in simplicial sets (w.e. are homotopy equivalences of the realization in  – the space is a space of cosets, and
– the space is a space of cosets, and 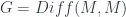 , the space of diffeomorphisms from
, the space of diffeomorphisms from  , and its left adjoint, the “discrete space” functor
, and its left adjoint, the “discrete space” functor  (left adjoint since set maps from
(left adjoint since set maps from 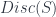 – it’s easy for maps out of
– it’s easy for maps out of 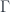 , the “set of global sections” functor), essentially because
, the “set of global sections” functor), essentially because 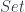 is the topos of sheaves on a single point, and there’s a terminal map from any site into the point. So this adjoint pair is the “terminal geometric morphism” into
is the topos of sheaves on a single point, and there’s a terminal map from any site into the point. So this adjoint pair is the “terminal geometric morphism” into  , where
, where  has only
has only  as its open sets. In
as its open sets. In  itself has a left adjoint,
itself has a left adjoint,  , which gives the set of connected components of a space.
, which gives the set of connected components of a space.  is another kind of “underlying set” of a space. So we call a topos
is another kind of “underlying set” of a space. So we call a topos  is mono: roughly, we can characterize the morphisms of
is mono: roughly, we can characterize the morphisms of  playing the role of
playing the role of  functor replaced by
functor replaced by  , something which, implicitly, gives all the homotopy groups of
, something which, implicitly, gives all the homotopy groups of 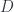 , we can talk about a cube of different structures that live over it, starting with presheaves:
, we can talk about a cube of different structures that live over it, starting with presheaves:  . We can add different modifiers to this: the sheaf condition; the adjective “concrete”; the adjective “simplicial”. Various combinations of these adjectives (e.g.
. We can add different modifiers to this: the sheaf condition; the adjective “concrete”; the adjective “simplicial”. Various combinations of these adjectives (e.g. 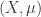 . That is, spaces like
. That is, spaces like  or
or  . The reason for this is that the
. The reason for this is that the  , where “functions” take values in Hilbert spaces.
, where “functions” take values in Hilbert spaces. for some natural number
for some natural number  in the discrete world. It just gives the space of measurable sections (taken up to almost-everywhere equivalence, as usual). This was the main focus of Gonçalo’s talk.
in the discrete world. It just gives the space of measurable sections (taken up to almost-everywhere equivalence, as usual). This was the main focus of Gonçalo’s talk. or any other KV 2-vector space. Actually, it is both a product and a coproduct (
or any other KV 2-vector space. Actually, it is both a product and a coproduct ( does not have all limits and colimits
does not have all limits and colimits , whose objects are Banach spaces and whose maps are (linear) contractions. A Banach Category is a category enriched in
, whose objects are Banach spaces and whose maps are (linear) contractions. A Banach Category is a category enriched in 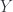 are quasicomplements if they intersect only at zero, and their sum is dense in the whole space), and it’s quite possible to have subspaces which don’t have one. Other unpleasant properties abound.
are quasicomplements if they intersect only at zero, and their sum is dense in the whole space), and it’s quite possible to have subspaces which don’t have one. Other unpleasant properties abound.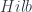 . (So we follow the general dictum that it’s better to have a nice category with bad objects than a bad category with nice objects – the same motivation behind “smooth spaces” instead of manifolds, and the like.) It’s complete and cocomplete (i.e. has all limits and colimits), as well as monoidal closed – for Banach spaces
. (So we follow the general dictum that it’s better to have a nice category with bad objects than a bad category with nice objects – the same motivation behind “smooth spaces” instead of manifolds, and the like.) It’s complete and cocomplete (i.e. has all limits and colimits), as well as monoidal closed – for Banach spaces  is also in
is also in  and
and  both have the same underlying vector space
both have the same underlying vector space  , but the norms are different. For Hilbert spaces, the inner product comes from the Pythagorean formula in either case, but for Banach spaces, the coproduct gets the sum of the two norms, and the product gets the supremum. It turns out that coproducts are the more important concept, and this is where the direct integral comes in.
, but the norms are different. For Hilbert spaces, the inner product comes from the Pythagorean formula in either case, but for Banach spaces, the coproduct gets the sum of the two norms, and the product gets the supremum. It turns out that coproducts are the more important concept, and this is where the direct integral comes in.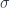 -algebra of measurable sets for some measure space, though it’s important that it needn’t have any actual points (this is a notion of measure space akin to the notion of locale in the topological world). This part of the theory isn’t categorified (arguably a limitation of this approach, but not one that’s any different from Yetter’s). Instead, we categorify the definition of measure itself.
-algebra of measurable sets for some measure space, though it’s important that it needn’t have any actual points (this is a notion of measure space akin to the notion of locale in the topological world). This part of the theory isn’t categorified (arguably a limitation of this approach, but not one that’s any different from Yetter’s). Instead, we categorify the definition of measure itself. – it assigns a number to each measurable set. The pair
– it assigns a number to each measurable set. The pair  is a measure algebra, and relates to a measure space the way a locale relates to a topological space. So a categorified measure
is a measure algebra, and relates to a measure space the way a locale relates to a topological space. So a categorified measure  should be a functor from
should be a functor from 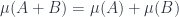 , for disjoint sets, where
, for disjoint sets, where  is the union), so also the categorical measure
is the union), so also the categorical measure  , then
, then  also.
also.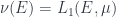 : the Banach space associated to a measurable set
: the Banach space associated to a measurable set  . But there are lots of examples that aren’t like this.
. But there are lots of examples that aren’t like this.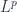 spaces based on the convergence of various integrals. Something similar happens here.
spaces based on the convergence of various integrals. Something similar happens here.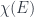 for a measurable set
for a measurable set  might be easiest to visualize in terms of a characteristic bundle, which just puts a copy of the base field (we’ve been assuming it’s
might be easiest to visualize in terms of a characteristic bundle, which just puts a copy of the base field (we’ve been assuming it’s 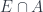 . In particular, the functor
. In particular, the functor  which picks out all the (measurable) bounded sections is a universal way to do this.
which picks out all the (measurable) bounded sections is a universal way to do this. , taking a set to its characteristic sheaf. Given a measure valued in some Banach category,
, taking a set to its characteristic sheaf. Given a measure valued in some Banach category,  , we can find the left Kan extension
, we can find the left Kan extension  , such that
, such that 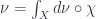 . The Kan extension is a universal way to extend
. The Kan extension is a universal way to extend 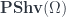 so that this is true, and it can be calculated as a colimit.
so that this is true, and it can be calculated as a colimit. , and get the Fubini theorem, for instance: there is a canonical equivalence (no longer isomorphism) between (a suitable) tensor product of
, and get the Fubini theorem, for instance: there is a canonical equivalence (no longer isomorphism) between (a suitable) tensor product of 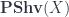 and
and  on one hand, and on the other
on one hand, and on the other 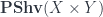 . Doing integration, one can then do all the usual things – exchange order of integration between
. Doing integration, one can then do all the usual things – exchange order of integration between 