Well, it’s been a while, but it’s now a new semester here in Hamburg, and I wanted to go back and look at some of what we talked about in last semester’s research seminar. This semester, Susama Agarwala and I are sharing the teaching in a topics class on “Category Theory for Geometry“, in which I’ll be talking about categories of sheaves, and building up the technology for Susama to talk about Voevodsky’s theory of motives (enough to give a starting point to read something like this).
As for last semester’s seminar, one of the two main threads, the one which Alessandro Valentino and I helped to organize, was a look at some of the material needed to approach Jacob Lurie’s paper on the classification of topological quantum field theories. The idea was for the research seminar to present the basic tools that are used in that paper to a larger audience, mostly of graduate students – enough to give a fairly precise statement, and develop the tools needed to follow the proof. (By the way, for a nice and lengthier discussion by Chris Schommer-Pries about this subject, which includes more details on much of what’s in this post, check out this video.)
So: the key result is a slightly generalized form of the Cobordism Hypothesis.
Cobordism Hypothesis
The sort of theory which the paper classifies are those which “extend down to a point”. So what does this mean? A topological field theory can be seen as a sort of “quantum field theory up to homotopy”, which abstract away any geometric information about the underlying space where the fields live – their local degrees of freedom. We do this by looking only at the classes of fields up to the diffeomorphism symmetries of the space. The local, geometric, information gets thrown away by taking this quotient of the space of solutions.
In spite of reducing the space of fields this way, we want to capture the intuition that the theory is still somehow “local”, in that we can cut up spaces into parts and make sense of the theory on those parts separately, and determine what it does on a larger space by gluing pieces together, rather than somehow having to take account of the entire space at once, indissolubly. This reasoning should apply to the highest-dimensional space, but also to boundaries, and to any figures we draw on boundaries when cutting them up in turn.
Carrying this on to the logical end point, this means that a topological quantum field theory in the fully extended sense should assign some sort of data to every geometric entity from a zero-dimensional point up to an  -dimensional cobordism. This is all expressed by saying it’s an -functor:
-dimensional cobordism. This is all expressed by saying it’s an -functor:
 .
.
Well, once we know what this means, we’ll know (in principle) what a TQFT is. It’s less important, for the purposes of Lurie’s paper, what 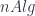 is than what
is than what  is. The reason is that we want to classify these field theories (i.e. functors). It will turn out that
is. The reason is that we want to classify these field theories (i.e. functors). It will turn out that  has the sort of structure that makes it easy to classify the functors out of it into any target -category
has the sort of structure that makes it easy to classify the functors out of it into any target -category  . A guess about what kind of structure is actually there was expressed by Baez and Dolan as the Cobordism Hypothesis. It’s been slightly rephrased from the original form to get a form which has a proof. The version Lurie proves says:
. A guess about what kind of structure is actually there was expressed by Baez and Dolan as the Cobordism Hypothesis. It’s been slightly rephrased from the original form to get a form which has a proof. The version Lurie proves says:
The  -category
-category 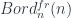 is equivalent to the free symmetric monoidal -category generated by one fully-dualizable object.
is equivalent to the free symmetric monoidal -category generated by one fully-dualizable object.
The basic point is that, since is a free structure, the classification means that the extended TQFT’s amount precisely to the choice of a fully-dualizable object of (which includes a choice of a bunch of morphisms exhibiting the “dualizability”). However, to make sense of this, we need to have a suitable idea of an -category, and know what a fully dualizable object is. Let’s begin with the first.
-Categories
In one sense, the Cobordism Hypothesis, which was originally made about -categories at a time when these were only beginning to be defined, could be taken as a criterion for an acceptable definition. That is, it expressed an intuition which was important enough that any definition which wouldn’t allow one to prove the Cobordism Hypothesis in some form ought to be rejected. To really make it work, one had to bring in the “infinity” part of -categories. The point here is that we are talking about category-like structures which have morphisms between objects, 2-morphisms between morphisms, and so on, with 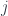 -morphisms between
-morphisms between  -morphisms for every possible degree. The inspiration for this comes from homotopy theory, where one has maps, homotopies of maps, homotopies of homotopies, etc.
-morphisms for every possible degree. The inspiration for this comes from homotopy theory, where one has maps, homotopies of maps, homotopies of homotopies, etc.
Nowadays, there are several possible concrete models for -categories (see this survey article by Julie Bergner for a summary of four of them). They are all equivalent definitions, in a suitable up-to-homotopy way, but for purposes of the proof, Lurie is taking the definition that an -category is an n-fold complete Segal space. One theme that shows up in all the definitions is that of simplicial methods. (In our seminar, we started with a series of two talks introducing the notions of simplicial sets, simplicial objects in a category, and Kan complexes. If you don’t already know this, essentially everything we need is nicely explained in here.)
One of the underlying ideas is that a category 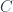 can be associated with a simplicial set, its nerve
can be associated with a simplicial set, its nerve  , where the set
, where the set 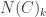 of
of 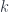 -dimensional simplexes is just the set of composable -tuples of morphisms in . If is a groupoid (everything is invertible), then the simplicial set is a Kan complex – it satisfies some filling conditions, which ensure that any morphism has an inverse. Not every Kan complex is the nerve of a groupoid, but one can think of them as weak versions of groupoids –
-dimensional simplexes is just the set of composable -tuples of morphisms in . If is a groupoid (everything is invertible), then the simplicial set is a Kan complex – it satisfies some filling conditions, which ensure that any morphism has an inverse. Not every Kan complex is the nerve of a groupoid, but one can think of them as weak versions of groupoids – 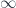 -groupoids, or
-groupoids, or 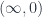 -categories – where the higher morphisms may not be completely trivial (as with a groupoid), but where at least they’re all invertible. This leads to another desirable feature in any definition of -category, which is the Homotopy Hypothesis: that the
-categories – where the higher morphisms may not be completely trivial (as with a groupoid), but where at least they’re all invertible. This leads to another desirable feature in any definition of -category, which is the Homotopy Hypothesis: that the  -category of -categories, also called -groupoids, should be equivalent (in the same weak sense) to a category of Hausdorff spaces with some other nice properties, which we call
-category of -categories, also called -groupoids, should be equivalent (in the same weak sense) to a category of Hausdorff spaces with some other nice properties, which we call  for short. This is true of Kan complexes.
for short. This is true of Kan complexes.
Thus, up to homotopy, specifying an -groupoid is the same as specifying a space.
The data which defines a Segal space (which was however first explicitly defined by Charlez Rezk) is a simplicial space  : for each , there are spaces
: for each , there are spaces 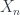 , thought of as the space of composable -tuples of morphisms. To keep things tame, we suppose that
, thought of as the space of composable -tuples of morphisms. To keep things tame, we suppose that  , the space of objects, is discrete – that is, we have only a set of objects. Being a simplicial space means that the come equipped with a collection of face maps
, the space of objects, is discrete – that is, we have only a set of objects. Being a simplicial space means that the come equipped with a collection of face maps 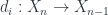 , which we should think of as compositions: to get from an -tuple to an
, which we should think of as compositions: to get from an -tuple to an  -tuple of morphisms, one can compose two morphisms together at any of positions in the tuple.
-tuple of morphisms, one can compose two morphisms together at any of positions in the tuple.
One condition which a simplicial space has to satisfy to be a Segal space has to do with the “weakening” which makes a Segal space a weaker notion than just a category lies in the fact that the cannot be arbitrary, but must be homotopy equivalent to the “actual” space of -tuples, which is a strict pullback  . That is, in a Segal space, the pullback which defines these tuples for a category is weakened to be a homotopy pullback. Combining this with the various face maps, we therefore get a weakened notion of composition:
. That is, in a Segal space, the pullback which defines these tuples for a category is weakened to be a homotopy pullback. Combining this with the various face maps, we therefore get a weakened notion of composition:  . Because we start by replacing the space of -tuples with the homotopy-equivalent , the composition rule will only satisfy all the relations which define composition (associativity, for instance) up to homotopy.
. Because we start by replacing the space of -tuples with the homotopy-equivalent , the composition rule will only satisfy all the relations which define composition (associativity, for instance) up to homotopy.
To be complete, the Segal space must have a notion of equivalence for which agrees with that for Kan complexes seen as -groupoids. In particular, there is a sub-simplicial object 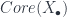 , which we understand to consist of the spaces of invertible -morphisms. Since there should be nothing interesting happening above the top dimension, we ask that, for these spaces, the face and degeneracy maps are all homotopy equivalences: up to homotopy, the space of invertible higher morphisms has no new information.
, which we understand to consist of the spaces of invertible -morphisms. Since there should be nothing interesting happening above the top dimension, we ask that, for these spaces, the face and degeneracy maps are all homotopy equivalences: up to homotopy, the space of invertible higher morphisms has no new information.
Then, an -fold complete Segal space is defined recursively, just as one might define -categories (without the infinitely many layers of invertible morphisms “at the top”). In that case, we might say that a double category is just a category internal to 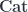 : it has a category of objects, and a category of morphims, and the various maps and operations, such as composition, which make up the definition of a category are all defined as functors. That turns out to be the same as a structure with objects, horizontal and vertical morphisms, and square-shaped 2-cells. If we insist that the category of objects is discrete (i.e. really just a set, with no interesting morphisms), then the result amounts to a 2-category. Then we can define a 3-category to be a category internal to
: it has a category of objects, and a category of morphims, and the various maps and operations, such as composition, which make up the definition of a category are all defined as functors. That turns out to be the same as a structure with objects, horizontal and vertical morphisms, and square-shaped 2-cells. If we insist that the category of objects is discrete (i.e. really just a set, with no interesting morphisms), then the result amounts to a 2-category. Then we can define a 3-category to be a category internal to 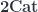 (whose 2-category of objects is discrete), and so on. This approach really defines an -fold category (see e.g. Chapter 5 of Cheng and Lauda to see a variation of this approach, due to Tamsamani and Simpson), but imposing the condition that the objects really amount to a set at each step gives exactly the usual intuition of a (strict!) -category.
(whose 2-category of objects is discrete), and so on. This approach really defines an -fold category (see e.g. Chapter 5 of Cheng and Lauda to see a variation of this approach, due to Tamsamani and Simpson), but imposing the condition that the objects really amount to a set at each step gives exactly the usual intuition of a (strict!) -category.
This is exactly the approach we take with -fold complete Segal spaces, except that some degree of weakness is automatic. Since a C.S.S. is a simplicial object with some properties (we separately define objects of -tuples of morphisms for every , and all the various composition operations), the same recursive approach leads to a definition of an “-fold complete Segal space” as simply a simplicial object in -fold C.S.S.’s (with the same properties), such that the objects form a set. In principle, this gives a big class of “spaces of morphisms” one needs to define – one for every -fold product of simplexes of any dimension – but all those requirements that any space of objects “is just a set” (i.e. is homotopy-equivalent to a discrete set of points) simplifies things a bit.
Cobordism Category as -Category
So how should we think of cobordisms as forming an -category? There are a few stages in making a precise definition, but the basic idea is simple enough. One starts with manifolds and cobordisms embedded in some fixed finite-dimensional vector space  , and then takes a limit over all
, and then takes a limit over all 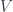 . In each , the coordinates of the
. In each , the coordinates of the  factor give ways of cutting the cobordism into pieces, and gluing them back together defines composition in a different direction. Now, this won’t actually produce a complete Segal space: one has to take a certain kind of completion. But the idea is intuitive enough.
factor give ways of cutting the cobordism into pieces, and gluing them back together defines composition in a different direction. Now, this won’t actually produce a complete Segal space: one has to take a certain kind of completion. But the idea is intuitive enough.
We want to define an -fold C.S.S. of cobordisms (and cobordisms between cobordisms, and so on, up to -morphisms). To start with, think of the case  : then the space of objects of
: then the space of objects of  consists of all embeddings of a
consists of all embeddings of a 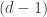 -dimensional manifold into . The space of -simplexes (of -tuples of morphisms) consists of all ways of cutting up a
-dimensional manifold into . The space of -simplexes (of -tuples of morphisms) consists of all ways of cutting up a  -dimensional cobordism embedded in
-dimensional cobordism embedded in  by choosing
by choosing 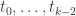 , where we think of the cobordism having been glued from two pieces, where at the slice
, where we think of the cobordism having been glued from two pieces, where at the slice  , we have the object where the two pieces were composed. (One has to be careful to specify that the Morse function on the cobordisms, got by projection only
, we have the object where the two pieces were composed. (One has to be careful to specify that the Morse function on the cobordisms, got by projection only  , has its critical points away from the
, has its critical points away from the 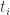 – the generic case – to make sure that the objects where gluing happens are actual manifolds.)
– the generic case – to make sure that the objects where gluing happens are actual manifolds.)
Now, what about the higher morphisms of the -category? The point is that one needs to have an -groupoid – that is, a space! – of morphisms between two cobordisms  and
and 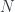 . To make sense of this, we just take the space
. To make sense of this, we just take the space  of diffeomorphisms – not just as a set of morphisms, but including its topology as well. The higher morphisms, therefore, can be thought of precisely as paths, homotopies, homotopies between homotopies, and so on, in these spaces. So the essential difference between the 1-category of cobordisms and the -category is that in the first case, morphisms are diffeomorphism classes of cobordisms, whereas in the latter, the higher morphisms are made precisely of the space of diffeomorphisms which we quotient out by in the first case.
of diffeomorphisms – not just as a set of morphisms, but including its topology as well. The higher morphisms, therefore, can be thought of precisely as paths, homotopies, homotopies between homotopies, and so on, in these spaces. So the essential difference between the 1-category of cobordisms and the -category is that in the first case, morphisms are diffeomorphism classes of cobordisms, whereas in the latter, the higher morphisms are made precisely of the space of diffeomorphisms which we quotient out by in the first case.
Now, -categories, can have non-invertible morphisms between morphisms all the way up to dimension , after which everything is invertible. An -fold C.S.S. does this by taking the definition of a complete Segal space and copying it inside -fold C.S.S’s: that is, one has an -fold Complete Segal Space of -tuples of morphisms, for each , they form a simplicial object, and so forth.
Now, if we want to build an -category of cobordisms, the idea is the same, except that we have a simplicial object, in a category of simplicial objects, and so on. However, the way to define this is essentially similar. To specify an -fold C.S.S., we have to specify a whole collection of spaces associated to cobordisms equipped with embeddings into . In particular, for each tuple  , we have the space of such embeddings, such that for each
, we have the space of such embeddings, such that for each  one has
one has  special points
special points  along the
along the 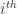 coordinate axis. These are the ways of breaking down a given cobordism into a composite of
coordinate axis. These are the ways of breaking down a given cobordism into a composite of  pieces. Again, one has to make sure that these critical points of the Morse functions defined by the projections onto these coordinate axes avoid these special which define the manifolds where gluing takes place. The composition maps which make these into a simplical object are quite natural – they just come by deleting special points.
pieces. Again, one has to make sure that these critical points of the Morse functions defined by the projections onto these coordinate axes avoid these special which define the manifolds where gluing takes place. The composition maps which make these into a simplical object are quite natural – they just come by deleting special points.
Finally, we take a limit over all (to get around limits to embeddings due to the dimension of ). So we know (at least abstractly) what the -category of cobordisms should be. The cobordism hypothesis claims it is equivalent to one defined in a free, algebraically-flavoured way, namely as the free symmetric monoidal -category on a fully-dualizable object. (That object is “the point” – which, up to the kind of homotopically-flavoured equivalence that matters here, is the only object when our highest-dimensional cobordisms have dimension ).
Dualizability
So what does that mean, a “fully dualizable object”?
First, to get the idea, let’s think of the 1-dimensional example. Instead of “-category”, we would like to just think of this as a statement about a category. Then is the 1-category of framed bordisms. For a manifold (or cobordism, which is a manifold with boundary), a framing is a trivialization of the tangent bundle. That is, it amounts to a choice of isomorphism at each point between the tangent space there and the corresponding . So the objects of are collections of (signed) points, and the morphisms are equivalence classes of framed 1-dimensional cobordisms. These amount to oriented 1-manifolds with boundary, where the points (objects) on the boundary are the source and target of the cobordism.
Now we want to classify what TQFT’s live on this category. These are functors  . We have two generating objects,
. We have two generating objects,  and
and  , the two signed points. A TQFT must assign these objects vector spaces, which we’ll call and
, the two signed points. A TQFT must assign these objects vector spaces, which we’ll call and 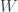 . Collections of points get assigned tensor products of all the corresponding vector spaces, since the functor is monoidal, so knowing these two vector spaces determines what
. Collections of points get assigned tensor products of all the corresponding vector spaces, since the functor is monoidal, so knowing these two vector spaces determines what  does to all objects.
does to all objects.
What does do to morphisms? Well, some generating morphsims of interest are cups and caps: these are lines which connect a positive to a negative point, but thought of as cobordisms taking two points to the empty set, and vice versa. That is, we have an evaluation:This statement is what is generalized to say that -dimensional TQFT’s are classified by “fully” dualizable objects.
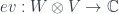
and a coevaluation:
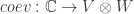
Now, since cobordisms are taken up to equivalence, which in particular includes topological deformations, we get a bunch of relations which these have to satisfy. The essential one is the “zig-zag” identity, reflecting the fact that a bent line can be straightened out, and we have the same 1-morphism in  . This implies that:
. This implies that:

is the same as the identity. This in turn means that the evaluation and coevaluation maps define a nondegenerate pairing between and . The fact that this exists means two things. First, is the dual of : 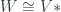 . Second, this only makes sense if both and its dual are finite dimensional (since the evaluation will just be the trace map, which is not even defined on the identity if is infinite dimensional).
. Second, this only makes sense if both and its dual are finite dimensional (since the evaluation will just be the trace map, which is not even defined on the identity if is infinite dimensional).
On the other hand, once we know, , this determines up to isomorphism, as well as the evaluation and coevaluation maps. In fact, this turns out to be enough to specify entirely. The classification then is: 1-D TQFT’s are classified by finite-dimensional vector spaces . Crucially, what made finiteness important is the existence of the dual 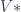 and the (co)evaluation maps which express the duality.
and the (co)evaluation maps which express the duality.
In an -category, to say that an object is “fully dualizable” means more that the object has a dual (which, itself, implies the existence of the morphisms  and
and 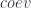 ). It also means that and have duals themselves – or rather, since we’re talking about morphisms, “adjoints”. This in turn implies the existence of 2-morphisms which are the unit and counit of the adjunctions (the defining properties are essentially the same as those for morphisms which define a dual). In fact, every time we get a morphism of degree less than in this process, “fully dualizable” means that it too must have a dual (i.e. an adjoint).
). It also means that and have duals themselves – or rather, since we’re talking about morphisms, “adjoints”. This in turn implies the existence of 2-morphisms which are the unit and counit of the adjunctions (the defining properties are essentially the same as those for morphisms which define a dual). In fact, every time we get a morphism of degree less than in this process, “fully dualizable” means that it too must have a dual (i.e. an adjoint).
This does run out eventually, though, since we only require this goes up to dimension : the -morphisms which this forces to exist (quite a few) aren’t required to have duals. This is good, because if they were, since all the higher morphisms available are invertible, this would mean that the dual -morphisms would actually be weak inverses (that is, their composite is isomorphic to the identity)… But that would mean that the dual -morphisms which forced them to exist would also be weak inverses (their composite would be weakly isomorphic to the identity)… and so on! In fact, if the property of “having duals” didn’t stop, then everything would be weakly invertible: we’d actually have a (weak) -groupoid!
Classifying TQFT
So finally, the point of the Cobordism Hypothesis is that a (fully extended) TQFT is a functor out of this  into some target -category . There are various options, but whatever we pick, the functor must assign something in to the point, say
into some target -category . There are various options, but whatever we pick, the functor must assign something in to the point, say 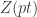 , and something to each of and , as well as all the higher morphisms which must exist. Then functoriality means that all these images have to again satisfy the properties which make a fully dualizable object. Furthermore, since is the free gadget with all these properties on the single object
, and something to each of and , as well as all the higher morphisms which must exist. Then functoriality means that all these images have to again satisfy the properties which make a fully dualizable object. Furthermore, since is the free gadget with all these properties on the single object  , this is exactly what it means that is a functor. Saying that is fully dualizable, by implication, includes all the choices of morphisms like
, this is exactly what it means that is a functor. Saying that is fully dualizable, by implication, includes all the choices of morphisms like 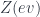 etc. which show it as fully dualizable. (Conceivably one could make the same object fully dualizable in more than one way – these would be different functors).
etc. which show it as fully dualizable. (Conceivably one could make the same object fully dualizable in more than one way – these would be different functors).
So an extended -dimensional TQFT is exactly the choice of a fully dualizable object 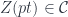 , for some -category . This object is “what the TQFT assigns to a point”, but if we understand the structure of the object as a fully dualizable object, then we know what the TQFT assigns to any other manifold of any dimension up to , the highest dimension in the theory. This is how this algebraic characterization of cobordisms helps to classify such theories.
, for some -category . This object is “what the TQFT assigns to a point”, but if we understand the structure of the object as a fully dualizable object, then we know what the TQFT assigns to any other manifold of any dimension up to , the highest dimension in the theory. This is how this algebraic characterization of cobordisms helps to classify such theories.

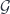
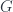

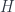
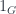
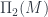
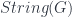
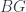
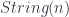

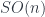
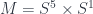

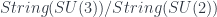
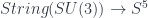
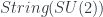
 we must be able to find the fields on
we must be able to find the fields on 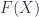 . For example,
. For example, 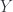 , this defines a vector space of linear combinations of fields, modulo relations, called
, this defines a vector space of linear combinations of fields, modulo relations, called  , where
, where  . The dual space of
. The dual space of 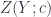 – in keeping with the principle that quantum states are functionals that we can evaluate on “classical” fields.
– in keeping with the principle that quantum states are functionals that we can evaluate on “classical” fields. .
. 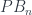 fits inside them. In particular, the slide moves satisfy some of the same relations as the braid group – the Yang-Baxter equations.
fits inside them. In particular, the slide moves satisfy some of the same relations as the braid group – the Yang-Baxter equations. . Every loop braid could be “closed up” to a 4D knotted surface, though not every knotted surface would be of this form. For one thing, our loops have a trivial embedding in 3D space here – to get every possible knotted surface, we’d need to have knots and links sliding around, braiding through each other, merging and splitting, etc. Knotted surfaces are much more complex than knotted circles, just as the topology of embedded circles is more complex than that of embedded points.
. Every loop braid could be “closed up” to a 4D knotted surface, though not every knotted surface would be of this form. For one thing, our loops have a trivial embedding in 3D space here – to get every possible knotted surface, we’d need to have knots and links sliding around, braiding through each other, merging and splitting, etc. Knotted surfaces are much more complex than knotted circles, just as the topology of embedded circles is more complex than that of embedded points. : representations on spaces where each loop is attached some
: representations on spaces where each loop is attached some 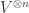 (a tensor product of
(a tensor product of 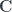 can be described in terms of its group of automorphisms: all the ways the object can be transformed which leave it “the same”. This fits our understanding of “symmetry” when the morphisms can really be interpreted as transformations of some sort. So let’s suppose the object is a set with some structure, and the morphisms are set-maps that preserve the structure: for example, the objects could be sets of vertices and edges of a graph, so that morphisms are maps of the underlying data that preserve incidence relations. So a symmetry of an object is a way of transforming it into itself – and an invertible one at that – and these automorphisms naturally form a group
can be described in terms of its group of automorphisms: all the ways the object can be transformed which leave it “the same”. This fits our understanding of “symmetry” when the morphisms can really be interpreted as transformations of some sort. So let’s suppose the object is a set with some structure, and the morphisms are set-maps that preserve the structure: for example, the objects could be sets of vertices and edges of a graph, so that morphisms are maps of the underlying data that preserve incidence relations. So a symmetry of an object is a way of transforming it into itself – and an invertible one at that – and these automorphisms naturally form a group 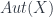 . More generally, we can talk about an action of a group
. More generally, we can talk about an action of a group 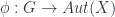 .
. is faithful: you can tell morphisms in
is faithful: you can tell morphisms in 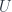 forgets about – or, conversely, that the structure on objects of
forgets about – or, conversely, that the structure on objects of 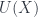 .
.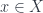 and
and  , then
, then  and
and 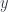 are “symmetric” points under some transformation. As Weinstein’s article illustrates nicely, though, there is no assumption that the given transformation actually extends to the entire object
are “symmetric” points under some transformation. As Weinstein’s article illustrates nicely, though, there is no assumption that the given transformation actually extends to the entire object 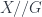 for short. Its morphisms consist of pairs such that
for short. Its morphisms consist of pairs such that  is a morphism taking
is a morphism taking  . The “local” symmetry view of
. The “local” symmetry view of 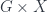 .
.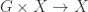 . It is not hard to show that this map is an action in another standard sense. Namely, if we have a real action
. It is not hard to show that this map is an action in another standard sense. Namely, if we have a real action 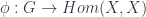 , then this map is just
, then this map is just 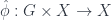 , which moves one of the arguments to the left side. If
, which moves one of the arguments to the left side. If 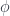 was a functor, then $\hat{\phi}$ satisfies the “action” condition, namely that the following square commutes:
was a functor, then $\hat{\phi}$ satisfies the “action” condition, namely that the following square commutes: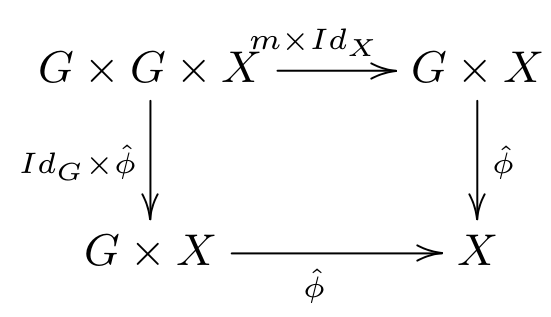
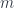 is the multiplication in
is the multiplication in  : we are thinking of
: we are thinking of 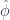 must be in the same category,
must be in the same category,  , there is an object
, there is an object  , the internal hom. In this case, it’s
, the internal hom. In this case, it’s  which appears in the diagram. Such an internal hom is supposed to be a dual to
which appears in the diagram. Such an internal hom is supposed to be a dual to  ): this is exactly what lets us talk about
): this is exactly what lets us talk about  , the category of topological spaces, where there is indeed a faithful underlying set functor. But although talking explicitly about elements of
, the category of topological spaces, where there is indeed a faithful underlying set functor. But although talking explicitly about elements of 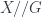 relates global and local symmetries, it played no particular role in the construction.
relates global and local symmetries, it played no particular role in the construction. , or as a 1-category with some structure – a group object in
, or as a 1-category with some structure – a group object in 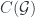 if it comes from a given 2-group. (In our paper, we keep these distinct by using the term “categorical group” for the second. The group axioms amount to saying that we have a monoidal category
if it comes from a given 2-group. (In our paper, we keep these distinct by using the term “categorical group” for the second. The group axioms amount to saying that we have a monoidal category 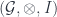 . Its objects are the morphisms of the 2-group, and the composition becomes the monoidal product
. Its objects are the morphisms of the 2-group, and the composition becomes the monoidal product 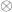 .)
.)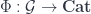 . The object being acted on,
. The object being acted on, 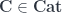 , is the unique object
, is the unique object 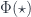 – so that the 2-functor amounts to a monoidal functor from the categorical group
– so that the 2-functor amounts to a monoidal functor from the categorical group  . Notice that here we’re taking advantage of the fact that
. Notice that here we’re taking advantage of the fact that 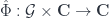 , which corresponds to the 2-functor
, which corresponds to the 2-functor 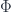 , and satisfies an action axiom like the square above, with
, and satisfies an action axiom like the square above, with  for each 2-group morphism
for each 2-group morphism 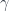 – each of which consists of a function between objects of
– each of which consists of a function between objects of 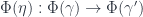 for 2-morphisms
for 2-morphisms 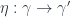 in the 2-group – each of which consists of a function from objects to morphisms of
in the 2-group – each of which consists of a function from objects to morphisms of 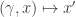 is just given by
is just given by 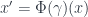 . The map taking pairs of morphisms
. The map taking pairs of morphisms  to morphisms of
to morphisms of  are equivalent, it should be no surprise that we ought to be able to reconstruct the other two parts of
are equivalent, it should be no surprise that we ought to be able to reconstruct the other two parts of 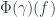 or
or 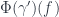 ), and the natural transformation maps (which give
), and the natural transformation maps (which give 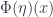 or
or 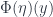 ). In fact, there are only two sensible ways to combine these four bits of information, and the fact that
). In fact, there are only two sensible ways to combine these four bits of information, and the fact that 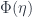 is natural means precisely that they’re the same, so:
is natural means precisely that they’re the same, so: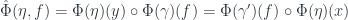
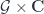 , and the target functor is just the action map
, and the target functor is just the action map 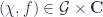 looks like:
looks like: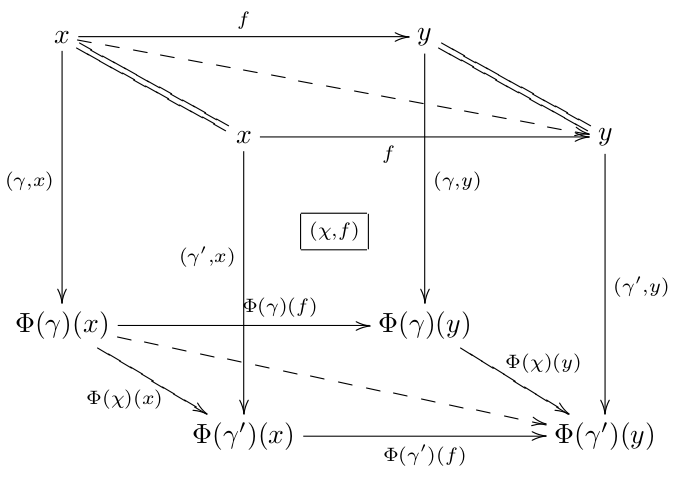

 -objects on the set of
-objects on the set of  . Meanwhile, the horizontal morphisms and squares make up the transformation groupoid
. Meanwhile, the horizontal morphisms and squares make up the transformation groupoid  . These are the object-category and morphism-category of the transpose of the double-category we started with.
. These are the object-category and morphism-category of the transpose of the double-category we started with. and
and 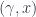 , the only 2-morphisms which can appear are those taking
, the only 2-morphisms which can appear are those taking  which has the same effect on
which has the same effect on  -groupoids) is that this is not the same type of object as a transformation double category.
-groupoids) is that this is not the same type of object as a transformation double category.


 is the “classifying space” of the Lie group – homotopy classes of maps in
is the “classifying space” of the Lie group – homotopy classes of maps in 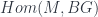 are the same as groupoid homomorphisms in
are the same as groupoid homomorphisms in  . Specifically, the pair of functors
. Specifically, the pair of functors  and
and  relating groupoids and topological spaces are adjoints. Now, this deals with the situation where
relating groupoids and topological spaces are adjoints. Now, this deals with the situation where 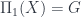 , and no other interesting homotopy groups. To deal with more general target spaces
, and no other interesting homotopy groups. To deal with more general target spaces  , but also interesting second homotopy group
, but also interesting second homotopy group  (and nothing higher). These fit together to make a 2-groupoid
(and nothing higher). These fit together to make a 2-groupoid 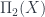 , which is a 2-group if
, which is a 2-group if  correspond to flat connections in this 2-group.
correspond to flat connections in this 2-group.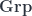 – which have a group of objects and a group of morphisms, and group homomorphisms that define source, target, composition, and so on. This second way is fairly close to the equivalent formulation as crossed modules
– which have a group of objects and a group of morphisms, and group homomorphisms that define source, target, composition, and so on. This second way is fairly close to the equivalent formulation as crossed modules 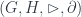 . The definition is in the slides, but essentially the point is that
. The definition is in the slides, but essentially the point is that  , one gets the semidirect product
, one gets the semidirect product  which is the group of morphisms. The map
which is the group of morphisms. The map  makes it possible to speak of
makes it possible to speak of  , the Lie algebra of
, the Lie algebra of  .
. , whose space of objects is exactly the moduli space of 2-connections, and whose 1- and 2-morphisms are exactly these gauge transformations and modifications. So the question is, what is the meaning of the extra information contained in the 2-groupoid which doesn’t appear in the moduli space itself?
, whose space of objects is exactly the moduli space of 2-connections, and whose 1- and 2-morphisms are exactly these gauge transformations and modifications. So the question is, what is the meaning of the extra information contained in the 2-groupoid which doesn’t appear in the moduli space itself? is the 2-category of interest. Then an action is just a map:
is the 2-category of interest. Then an action is just a map: . This object
. This object  for every morphism in
for every morphism in  , which we might call 2-symmetries relating 1-symmetries.
, which we might call 2-symmetries relating 1-symmetries. . The set of morphisms is built as a pullback of the action map,
. The set of morphisms is built as a pullback of the action map,  .
.
 , thought of as going from
, thought of as going from  to
to  . The rule for composing these is another pullback. The diagram which shows how it’s done appears in the slides. The whole construction ends up giving a cubical diagram in
. The rule for composing these is another pullback. The diagram which shows how it’s done appears in the slides. The whole construction ends up giving a cubical diagram in  , whose top and bottom faces are mere commuting diagrams, and whose four other faces are all pullback squares.
, whose top and bottom faces are mere commuting diagrams, and whose four other faces are all pullback squares.
 is an action just means this commutes. In principle, we could define a weak action, which would mean that this commutes up to isomorphism, but we won’t be looking at that here.
is an action just means this commutes. In principle, we could define a weak action, which would mean that this commutes up to isomorphism, but we won’t be looking at that here. , we call this double category
, we call this double category 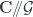 .
. shows up by letting its objects be the vertical arrows of the double category, and its morphisms be the squares. These look like this:
shows up by letting its objects be the vertical arrows of the double category, and its morphisms be the squares. These look like this:
 . Each square (morphism in the category of morphisms) is given by a pair
. Each square (morphism in the category of morphisms) is given by a pair  of morphisms, one from
of morphisms, one from  ), and one from
), and one from 
 is a natural transformation.
is a natural transformation.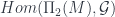 , can be seen as coming from a 2-group action on a category – the objects of this category being exactly the connections. In the slides above, for various reasons, we did this in a discretized setting – a manifold with a decomposition into cells. This is useful for writing things down explicitly, but not essential to the idea behind the 2-symmetry of the moduli space.
, can be seen as coming from a 2-group action on a category – the objects of this category being exactly the connections. In the slides above, for various reasons, we did this in a discretized setting – a manifold with a decomposition into cells. This is useful for writing things down explicitly, but not essential to the idea behind the 2-symmetry of the moduli space. , whose objects are the connections: these assign
, whose objects are the connections: these assign  , on the other hand, is purely about local transformations. If
, on the other hand, is purely about local transformations. If  : one copy of the gauge 2-group at each vertex. (Keeping this finite dimensional and avoiding technical details was one main reason we chose to use a discretization. In principle, one could also talk about the 2-group of
: one copy of the gauge 2-group at each vertex. (Keeping this finite dimensional and avoiding technical details was one main reason we chose to use a discretization. In principle, one could also talk about the 2-group of  . This expresses the 2-symmetry by moving some gauge transformations into the category of connections, and others into the 2-group which acts on it. But physically, we would like to say that both are “gauge transformations”. So one way to do this is to “collapse” the double category to a bicategory: just formally allow horizontal and vertical arrows to compose, so that there is only one kind of arrow. Squares become 2-cells.
. This expresses the 2-symmetry by moving some gauge transformations into the category of connections, and others into the 2-group which acts on it. But physically, we would like to say that both are “gauge transformations”. So one way to do this is to “collapse” the double category to a bicategory: just formally allow horizontal and vertical arrows to compose, so that there is only one kind of arrow. Squares become 2-cells.


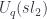 , somewhat along the same lines as in his
, somewhat along the same lines as in his  on categories. This starting point is nice, because it can work by just mimicking the construction of
on categories. This starting point is nice, because it can work by just mimicking the construction of  which correspond to the “weight spaces” (usually just vector spaces), and the
which correspond to the “weight spaces” (usually just vector spaces), and the 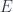 and
and  operators give functors between them, and so forth.
operators give functors between them, and so forth. , which is the space of all 1-dimensional subspaces of
, which is the space of all 1-dimensional subspaces of 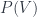 ), which is of course an algebraic variety. Likewise,
), which is of course an algebraic variety. Likewise, 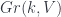 , the space of all
, the space of all  consists of all pairs
consists of all pairs  , of a
, of a  -dimensional subspace (the case
-dimensional subspace (the case 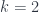 calls to mind the reason for the name: a plane intersecting a given line resembles a flag stuck to a flagpole). This collection is again a variety. One can go all the way up to the variety of “complete flags”,
calls to mind the reason for the name: a plane intersecting a given line resembles a flag stuck to a flagpole). This collection is again a variety. One can go all the way up to the variety of “complete flags”,  (where
(where 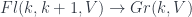 and
and  , which act by just ignoring one or the other of the two subspaces of a flag. This pair of maps, by way of pulling-back and pushing-forward functions, gives maps between the cohomology rings of these spaces. So one gets a sequence
, which act by just ignoring one or the other of the two subspaces of a flag. This pair of maps, by way of pulling-back and pushing-forward functions, gives maps between the cohomology rings of these spaces. So one gets a sequence  , and maps between the adjacent ones. This becomes a representation of the Lie algebra. Categorifying this, one replaces the cohomology rings with derived categories of sheaves on the flag varieties – then the same sort of “pull-push” operation through (derived categories of sheaves on) the flag varieties defines functors between those categories. So one gets a categorified representation.
, and maps between the adjacent ones. This becomes a representation of the Lie algebra. Categorifying this, one replaces the cohomology rings with derived categories of sheaves on the flag varieties – then the same sort of “pull-push” operation through (derived categories of sheaves on) the flag varieties defines functors between those categories. So one gets a categorified representation.![\mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , generated by the multiplication operators
, generated by the multiplication operators 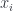 , and the “divided difference operators” based on the swapping of two adjacent variables. The Hecke algebra is defined in terms of “swap” generators, which satisfy some
, and the “divided difference operators” based on the swapping of two adjacent variables. The Hecke algebra is defined in terms of “swap” generators, which satisfy some  -deformed variation of the relations that define the symmetric group (and hence its group algebra). The Nil Hecke algebra is so called since the “swap” (i.e. the divided difference) is nilpotent: the square of the swap is zero. The way this acts on the objects of the diagrammatic category is reflected by morphisms drawn as crossings of strands, which are then formally forced to satisfy the relations of the Nil Hecke algebra.
-deformed variation of the relations that define the symmetric group (and hence its group algebra). The Nil Hecke algebra is so called since the “swap” (i.e. the divided difference) is nilpotent: the square of the swap is zero. The way this acts on the objects of the diagrammatic category is reflected by morphisms drawn as crossings of strands, which are then formally forced to satisfy the relations of the Nil Hecke algebra. web algebra, describing the results of
web algebra, describing the results of 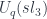 , describing a diagram calculus which accounts for representations of the quantum group. The “web algebra” was introduced by Greg Kuperberg – it’s an algebra built from diagrams which can now include some trivalent vertices, along with rules imposing relations on these. When categorifying, one gets a calculus of “foams” between such diagrams. Since this is obviously fairly diagram-heavy, I won’t try here to reproduce what’s in the paper – but an important part of is the correspondence between webs and Young Tableaux, since these are labels in the representation theory of the quantum group – so there is some interesting combinatorics here as well.
, describing a diagram calculus which accounts for representations of the quantum group. The “web algebra” was introduced by Greg Kuperberg – it’s an algebra built from diagrams which can now include some trivalent vertices, along with rules imposing relations on these. When categorifying, one gets a calculus of “foams” between such diagrams. Since this is obviously fairly diagram-heavy, I won’t try here to reproduce what’s in the paper – but an important part of is the correspondence between webs and Young Tableaux, since these are labels in the representation theory of the quantum group – so there is some interesting combinatorics here as well. (which one should think of as something like Planck’s constant in a quantum setting). The “classical” limit is the constant term of the power series, and the “semiclassical” limit is the first-order term. This gives a Poisson bracket (or rather, the commutator of the associative product does). In the examples, the spaces where these things are defined are all spaces of polynomials (which makes a lot of explicit computer-driven calculations more convenient). The talk gives a way of constructing a big class of Poisson brackets (having some nice properties: they are “iterated Poisson brackets”) coming from quantum groups as semiclassical limits. The construction uses words in the generating reflections for the Weyl group of a Lie group
(which one should think of as something like Planck’s constant in a quantum setting). The “classical” limit is the constant term of the power series, and the “semiclassical” limit is the first-order term. This gives a Poisson bracket (or rather, the commutator of the associative product does). In the examples, the spaces where these things are defined are all spaces of polynomials (which makes a lot of explicit computer-driven calculations more convenient). The talk gives a way of constructing a big class of Poisson brackets (having some nice properties: they are “iterated Poisson brackets”) coming from quantum groups as semiclassical limits. The construction uses words in the generating reflections for the Weyl group of a Lie group  of two groups
of two groups 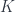 (each of which has to act on the other for this to make sense). He gave the example of the Poincare double group, which breaks down as a triple bicrossed product by the Iwasawa decomposition:
(each of which has to act on the other for this to make sense). He gave the example of the Poincare double group, which breaks down as a triple bicrossed product by the Iwasawa decomposition:
 , and the horizontial and vertical morphisms by elements of
, and the horizontial and vertical morphisms by elements of  and
and 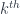 cohomology,
cohomology,  , is a quotient of the space of closed
, is a quotient of the space of closed 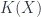 , which can be modelled as a quotient of the space of vector bundles over
, which can be modelled as a quotient of the space of vector bundles over 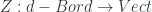
 , since it comes equipped with a sheaf of rings (each open set has an associated ring of smooth functions, and these glue together nicely). Supersymmetric theories work with manifolds which change this sheaf – so a
, since it comes equipped with a sheaf of rings (each open set has an associated ring of smooth functions, and these glue together nicely). Supersymmetric theories work with manifolds which change this sheaf – so a  -dimensional space has the sheaf of rings where one introduces some new antisymmetric coordinate functions
-dimensional space has the sheaf of rings where one introduces some new antisymmetric coordinate functions  , the “fermionic dimensions”:
, the “fermionic dimensions”:![\mathcal{O}(U) = C^{\infty}(U) \otimes \bigwedge^{\ast}[\theta_1,\dots,\theta_{\delta}]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BO%7D%28U%29+%3D+C%5E%7B%5Cinfty%7D%28U%29+%5Cotimes+%5Cbigwedge%5E%7B%5Cast%7D%5B%5Ctheta_1%2C%5Cdots%2C%5Ctheta_%7B%5Cdelta%7D%5D&bg=ffffff&fg=29303b&s=0&c=20201002)
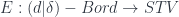
 is the category of supersymmetric topological vector spaces – defined similarly). The connection to cohomology theories is that the classes of such field theories, up to a notion of equivalence called “concordance”, are classified by various cohomology theories. Ordinary cohomology corresponds then to
is the category of supersymmetric topological vector spaces – defined similarly). The connection to cohomology theories is that the classes of such field theories, up to a notion of equivalence called “concordance”, are classified by various cohomology theories. Ordinary cohomology corresponds then to  -dimensional extended TFT (that is, with 0 bosonic and 1 fermionic dimension), and
-dimensional extended TFT (that is, with 0 bosonic and 1 fermionic dimension), and  -dimensional extended TFT. The Stoltz-Teichner Conjecture is that the third example (topological modular forms) is related in the same way to a
-dimensional extended TFT. The Stoltz-Teichner Conjecture is that the third example (topological modular forms) is related in the same way to a  -dimensional extended TFT – so these are the start of a series of cohomology theories related to various-dimension TFT’s.
-dimensional extended TFT – so these are the start of a series of cohomology theories related to various-dimension TFT’s. shifts things by one categorical level: its points are loops in
shifts things by one categorical level: its points are loops in 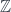 with
with 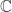 ). The key thing is how to represent the algebra by generators and relations. Since free monoidal categories with various sorts of structures
). The key thing is how to represent the algebra by generators and relations. Since free monoidal categories with various sorts of structures  , which in turn are classified by Dynkin diagrams. The vertices of these Dynkin diagrams correspond to some generators of the Heisenberg algebra, and one can modify Khovanov’s categorification by having strands in the diagram calculus be labelled by these vertices. Rules for local moves involving strands with different labels will be governed by the edges of the Dynkin diagram. Their paper goes on to describe how to represent these categorifications on certain categories of Hilbert schemes.
, which in turn are classified by Dynkin diagrams. The vertices of these Dynkin diagrams correspond to some generators of the Heisenberg algebra, and one can modify Khovanov’s categorification by having strands in the diagram calculus be labelled by these vertices. Rules for local moves involving strands with different labels will be governed by the edges of the Dynkin diagram. Their paper goes on to describe how to represent these categorifications on certain categories of Hilbert schemes.![P_a = \mathbb{Z}[x_1,\dots,x_a]](https://s0.wp.com/latex.php?latex=P_a+%3D+%5Cmathbb%7BZ%7D%5Bx_1%2C%5Cdots%2Cx_a%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , generated by multiplications (by the
, generated by multiplications (by the  . There are different from the usual derivative operators: in place of the differences between values of a single variable, they measure how a function behaves under the operation
. There are different from the usual derivative operators: in place of the differences between values of a single variable, they measure how a function behaves under the operation 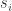 which switches variables
which switches variables  (that is, the reflection in the hyperplane where
(that is, the reflection in the hyperplane where 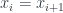 ). The point is that just like differentiation, this operator – together with multiplication – generates an algebra in
). The point is that just like differentiation, this operator – together with multiplication – generates an algebra in ![End(\mathbb{Z}[x_1,\dots,x_a]](https://s0.wp.com/latex.php?latex=End%28%5Cmathbb%7BZ%7D%5Bx_1%2C%5Cdots%2Cx_a%5D&bg=ffffff&fg=29303b&s=0&c=20201002) . Aaron described how to categorify this presentation of the NilHecke algebra with a string-diagram calculus.
. Aaron described how to categorify this presentation of the NilHecke algebra with a string-diagram calculus.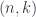 pasta diagrams”, where we’ve just mentioned the
pasta diagrams”, where we’ve just mentioned the  and
and  cases, with
cases, with  can be analyzed by decomposing them into “weight spaces”
can be analyzed by decomposing them into “weight spaces”  , associated to weights
, associated to weights 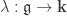 (where
(where  is the base field, which we can generally assume is
is the base field, which we can generally assume is  on a “weight vector”
on a “weight vector” 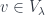 amounts to multiplying by
amounts to multiplying by  . (So that
. (So that  is an eigenvector for each
is an eigenvector for each  , but the eigenvalue depends on
, but the eigenvalue depends on  if the difference is a nonnegative combination of simple weights). Then a “highest weight representation” is one which is generated under the action of
if the difference is a nonnegative combination of simple weights). Then a “highest weight representation” is one which is generated under the action of ![\mathbb{C}[x_1, \dots, x_n]/I](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bx_1%2C+%5Cdots%2C+x_n%5D%2FI&bg=ffffff&fg=29303b&s=0&c=20201002) (where I is some ideal of homogeneous symmetric polynomials). The morphisms are endofunctors of this category, which all amount to tensoring with certain bimodules – the irreducible ones being the Soergel bimodules. The point of the talk was to explain the representations of 2-categories
(where I is some ideal of homogeneous symmetric polynomials). The morphisms are endofunctors of this category, which all amount to tensoring with certain bimodules – the irreducible ones being the Soergel bimodules. The point of the talk was to explain the representations of 2-categories  modules, we get the semigroup of nonnegative integers. For the Soergel bimodule 2-category, we get the symmetric group. This sort of thing helps characterize when two objects are equivalent, and in turn helps describe 2-representations up to some equivalence. (You can find much more detail behind the link above.)
modules, we get the semigroup of nonnegative integers. For the Soergel bimodule 2-category, we get the symmetric group. This sort of thing helps characterize when two objects are equivalent, and in turn helps describe 2-representations up to some equivalence. (You can find much more detail behind the link above.) determine a representation space for a group
determine a representation space for a group  , namely the tensor product of a bunch of wedge products,
, namely the tensor product of a bunch of wedge products,  , where
, where 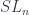 acts on
acts on  as usual. Then a web determines an invariant vector in this space. This comes about by having invariant vectors for each vertex (the basic case where
as usual. Then a web determines an invariant vector in this space. This comes about by having invariant vectors for each vertex (the basic case where  ), and tensoring them together. But the point is to interpret this construction geometrically. This was a bit outside my grasp, since it involves the
), and tensoring them together. But the point is to interpret this construction geometrically. This was a bit outside my grasp, since it involves the  of
of  . Then there’s a correspondence between the category of representations of
. Then there’s a correspondence between the category of representations of 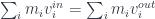 , where
, where  ). So the moduli space is some projective algebraic variety. Jim explained how “dimensional analysis” in physics is the study of line bundles over such varieties (“dimensions” are just such line bundles, since a “dimension” is a 1-dimensional sort of thing, and “quantities” in those dimensions are sections of the line bundles). Then there’s a category of such bundles, which are organized into a special sort of symmetric monoidal category – in fact, it’s contrained so much it’s just a graded commutative algebra.
). So the moduli space is some projective algebraic variety. Jim explained how “dimensional analysis” in physics is the study of line bundles over such varieties (“dimensions” are just such line bundles, since a “dimension” is a 1-dimensional sort of thing, and “quantities” in those dimensions are sections of the line bundles). Then there’s a category of such bundles, which are organized into a special sort of symmetric monoidal category – in fact, it’s contrained so much it’s just a graded commutative algebra.
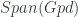 has groupoids as its objects, spans of groupoid homomorphisms as its arrows, and spans-of-span-maps as 2-morphisms.
has groupoids as its objects, spans of groupoid homomorphisms as its arrows, and spans-of-span-maps as 2-morphisms.  is the 2-category of 2-vector spaces, which I’ve explained before. This 2-functor is supposed to be a sort of “linearization”, which is a very simple functor
is the 2-category of 2-vector spaces, which I’ve explained before. This 2-functor is supposed to be a sort of “linearization”, which is a very simple functor
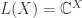 , and a span
, and a span  to a linear map
to a linear map  . This can be described in two stages, starting with a vector in
. This can be described in two stages, starting with a vector in  , namely, a function
, namely, a function  . The two stages are:
. The two stages are: up along
up along  (note: I’m conflating the set
(note: I’m conflating the set  ), to get the function
), to get the function  .
.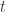 to get
to get 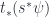 . The “push” operation
. The “push” operation 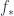 along any map
along any map  is determined by the fact that it takes the basis vector
is determined by the fact that it takes the basis vector  to the basis vector
to the basis vector  (these are the delta functions which are 1 on the given element and 0 elsewhere)
(these are the delta functions which are 1 on the given element and 0 elsewhere) -entry of the matrix counts the elements of
-entry of the matrix counts the elements of  . We interpret this by saying the matrix “counts histories” connecting
. We interpret this by saying the matrix “counts histories” connecting  with
with  , the 2-category of (essentially) finite groupoids, but we still have a functor into
, the 2-category of (essentially) finite groupoids, but we still have a functor into  . In fact, into
. In fact, into 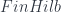 : the vector space
: the vector space 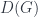 is the free one on isomorphism classes in
is the free one on isomorphism classes in  -groupoids”, which are labelled by phases – which represent the exponentiated action in quantum mechanics – and end up with complex matrices. So far so good.
-groupoids”, which are labelled by phases – which represent the exponentiated action in quantum mechanics – and end up with complex matrices. So far so good. (in smooth cases, we might want to restrict what kind of representations we mean – see below).
(in smooth cases, we might want to restrict what kind of representations we mean – see below). . The push map in 2-linearization is the
. The push map in 2-linearization is the  along
along  . This is the universal way to push a functor forward, and is the (categorical!) adjoint to the pull map. (Kan extensions are supposed to come equipped with some natural transformations: these are the ones associated to the adjunction). Then composing “pull” and “push”, one categorifies “sum over histories”.
. This is the universal way to push a functor forward, and is the (categorical!) adjoint to the pull map. (Kan extensions are supposed to come equipped with some natural transformations: these are the ones associated to the adjunction). Then composing “pull” and “push”, one categorifies “sum over histories”. ), this goes by a familiar name in representation theory: restriction and induction. So, given a representation
), this goes by a familiar name in representation theory: restriction and induction. So, given a representation  of
of  , which is just the same representation space, acted on only by elements of
, which is just the same representation space, acted on only by elements of  of
of  , which is to say
, which is to say  . The fact that these operations are adjoints goes in representation theory by the name “Frobenius reciprocity”.
. The fact that these operations are adjoints goes in representation theory by the name “Frobenius reciprocity”. ).
).![\mathbb{C}[G] \otimes_{\mathbb{C}[H]} V](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BG%5D+%5Cotimes_%7B%5Cmathbb%7BC%7D%5BH%5D%7D+V&bg=ffffff&fg=29303b&s=0&c=20201002) , where
, where ![\mathbb{C}[G]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BG%5D&bg=ffffff&fg=29303b&s=0&c=20201002) with
with 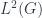 , and likewise for
, and likewise for 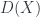 is described concretely in terms of chain complexes of sheaves in
is described concretely in terms of chain complexes of sheaves in 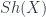 , taken “up to homotopy” – it is a sort of categorification of cohomology. But of course, this contains
, taken “up to homotopy” – it is a sort of categorification of cohomology. But of course, this contains 
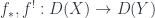 (in general right adjoint to
(in general right adjoint to  and
and 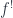 )
) and
and 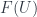 to be the direct sum of all the vector spaces at each object in any subset
to be the direct sum of all the vector spaces at each object in any subset 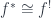 and
and  : these functors are \textit{ambiadjoint} (ie. both left and right adjoint). We use this to define the effect of
: these functors are \textit{ambiadjoint} (ie. both left and right adjoint). We use this to define the effect of 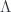 on 2-morphisms in
on 2-morphisms in  .
.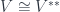 . That’s because the functors
. That’s because the functors 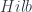 , since Hilbert spaces do have that property. That’s why, in the case of smooth groupoids (say, Lie groupoids), we end up talking about “(measurable) equivariant Hilbert bundles”. (In particular, the ring of functions over which our sheaves are modules is: the measurable ones. Why this is the right choice would be a bit of a digression, but roughly it’s analogous to the fact that
, since Hilbert spaces do have that property. That’s why, in the case of smooth groupoids (say, Lie groupoids), we end up talking about “(measurable) equivariant Hilbert bundles”. (In particular, the ring of functions over which our sheaves are modules is: the measurable ones. Why this is the right choice would be a bit of a digression, but roughly it’s analogous to the fact that 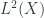 is a space of measurable functions. This is the limitation on which representations we want that I alluded to above.).
is a space of measurable functions. This is the limitation on which representations we want that I alluded to above.). is the universal 2-category faithfully containing
is the universal 2-category faithfully containing 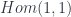 – that is, a span of maps of spans from the terminal groupoid to itself. In other words, degroupoidification is an example something we can do between ANY pair of groupoids – but in the special case where the representation theory all becomes trivial. (This by no means makes it uninteresting: in fact, it’s a perfect setting to understand almost everything else about the subject).
– that is, a span of maps of spans from the terminal groupoid to itself. In other words, degroupoidification is an example something we can do between ANY pair of groupoids – but in the special case where the representation theory all becomes trivial. (This by no means makes it uninteresting: in fact, it’s a perfect setting to understand almost everything else about the subject).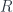 -modules for some ring
-modules for some ring  , even when the action isn’t free). So one thing I’d like to know, but currently don’t is: how is it that this is “secretly” the same thing as the Nakayama isomorphism?
, even when the action isn’t free). So one thing I’d like to know, but currently don’t is: how is it that this is “secretly” the same thing as the Nakayama isomorphism?
 ) is an ETQFT. The construction of the 2-functor uses the fact that you can get spans of groupoids out of cospans of manifolds – and in particular, out of cobordisms. One problem is how to describe
) is an ETQFT. The construction of the 2-functor uses the fact that you can get spans of groupoids out of cospans of manifolds – and in particular, out of cobordisms. One problem is how to describe  so that this works. It’s actually most naturally a cubical 2-category of some kind. The strict version of this concept is a double category – which has (in principle separate) categories of horizontal and vertical of morphisms, as well as square 2-cells. Ideally, one would like a “weak” version, where composition of squares and morphisms can be only weakly associative (and have weak unit laws). A “pseudocategory” implements this where the only higher-dimensional morphisms are the squares, but it turns out to be strict in one direction, and weak in the other. As it happens, it’s a big pain to use only squares for the 2-morphisms.
so that this works. It’s actually most naturally a cubical 2-category of some kind. The strict version of this concept is a double category – which has (in principle separate) categories of horizontal and vertical of morphisms, as well as square 2-cells. Ideally, one would like a “weak” version, where composition of squares and morphisms can be only weakly associative (and have weak unit laws). A “pseudocategory” implements this where the only higher-dimensional morphisms are the squares, but it turns out to be strict in one direction, and weak in the other. As it happens, it’s a big pain to use only squares for the 2-morphisms.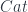 , the category of categories – for any two elements, there’s a whole hom-category of morphisms (and 2-morphisms). A double category is a category internal to
, the category of categories – for any two elements, there’s a whole hom-category of morphisms (and 2-morphisms). A double category is a category internal to  “. In the paper as it stands, that’s all I say. What I cut out was a sort of dangling loose end pointing toward
“. In the paper as it stands, that’s all I say. What I cut out was a sort of dangling loose end pointing toward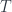 which is the “theory” of such objects, while the functor is a “model” of the theory.
which is the “theory” of such objects, while the functor is a “model” of the theory. for all
for all  and so on. For a category or bicategory, multiplication might be partial – so we need finite limits. A model of a theory in this doctrine is a limit-preserving functor.
and so on. For a category or bicategory, multiplication might be partial – so we need finite limits. A model of a theory in this doctrine is a limit-preserving functor.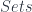 “, and reproduce the usual definition, omitting reference to sets. It has objects
“, and reproduce the usual definition, omitting reference to sets. It has objects 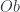 ,
, 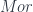 , and
, and  . (This fact already means this is a “multi-sorted” theory, which goes beyond what can be done with another approach to universal algebra based on monads). Funthermore, there are maps between these objects, interpreted as source, target, and identity maps of various sorts. These form diagrams, and since we’re in a finite limit theory, there must be various objects like
. (This fact already means this is a “multi-sorted” theory, which goes beyond what can be done with another approach to universal algebra based on monads). Funthermore, there are maps between these objects, interpreted as source, target, and identity maps of various sorts. These form diagrams, and since we’re in a finite limit theory, there must be various objects like 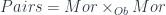 which for sets would have the interpretation “pairs of composable morphisms”. Then there’s a composition map
which for sets would have the interpretation “pairs of composable morphisms”. Then there’s a composition map  … and so on. In short, in describing the axioms for a bicategory in a “nice” way (i.e. in terms of arrows, commuting diagrams, etc.), we’re giving a presentation of a certain category,
… and so on. In short, in describing the axioms for a bicategory in a “nice” way (i.e. in terms of arrows, commuting diagrams, etc.), we’re giving a presentation of a certain category,  , in generators and relations. Then a model of the theory is a functor
, in generators and relations. Then a model of the theory is a functor  – picking out a “bicategory in
– picking out a “bicategory in  , we have:
, we have: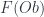 , latex $F(Mor)$, and
, latex $F(Mor)$, and 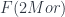
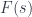 ,
,  and so on
and so on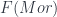 and
and  , where
, where  . One can actually think of this in terms of internalization: these are spans in a category whose objects are spans in
. One can actually think of this in terms of internalization: these are spans in a category whose objects are spans in  in
in  , and so forth. Maybe doing this as weakly as possible would give this tower of increasing weakness.
, and so forth. Maybe doing this as weakly as possible would give this tower of increasing weakness. has a very multivariable-calculus feel to it: you think of curves passing through a point, parametrized by arclength. The have a moving orthogonal frame attached: unit tangent vector, its derivative, and their cross-product. The derivative of the unit tangent is always orthogonal (it’s not changing length), so you can imagine it to be the radius of a circle, with length
has a very multivariable-calculus feel to it: you think of curves passing through a point, parametrized by arclength. The have a moving orthogonal frame attached: unit tangent vector, its derivative, and their cross-product. The derivative of the unit tangent is always orthogonal (it’s not changing length), so you can imagine it to be the radius of a circle, with length  , the radius of curvature. Then you have
, the radius of curvature. Then you have 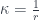 curvature along that path. At any given point on a surface, you get two degrees of freedom – locally, the curve looks like a hyperboloid or an ellipse, or whatever, so there’s actually a curvature form. The determinant gives the Gaussian curvature
curvature along that path. At any given point on a surface, you get two degrees of freedom – locally, the curve looks like a hyperboloid or an ellipse, or whatever, so there’s actually a curvature form. The determinant gives the Gaussian curvature 