I’ve written here before about building topological quantum field theories using groupoidification, but I haven’t yet gotten around to discussing a refinement of this idea, which is in the most recent version of my paper on the subject. I also gave a talk about this last year in Erlangen. The main point of the paper is to pull apart some constructions which are already fairly well known into two parts, as part of setting up a category which is nice for supporting models of fairly general physical systems, using an extension of the concept of groupoidification. So here’s a somewhat lengthy post which tries to unpack this stuff a bit.
Factoring TQFT
The older version of this paper talked about the untwisted version of the Dijkgraaf-Witten (DW for short) model, which is a certain kind of TQFT based on a gauge theory with a finite gauge group. (Freed and Quinn put it as: “Chern-Simons theory with finite gauge group”). The new version gets the general – that is, the twisted – form in the same way: factoring the theory into two parts. So, the DW model, which was originally described by Dijkgraaf and Witten in terms of a state-sum, is a functor
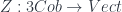
The “twisting” is the point of their paper, “Topological Gauge Theories and Group Cohomology”. The twisting has to do with the action for some physical theory. Now, for a gauge theory involving flat connections, the kind of gauge-theory actions which involve the curvature of a connection make no sense: the curvature is zero. So one wants an action which reflects purely global features of connections. The cohomology of the gauge group is where this comes from.
Now, the machinery I describe is based on a point of view which has been described in a famous paper by Freed, Hopkins, Lurie and Teleman (FHLT for short – see further discussion here) in terms in which the two stages are called the “classical field theory” (which has values in groupoids), and the “quantization functor”, which takes one into Hilbert spaces.
Actually, we really want to have an “extended” TQFT: a TQFT gives a Hilbert space for each 2D manifold (“space”), and a linear map for a 3D cobordism (“spacetime”) between them. An extended TQFT will assign (higher) algebraic data to lower-dimension boundaries still. My paper talks only about the case where we’ve extended down to codimension 2, whereas FHLT talk about extending “down to a point”. The point of this first stopping point is to unpack explicitly and computationally what the factorization into two parts looks like at the first level beyond the usual TQFT.
In the terminology I use, the classical field theory is:
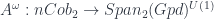
This depends on a cohomology class ![[\omega] \in H^3(G,U(1))](https://s0.wp.com/latex.php?latex=%5B%5Comega%5D+%5Cin+H%5E3%28G%2CU%281%29%29&bg=ffffff&fg=29303b&s=0&c=20201002) . The “quantization functor” (which in this case I call “2-linearization”):
. The “quantization functor” (which in this case I call “2-linearization”):
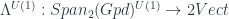
The middle stage involves the monoidal 2-category I call  . (In FHLT, they use different terminology, for instance “families” rather than “spans”, but the principle is the same.)
. (In FHLT, they use different terminology, for instance “families” rather than “spans”, but the principle is the same.)
Freed and Quinn looked at the quantization of the “extended” DW model, and got a nice geometric picture. In it, the action is understood as a section of some particular line-bundle over a moduli space. This geometric picture is very elegant once you see how it works, which I found was a little easier in light of a factorization through  .
.
This factorization isolates the geometry of this particular situation in the “classical field theory” – and reveals which of the features of their setup (the line bundle over a moduli space) are really part of some more universal construction.
In particular, this means laying out an explicit definition of both and 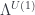 .
.
2-Linearization Recalled
While I’ve talked about it before, it’s worth a brief recap of how 2-linearization works with a view to what happens when you twist it via groupoid cohomology. Here we have a 2-category 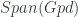 , whose objects are groupoids (
, whose objects are groupoids ( ,
,  , etc.), whose morphisms are spans of groupoids:
, etc.), whose morphisms are spans of groupoids:

and whose 2-morphisms are spans of span-maps (taken up to isomorphism), which look like so:

(And, by the by: how annoying that WordPress doesn’t appear to support xypic figures…)
These form a (symmetric monoidal) 2-category, where composition of spans works by taking weak pullbacks. Physically, the idea is that a groupoid has objects which are configurations (in the cause of gauge theory, connections on a manifold), and morphisms which are symmetries (gauge transformations, in this case). Then a span is a groupoid of histories (connections on a cobordism, thought of as spacetime), and the maps  pick out its starting and ending configuration. That is,
pick out its starting and ending configuration. That is, 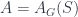 is the groupoid of flat
is the groupoid of flat 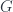 -connections on a manifold
-connections on a manifold 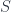 , and
, and  is the groupoid of flat -connections on some cobordism
is the groupoid of flat -connections on some cobordism 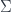 , of which is part of the boundary. So any such connection can be restricted to the boundary, and this restriction is
, of which is part of the boundary. So any such connection can be restricted to the boundary, and this restriction is  .
.
Now 2-linearization is a 2-functor:

It gives a 2-vector space (a nice kind of category) for each groupoid . Specifically, the category of its representations,  . Then a span turns into a functor which comes from “pulling” back along (the restricted representation where
. Then a span turns into a functor which comes from “pulling” back along (the restricted representation where  acts by first applying then the representation), then “pushing” forward along
acts by first applying then the representation), then “pushing” forward along 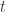 (to the induced representation).
(to the induced representation).
What happens to the 2-morphisms is conceptually more complicated, but it depends on the fact that “pulling” and “pushing” are two-sided adjoints. Concretely, it ends up being described as a kind of “sum over histories” (where “histories” are the objects of 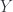 ), which turns out to be exactly the path integral that occurs in the TQFT.
), which turns out to be exactly the path integral that occurs in the TQFT.
Or at least, it’s the path integral when the action is trivial! That is, if  , so that what’s integrated over paths (“histories”) is just
, so that what’s integrated over paths (“histories”) is just  . So one question is: is there a way to factor things in this way if there’s a nontrivial action?
. So one question is: is there a way to factor things in this way if there’s a nontrivial action?
Cohomological Twisting
The answer is by twisting via cohomology. First, let’s remember what that means…
We’re talking about groupoid cohomology for some groupoid (which you can take to be a group, if you like). “Cochains” will measure how much some nice algebraic fact, such as being a homomorphism, or being associative, “fails to occur”. “Twisting by a cocycle” is a controlled way to force some such failure to happen.
So, an  -cocycle is some function of composable morphisms of (or, if there’s only one object, “group elements”, which amounts to the same thing). It takes values in some group of coefficients, which for us is always
-cocycle is some function of composable morphisms of (or, if there’s only one object, “group elements”, which amounts to the same thing). It takes values in some group of coefficients, which for us is always 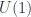 .
.
The trivial case where  is actually slightly subtle: a 0-cocycle is an invariant function on the objects of a groupoid. (That is, it takes the same value on any two objects related by an (iso)morphism. (Think of the object as a sequence of zero composable morphisms: it tells you where to start, but nothing else.)
is actually slightly subtle: a 0-cocycle is an invariant function on the objects of a groupoid. (That is, it takes the same value on any two objects related by an (iso)morphism. (Think of the object as a sequence of zero composable morphisms: it tells you where to start, but nothing else.)
The case  is maybe a little more obvious. A 1-cochain
is maybe a little more obvious. A 1-cochain 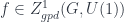 can measure how a function
can measure how a function  on objects might fail to be a 0-cocycle. It is a -valued function of morphisms (or, if you like, group elements). The natural condition to ask for is that it be a homomorphism:
on objects might fail to be a 0-cocycle. It is a -valued function of morphisms (or, if you like, group elements). The natural condition to ask for is that it be a homomorphism:
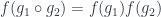
This condition means that a cochain  is a cocycle. They form an abelian group, because functions satisfying the cocycle condition are closed under pointwise multiplication in . It will automatically by satisfied for a coboundary (i.e. if comes from a function on objects as
is a cocycle. They form an abelian group, because functions satisfying the cocycle condition are closed under pointwise multiplication in . It will automatically by satisfied for a coboundary (i.e. if comes from a function on objects as  ). But not every cocycle is a coboundary: the first cohomology
). But not every cocycle is a coboundary: the first cohomology 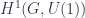 is the quotient of cocycles by coboundaries. This pattern repeats.
is the quotient of cocycles by coboundaries. This pattern repeats.
It’s handy to think of this condition in terms of a triangle with edges 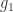 ,
,  , and
, and  . It says that if we go from the source to the target of the sequence
. It says that if we go from the source to the target of the sequence  with or without composing, and accumulate -values, our gives the same result. Generally, a cocycle is a cochain satisfying a “coboundary” condition, which can be described in terms of an -simplex, like this triangle. What about a 2-cocycle? This describes how composition might fail to be respected.
with or without composing, and accumulate -values, our gives the same result. Generally, a cocycle is a cochain satisfying a “coboundary” condition, which can be described in terms of an -simplex, like this triangle. What about a 2-cocycle? This describes how composition might fail to be respected.
So, for instance, a twisted representation 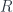 of a group is not a representation in the strict sense. That would be a map into
of a group is not a representation in the strict sense. That would be a map into  , such that
, such that  . That is, the group composition rule gets taken directly to the corresponding rule for composition of endomorphisms of the vector space
. That is, the group composition rule gets taken directly to the corresponding rule for composition of endomorphisms of the vector space 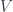 . A twisted representation
. A twisted representation 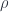 only satisfies this up to a phase:
only satisfies this up to a phase:

where 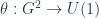 is a function that captures the way this “representation” fails to respect composition. Still, we want some nice properties:
is a function that captures the way this “representation” fails to respect composition. Still, we want some nice properties: 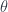 is a “cocycle” exactly when this twisting still makes respect the associative law:
is a “cocycle” exactly when this twisting still makes respect the associative law:

Working out what this says in terms of , the cocycle condition says that for any composable triple 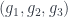 we have:
we have:

So 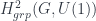 – the second group-cohomology group of – consists of exactly these which satisfy this condition, which ensures we have associativity.
– the second group-cohomology group of – consists of exactly these which satisfy this condition, which ensures we have associativity.
Given one of these maps, we get a category  of all the -twisted representations of . It behaves just like an ordinary representation category… because in fact it is one! It’s the category of representations of a twisted version of the group algebra of , called
of all the -twisted representations of . It behaves just like an ordinary representation category… because in fact it is one! It’s the category of representations of a twisted version of the group algebra of , called 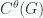 . The point is, we can use to twist the convolution product for functions on , and this is still an associative algebra just because satisfies the cocycle condition.
. The point is, we can use to twist the convolution product for functions on , and this is still an associative algebra just because satisfies the cocycle condition.
The pattern continues: a 3-cocycle captures how some function of 2 variable may fail to be associative: it specifies an associator map (a function of three variables), which has to satisfy some conditions for any four composable morphisms. A 4-cocycle captures how a map might fail to satisfy this condition, and so on. At each stage, the cocycle condition is automatically satisfied by coboundaries. Cohomology classes are elements of the quotient of cocycles by coboundaries.
So the idea of “twisted 2-linearization” is that we use this sort of data to change 2-linearization.
Twisted 2-Linearization
The idea behind the 2-category 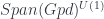 is that it contains , but that objects and morphisms also carry information about how to “twist” when applying the 2-linearization
is that it contains , but that objects and morphisms also carry information about how to “twist” when applying the 2-linearization 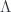 . So in particular, what we have is a (symmetric monoidal) 2-category where:
. So in particular, what we have is a (symmetric monoidal) 2-category where:
- Objects consist of
 , where is a groupoid and $\theta \in Z^2(A,U(1))$
, where is a groupoid and $\theta \in Z^2(A,U(1))$
- Morphisms from to consist of a span
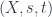 from to , together with
from to , together with 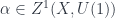
- 2-Morphisms from
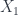 to
to 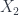 consist of a span
consist of a span  from , together with
from , together with 
The cocycles have to satisfy some compatibility conditions (essentially, pullbacks of the cocycles from the source and target of a span should land in the same cohomology class). One way to see the point of this requirement is to make twisted 2-linearization well-defined.
One can extend the monoidal structure and composition rules to objects with cocycles without too much trouble so that is a subcategory of . The 2-linearization functor extends to 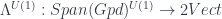 :
:
- On Objects:
 , the category of -twisted representation of
, the category of -twisted representation of
- On Morphisms:
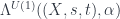 comes by pulling back a twisted representation in
comes by pulling back a twisted representation in  to one in
to one in  , pulling it through the algebra map “multiplication by
, pulling it through the algebra map “multiplication by 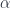 “, and pushing forward to
“, and pushing forward to 
- On 2-Morphisms: For a span of span maps, one uses the usual formula (see the paper for details), but a sum over the objects
 picks up a weight of
picks up a weight of  at each object
at each object
When the cocycles are trivial (evaluate to 1 always), we get back the 2-linearization we had before. Now the main point here is that the “sum over histories” that appears in the 2-morphisms now carries a weight.
So the twisted form of 2-linearization uses the same “pull-push” ideas as 2-linearization, but applied now to twisted representations. This twisting (at the object level) uses a 2-cocycle. At the morphism level, we have a “twist” between “pull” and “push” in constructing . What the “twist” actually means depends on which cohomology degree we’re in – in other words, whether it’s applied to objects, morphisms, or 2-morphisms.
The “twisting” by a 0-cocycle just means having a weight for each object – in other words, for each “history”, or connection on spacetime, in a big sum over histories. Physically, the 0-cocycle is playing the role of the Lagrangian functional for the DW model. Part of the point in the FHLT program can be expressed by saying that what Freed and Quinn are doing is showing how the other cocycles are also the Lagrangian – as it’s seen at higher codimension in the more “local” theory.
For a TQFT, the 1-cocycles associated to morphisms describe how to glue together values for the Lagrangian that are associated to histories that live on different parts of spacetime: the action isn’t just a number. It is a number only “locally”, and when we compose 2-morphisms, the 0-cocycle on the composite picks up a factor from the 1-morphism (or 0-morphism, for a horizontal composite) where they’re composed.
This has to do with the fact that connections on bits of spacetime can be glued by particular gauge transformations – that is, morphisms of the groupoid of connections. Just as the gauge transformations tell how to glue connections, the cocycles associated to them tell how to glue the actions. This is how the cohomological twisting captures the geometric insight that the action is a section of a line bundle – not just a function, which is a section of a trivial bundle – over the moduli space of histories.
So this explains how these cocycles can all be seen as parts of the Lagrangian when we quantize: they explain how to glue actions together before using them in a sum-over histories. Gluing them this way is essential to make sure that is actually a functor. But if we’re really going to see all the cocycles as aspects of “the action”, then what is the action really? Where do they come from, that they’re all slices of this bigger thing?
Twisting as Lagrangian
Now the DW model is a 3D theory, whose action is specified by a group-cohomology class ![[\omega] \in H^3_{grp}(G,U(1))](https://s0.wp.com/latex.php?latex=%5B%5Comega%5D+%5Cin+H%5E3_%7Bgrp%7D%28G%2CU%281%29%29&bg=ffffff&fg=29303b&s=0&c=20201002) . But this is the same thing as a class in the cohomology of the classifying space:
. But this is the same thing as a class in the cohomology of the classifying space: ![[\omega] \in H^3(BG,U(1))](https://s0.wp.com/latex.php?latex=%5B%5Comega%5D+%5Cin+H%5E3%28BG%2CU%281%29%29&bg=ffffff&fg=29303b&s=0&c=20201002) . This takes a little unpacking, but certainly it’s helpful to understand that what cohomology classes actually classify are… gerbes. So another way to put a key idea of the FHLT paper, as Urs Schreiber put it to me a while ago, is that “the action is a gerbe on the classifying space for fields“.
. This takes a little unpacking, but certainly it’s helpful to understand that what cohomology classes actually classify are… gerbes. So another way to put a key idea of the FHLT paper, as Urs Schreiber put it to me a while ago, is that “the action is a gerbe on the classifying space for fields“.
What does this mean?
This map is given as a path integral over all connections on the space(-time) , which is actually just a sum, since the gauge group is finite and so all the connections are flat. The point is that they’re described by assigning group elements to loops in :
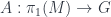
But this amounts to the same thing as a map into the classifying space of :

This is essentially the definition of 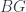 , and it implies various things, such as the fact that is a space whose fundamental group is , and has all other homotopy groups trivial. That is, is the Eilenberg-MacLane space
, and it implies various things, such as the fact that is a space whose fundamental group is , and has all other homotopy groups trivial. That is, is the Eilenberg-MacLane space 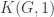 . But the point is that the groupoid of connections and gauge transformations on just corresponds to the mapping space
. But the point is that the groupoid of connections and gauge transformations on just corresponds to the mapping space  . So the groupoid cohomology classes we get amount to the same thing as cohomology classes on this space. If we’re given , then we can get at these by “transgression” – which is very nicely explained in a paper by Simon Willerton.
. So the groupoid cohomology classes we get amount to the same thing as cohomology classes on this space. If we’re given , then we can get at these by “transgression” – which is very nicely explained in a paper by Simon Willerton.
The essential idea is that a 3-cocycle  (representing the class
(representing the class ![[\omega]](https://s0.wp.com/latex.php?latex=%5B%5Comega%5D&bg=ffffff&fg=29303b&s=0&c=20201002) ) amounts to a nice 3-form on which we can integrate over a 3-dimentional submanifold to get a number. For a
) amounts to a nice 3-form on which we can integrate over a 3-dimentional submanifold to get a number. For a  -dimensional , we get such a 3-manifold from a
-dimensional , we get such a 3-manifold from a  -dimensional submanifold of : each point gives a copy of in . Then we get a -cocycle on whose values come from integrating over this image. Here’s a picture I used to illustrate this in my talk:
-dimensional submanifold of : each point gives a copy of in . Then we get a -cocycle on whose values come from integrating over this image. Here’s a picture I used to illustrate this in my talk:

Now, it turns out that this gives 2-cocycles for 1-manifolds (the objects of  , 1-cocycles on 2D cobordisms between them, and 0-cocycles on 3D cobordisms between these cobordisms. The cocycles are for the groupoid of connections and gauge transformations in each case. In fact, because of Stokes’ theorem in , these have to satisfy all the conditions that make them into objects, morphisms, and 2-morphisms of
, 1-cocycles on 2D cobordisms between them, and 0-cocycles on 3D cobordisms between these cobordisms. The cocycles are for the groupoid of connections and gauge transformations in each case. In fact, because of Stokes’ theorem in , these have to satisfy all the conditions that make them into objects, morphisms, and 2-morphisms of 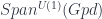 . This is the geometric content of the Lagrangian: all the cocycles are really “reflections” of as seen by transgression: pulling back along the evaluation map
. This is the geometric content of the Lagrangian: all the cocycles are really “reflections” of as seen by transgression: pulling back along the evaluation map  from the picture. Then the way you use it in the quantization is described exactly by .
from the picture. Then the way you use it in the quantization is described exactly by .
What I like about this is that is a fairly universal sort of thing – so while this example gets its cocycles from the nice geometry of which Freed and Quinn talk about, the insight that an action is a section of a (twisted) line bundle, that actions can be glued together in particular ways, and so on… These presumably can be moved to other contexts.
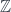



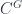
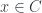
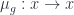


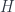
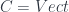
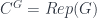

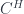

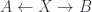
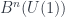

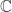
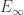
 is the basic one, but there are parallel notions for presheaves valued in categories other than
is the basic one, but there are parallel notions for presheaves valued in categories other than  ” is equivalent to a category of “abelian-group-valued sheaves on
” is equivalent to a category of “abelian-group-valued sheaves on 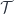 “, denoted
“, denoted 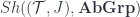 . (As usual, I’ll omit the Grothendieck topology
. (As usual, I’ll omit the Grothendieck topology 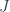 in the notation from now on, though it’s important that it is still there.)
in the notation from now on, though it’s important that it is still there.) , or
, or  , which amounts to the same as the category of abelian group objects in
, which amounts to the same as the category of abelian group objects in  itself. In particular, it’s an abelian category: this gives us that there is a direct sum for objects, a zero object, exact sequences split, all morphisms have kernels and cokernels, and so forth. These useful properties all hold because at each
itself. In particular, it’s an abelian category: this gives us that there is a direct sum for objects, a zero object, exact sequences split, all morphisms have kernels and cokernels, and so forth. These useful properties all hold because at each  , the direct sum of sheaves of abelian group just gives
, the direct sum of sheaves of abelian group just gives 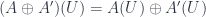 , and all the properties hold locally at each
, and all the properties hold locally at each 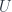 .
. , or sheaves of simplicial sets,
, or sheaves of simplicial sets,  . (Though it’s worth noting that since simplicial sets model infinity-groupoids, there are more sophisticated forms of the sheaf condition which can be applied here. But for now, this isn’t what we need.)
. (Though it’s worth noting that since simplicial sets model infinity-groupoids, there are more sophisticated forms of the sheaf condition which can be applied here. But for now, this isn’t what we need.)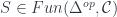 – that is,
– that is,  , the simplex category. This
, the simplex category. This  are the order-preserving functions from
are the order-preserving functions from  to
to  . If
. If  , we get “simplicial sets”, where
, we get “simplicial sets”, where 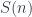 is the “set of
is the “set of 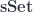 of simplicial sets, i.e. objects of
of simplicial sets, i.e. objects of 
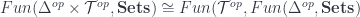
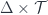 .)
.) is a sequence of Abelian groups with boundary maps
is a sequence of Abelian groups with boundary maps  (or just
(or just 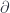 for short), like so:
for short), like so: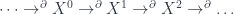
 . Morphisms between these are sequences of morphisms between the terms of the complexes
. Morphisms between these are sequences of morphisms between the terms of the complexes 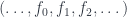 where each
where each  which commute with all the boundary maps. These all assemble into a category of complexes
which commute with all the boundary maps. These all assemble into a category of complexes 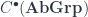 . We also have
. We also have  and
and  , the (full) subcategories of complexes where all the negative (respectively, positive) terms are trivial.
, the (full) subcategories of complexes where all the negative (respectively, positive) terms are trivial. , the category of simplicial objects
, the category of simplicial objects  is equivalent to the category of positive chain complexes
is equivalent to the category of positive chain complexes 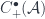 .
.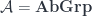 . If
. If  . On objects, it gives the intersection of all the kernels of the face maps:
. On objects, it gives the intersection of all the kernels of the face maps:
 . This ends up satisfying the “boundary-squared is zero” condition because of the identities for the face maps.
. This ends up satisfying the “boundary-squared is zero” condition because of the identities for the face maps.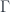 from complexes to simplicial objects in
from complexes to simplicial objects in 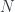 . Indeed,
. Indeed,  the space of smooth differential
the space of smooth differential  , with the exterior derivatives as the coboundary maps. But no matter which complex you start with, there is a sequence of cohomology groups, because we have a sequence of cohomology functors:
, with the exterior derivatives as the coboundary maps. But no matter which complex you start with, there is a sequence of cohomology groups, because we have a sequence of cohomology functors: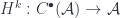
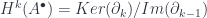
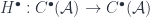 , since there are natural transformations between these functors
, since there are natural transformations between these functors
 to the kernel
to the kernel 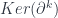 . (In fact, this makes the maps trivial – but the main point is that this restriction is well-defined on equivalence classes, and so we get an actual complex again.) The fact that we get a functor means that any chain map
. (In fact, this makes the maps trivial – but the main point is that this restriction is well-defined on equivalence classes, and so we get an actual complex again.) The fact that we get a functor means that any chain map  gives a corresponding
gives a corresponding 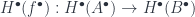 .
. is acyclic if all the
is acyclic if all the  . But of course, this doesn’t mean that the chain itself is zero.
. But of course, this doesn’t mean that the chain itself is zero.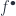 is a quasi-isomorphism if
is a quasi-isomorphism if  is an isomorphism. The idea is that, as far as we can tell from the information that coholomology detects, it might as well be an isomorphism.
is an isomorphism. The idea is that, as far as we can tell from the information that coholomology detects, it might as well be an isomorphism. is a quasi-isomorphism, it is a homotopy equivalence.
is a quasi-isomorphism, it is a homotopy equivalence.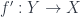 , which means there is a homotopy
, which means there is a homotopy  .
. is a collection of maps which shift degrees,
is a collection of maps which shift degrees,  , such that
, such that  . That is, the coboundary of
. That is, the coboundary of  . (The “co” version of the usual intuition of a homotopy, whose ingoing and outgoing boundaries are the things which are supposed to be homotopic).
. (The “co” version of the usual intuition of a homotopy, whose ingoing and outgoing boundaries are the things which are supposed to be homotopic).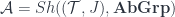 , and even where
, and even where 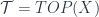 for some reasonably nice space
for some reasonably nice space  of complexes. (This stands in for “spaces in
of complexes. (This stands in for “spaces in  “, so the correct analogy is really with spectra. This is a bit too far afield to get into here, though, so for now let’s just ignore it.)
“, so the correct analogy is really with spectra. This is a bit too far afield to get into here, though, so for now let’s just ignore it.) whenever there is a homotopy
whenever there is a homotopy 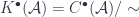 is the quotient by this relation.
is the quotient by this relation. .
.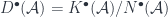 , where
, where  is the category of acyclic complexes – the ones whose cohomology complexes are zero.)
is the category of acyclic complexes – the ones whose cohomology complexes are zero.) ,
,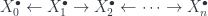
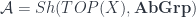 or something similar. In the next post, I’ll talk about Susama’s series of lectures, on the subject of motives. This uses some of the same technology described above, in the specific context of schemes (which introduces some extra considerations specific to that world). It’s aim is to produce a category (and a functor into it) which captures all the cohomological information about spaces – in some sense a universal cohomology theory from which any other can be found.
or something similar. In the next post, I’ll talk about Susama’s series of lectures, on the subject of motives. This uses some of the same technology described above, in the specific context of schemes (which introduces some extra considerations specific to that world). It’s aim is to produce a category (and a functor into it) which captures all the cohomological information about spaces – in some sense a universal cohomology theory from which any other can be found.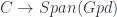 (“model” and “representation” mean essentially the same thing in this context). In fact, for this to make sense, I think of
(“model” and “representation” mean essentially the same thing in this context). In fact, for this to make sense, I think of  whose objects are (oriented) dots and whose morphisms are certain classes of diagrams. The nice fact about the particular model we get is that the reasons these relations hold are easy to see in terms of a the combinatorics of sets. This is why our title describes what we got as “a combinatorial representation” Khovanov’s category
whose objects are (oriented) dots and whose morphisms are certain classes of diagrams. The nice fact about the particular model we get is that the reasons these relations hold are easy to see in terms of a the combinatorics of sets. This is why our title describes what we got as “a combinatorial representation” Khovanov’s category  of finite sets and bijections (which we just called
of finite sets and bijections (which we just called 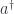 and
and  – and their categorified equivalents,
– and their categorified equivalents,  . The spans that represent them are very simple: they are processes which put a new ball into the box, or take one out, respectively. (Algebraically, they’re just a way to organize all the inclusions of symmetric groups
. The spans that represent them are very simple: they are processes which put a new ball into the box, or take one out, respectively. (Algebraically, they’re just a way to organize all the inclusions of symmetric groups 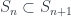 .)
.)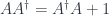
 ) than to remove a ball and then add a new one (histories for
) than to remove a ball and then add a new one (histories for  ). This is fairly obvious: in the first instance, you have one more to choose from when removing the ball.
). This is fairly obvious: in the first instance, you have one more to choose from when removing the ball.
 and then remove
and then remove  . The first case is that
. The first case is that  : we remove the same ball we put in. This amounts to doing nothing, so the first part of the movie eliminates all the adding and removing. The second part puts the add-remove pair back in.
: we remove the same ball we put in. This amounts to doing nothing, so the first part of the movie eliminates all the adding and removing. The second part puts the add-remove pair back in. , since it takes the initial history to the history (of a different process!) in which we remove
, since it takes the initial history to the history (of a different process!) in which we remove  , since we can’t remove this ball before adding it). This in turn is taken to the history (of the original process!) where we add
, since we can’t remove this ball before adding it). This in turn is taken to the history (of the original process!) where we add 
 and
and  and counit
and counit  satisfying some nice relations. In fact, this only makes
satisfying some nice relations. In fact, this only makes  – the objects of
– the objects of 
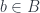 . We can do the same thing in any category with pullbacks, not just
. We can do the same thing in any category with pullbacks, not just 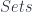 .
.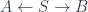 is a relation if the pair of arrows is “jointly monic”, which is to say that as a map
is a relation if the pair of arrows is “jointly monic”, which is to say that as a map 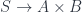 , it is a monomorphism – which, since we’re talking about sets, essentially means “a subset”. That is, up to isomorphism of spans,
, it is a monomorphism – which, since we’re talking about sets, essentially means “a subset”. That is, up to isomorphism of spans, 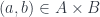 , which are the “related” pairs in this relation. So there is an inclusion
, which are the “related” pairs in this relation. So there is an inclusion 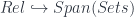 . What’s more the inclusion has a left adjoin, which turns a span into a corresponding relation. It follows from the fact that
. What’s more the inclusion has a left adjoin, which turns a span into a corresponding relation. It follows from the fact that  that comes from the span (and the definition of product) will factor through the image. That is, it is the composite
that comes from the span (and the definition of product) will factor through the image. That is, it is the composite 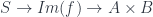 , where the first part is surjective, and the second part is injective. Then the inclusion
, where the first part is surjective, and the second part is injective. Then the inclusion  is a relation. So we say the inclusion of
is a relation. So we say the inclusion of 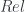 into
into  is a reflection. (This is a slightly misleading term: there’s an adjoint to the inclusion, but it’s not an adjoint equivalence. “Reflecting” twice may not get you back where you started, or anywhere isomorphic to it.)
is a reflection. (This is a slightly misleading term: there’s an adjoint to the inclusion, but it’s not an adjoint equivalence. “Reflecting” twice may not get you back where you started, or anywhere isomorphic to it.)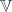 is a monoidal category, and
is a monoidal category, and 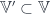 is a “
is a “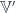 into a monoidal category just by defining
into a monoidal category just by defining 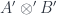 (the product in
(the product in 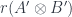 of the original product? This is the one-object version of a question about bicategories. Namely, say that
of the original product? This is the one-object version of a question about bicategories. Namely, say that 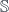 is a bicategory, and
is a bicategory, and 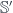 is a sub-bicategory such that every pair of objects gives a reflective subcategory:
is a sub-bicategory such that every pair of objects gives a reflective subcategory: 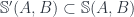 has a reflection. Then can we “pull” the composition of morphisms in
has a reflection. Then can we “pull” the composition of morphisms in 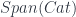 and some reflective subcategory – among other possible examples – associativity and unit axioms will break, unless the reflections
and some reflective subcategory – among other possible examples – associativity and unit axioms will break, unless the reflections  are specially tuned. This isn’t to say that we can’t make
are specially tuned. This isn’t to say that we can’t make 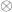 or
or  along the reflection won’t work. But there is a theorem that says we can always promote such an inclusion into one where this works.
along the reflection won’t work. But there is a theorem that says we can always promote such an inclusion into one where this works.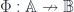 from a category
from a category 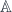 to
to 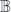 is actually a functor
is actually a functor 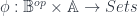 . Then there’s a bicategory
. Then there’s a bicategory 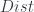 , where for each objects there’s a category
, where for each objects there’s a category  . Distributors represent, in some sense, a categorification of relations. (This observation follows the
. Distributors represent, in some sense, a categorification of relations. (This observation follows the 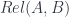 , and each one is a map from
, and each one is a map from  into truth values, specifying whether a pair
into truth values, specifying whether a pair 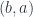 is related.)
is related.)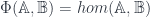 , which is indeed covariant in
, which is indeed covariant in 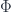 obviously determines a functor from
obviously determines a functor from 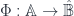 , where
, where  is the category
is the category 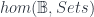 .
.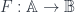 , we can define two different distributors:
, we can define two different distributors: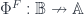 with
with 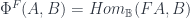
 with
with 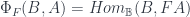
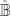 can be interpreted as a category of “big objects of
can be interpreted as a category of “big objects of 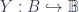 embeds
embeds 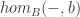 which assigns each object the set of morphisms into
which assigns each object the set of morphisms into  , so
, so  along
along  is cocomplete, so that we can basically “add up” contributions from the objects of
is cocomplete, so that we can basically “add up” contributions from the objects of  for some other category
for some other category 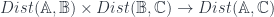 .
. (the image of
(the image of  into
into 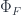 . So we’ve embedded
. So we’ve embedded  as a tricategory, which contains
as a tricategory, which contains 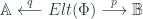
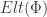 consists of all the “elements of
consists of all the “elements of 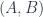 and the set maps that come from morphisms between them in
and the set maps that come from morphisms between them in 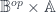 ). (As an aside: Benabou also explained how a cospan,
). (As an aside: Benabou also explained how a cospan, 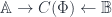 can be got from a distributor. The objects of
can be got from a distributor. The objects of 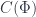 are just the disjoint union of those from
are just the disjoint union of those from  end up having some special properties that result from how they’re constructed. In particular,
end up having some special properties that result from how they’re constructed. In particular,  will be an op-fibration and
will be an op-fibration and  will be a fibration (this, for instance, is alifting property that let one lift morphisms – since the morphisms are found as the images of the original distributor, this makes sense). Also, the fibres of
will be a fibration (this, for instance, is alifting property that let one lift morphisms – since the morphisms are found as the images of the original distributor, this makes sense). Also, the fibres of  are discrete (these are by definition the images of identity morphisms, so naturally they’re discrete categories). Finally, these properties (fibration, op-fibration, and discrete fibres) are enough to guarantee that a given span is (isomorphic to) one that comes from a distributor. So we have an embedding
are discrete (these are by definition the images of identity morphisms, so naturally they’re discrete categories). Finally, these properties (fibration, op-fibration, and discrete fibres) are enough to guarantee that a given span is (isomorphic to) one that comes from a distributor. So we have an embedding 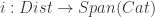 .
.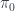 – the connected components. The other properties will then follow. But notice that this is a very nontrivial thing to do: in general, the fibres of
– the connected components. The other properties will then follow. But notice that this is a very nontrivial thing to do: in general, the fibres of  and
and 

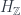 ) in terms of a diagrammatic calculus. This is very much in the spirit of the Khovanov-Lauda program of categorifying Lie algebras, quantum groups, and the like. (There’s also
) in terms of a diagrammatic calculus. This is very much in the spirit of the Khovanov-Lauda program of categorifying Lie algebras, quantum groups, and the like. (There’s also  . Since I’ve already discussed the backgroup here before (e.g.
. Since I’ve already discussed the backgroup here before (e.g.  making everything commute). It’s got a monoidal structure, is additive in a fairly natural way, has duals for morphisms (by reversing the orientation of spans), and more. Jamie Vicary and I are both interested in the quantum harmonic oscillator – he did
making everything commute). It’s got a monoidal structure, is additive in a fairly natural way, has duals for morphisms (by reversing the orientation of spans), and more. Jamie Vicary and I are both interested in the quantum harmonic oscillator – he did ![P_n = \mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=P_n+%3D+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) . In fact, there’s a version of this algebra for each natural number
. In fact, there’s a version of this algebra for each natural number 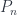 generated by the “raising” operators
generated by the “raising” operators 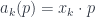 and the “lowering” operators
and the “lowering” operators 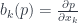 . The point is that this is characterized by some commutation relations. For
. The point is that this is characterized by some commutation relations. For 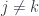 , we have:
, we have:![[a_j,a_k] = [b_j,b_k] = [a_j,b_k] = 0](https://s0.wp.com/latex.php?latex=%5Ba_j%2Ca_k%5D+%3D+%5Bb_j%2Cb_k%5D+%3D+%5Ba_j%2Cb_k%5D+%3D+0&bg=ffffff&fg=29303b&s=0&c=20201002)
![[a_k,b_k] = 1](https://s0.wp.com/latex.php?latex=%5Ba_k%2Cb_k%5D+%3D+1&bg=ffffff&fg=29303b&s=0&c=20201002)
 with these relations. These can be understood to be the “raising and lowering” operators for an
with these relations. These can be understood to be the “raising and lowering” operators for an ![[p_k,q_k] = i](https://s0.wp.com/latex.php?latex=%5Bp_k%2Cq_k%5D+%3D+i&bg=ffffff&fg=29303b&s=0&c=20201002) (as in
(as in  ) has a slightly different interpretation, where the
) has a slightly different interpretation, where the 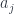 with a different set of
with a different set of 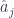 so that the commutation relation actually looks like
so that the commutation relation actually looks like![[\hat{a}_j,b_k] = b_{k-1}\hat{a}_{j-1}](https://s0.wp.com/latex.php?latex=%5B%5Chat%7Ba%7D_j%2Cb_k%5D+%3D+b_%7Bk-1%7D%5Chat%7Ba%7D_%7Bj-1%7D&bg=ffffff&fg=29303b&s=0&c=20201002)
 .)
.)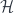 whose isomorphism classes of objects correspond to (integer-) linear combinations of products of the generators of
whose isomorphism classes of objects correspond to (integer-) linear combinations of products of the generators of  , represents Fock space. Groupoidification turns this into the free vector space on the set of isomorphism classes of objects. This has some extra structure which we don’t need right now, so it makes the most sense to describe it as
, represents Fock space. Groupoidification turns this into the free vector space on the set of isomorphism classes of objects. This has some extra structure which we don’t need right now, so it makes the most sense to describe it as ![\mathbb{C}[[t]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5B%5Bt%5D%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , the space of power series (where
, the space of power series (where 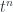 corresponds to the object
corresponds to the object ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=29303b&s=0&c=20201002) ). The algebra itself is an algebra of endomorphisms of this space. It’s this algebra Khovanov is looking at, so the monoidal category in question could really be considered a bicategory with one object, where the monoidal product comes from composition, and the object stands in formally for the space it acts on. But this space doesn’t enter into the description, so we’ll just think of
). The algebra itself is an algebra of endomorphisms of this space. It’s this algebra Khovanov is looking at, so the monoidal category in question could really be considered a bicategory with one object, where the monoidal product comes from composition, and the object stands in formally for the space it acts on. But this space doesn’t enter into the description, so we’ll just think of  .
.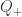 and
and  , and the fact that it’s monoidal (these objects will be the categorifications of
, and the fact that it’s monoidal (these objects will be the categorifications of  and so forth. In general, if
and so forth. In general, if  is some word on the alphabet
is some word on the alphabet  , there’s an object
, there’s an object 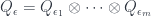 .
. , and connect two such sequences by a bunch of oriented strands (embeddings of the interval, or circle, in the plane). Each
, and connect two such sequences by a bunch of oriented strands (embeddings of the interval, or circle, in the plane). Each 

 -linear combination of these. (I prefer to assume
-linear combination of these. (I prefer to assume  most of the time, since I’m interested in quantum mechanics, but this isn’t strictly necessary.)
most of the time, since I’m interested in quantum mechanics, but this isn’t strictly necessary.) (the commutation relation has become a decomposition of a certain tensor product). The point is that the left hand sides show the composition of two crossings
(the commutation relation has become a decomposition of a certain tensor product). The point is that the left hand sides show the composition of two crossings  and
and 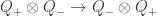 in two different orders. One can use this, plus isotopy, to show the decomposition.
in two different orders. One can use this, plus isotopy, to show the decomposition.
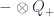 and
and  are two-sided adjoints. The two cups and caps (with each possible orientation) give the units and counits for the two adjunctions. So, for instance, in the zig-zag diagram above, there’s a cup which gives a unit map
are two-sided adjoints. The two cups and caps (with each possible orientation) give the units and counits for the two adjunctions. So, for instance, in the zig-zag diagram above, there’s a cup which gives a unit map  (reading upward), all tensored on the right by
(reading upward), all tensored on the right by  (all tensored on the left by
(all tensored on the left by 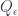 described above. This isn’t quite enough to get a categorification of
described above. This isn’t quite enough to get a categorification of  . To get all the elements of the (integral form of) the Heisenberg algebras, and in particular to get generators that satisfy the right commutation relations, we need to introduce some new objects. There’s a convenient way to do this, though, which is to take the
. To get all the elements of the (integral form of) the Heisenberg algebras, and in particular to get generators that satisfy the right commutation relations, we need to introduce some new objects. There’s a convenient way to do this, though, which is to take the 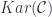 that contains
that contains  such that
such that 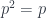 is a projection. That projection corresponds to a subspace
is a projection. That projection corresponds to a subspace  , and
, and  is actually another object in
is actually another object in  , so that
, so that  . This might not happen in any general
. This might not happen in any general 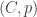 where
where 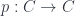 is idempotent (so
is idempotent (so  ). The morphisms
). The morphisms  are just maps
are just maps 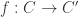 with the compatibility condition that
with the compatibility condition that  (essentially, maps between the new subobjects).
(essentially, maps between the new subobjects).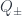 . First, consider
. First, consider  . Obviously, there’s an action of the symmetric group
. Obviously, there’s an action of the symmetric group 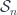 on this, so in fact (since we want a
on this, so in fact (since we want a ![\mathbf{k}[\mathcal{S}_n]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5B%5Cmathcal%7BS%7D_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , the corresponding group algebra. This has a number of different projections, but the relevant ones here are the symmetrizer,:
, the corresponding group algebra. This has a number of different projections, but the relevant ones here are the symmetrizer,:

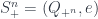 (the symmetrized subobject of
(the symmetrized subobject of  ) is a hollow rectangle, labelled by
) is a hollow rectangle, labelled by  is drawn with
is drawn with 
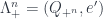 is drawn with a black box instead. There are also
is drawn with a black box instead. There are also  and
and  defined in the same way (and drawn with downward-pointing arrows).
defined in the same way (and drawn with downward-pointing arrows). . The key thing is that there are maps from the left hand side into each of the terms on the right, and the sum can be shown to be an isomorphism using all the previous relations. The map into the second term involves a cap that uses up one of the strands from each term on the left.
. The key thing is that there are maps from the left hand side into each of the terms on the right, and the sum can be shown to be an isomorphism using all the previous relations. The map into the second term involves a cap that uses up one of the strands from each term on the left.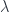 of
of 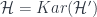 corresponding to all the elements of
corresponding to all the elements of  (symmetrized products of “lowering” strands), and the
(symmetrized products of “lowering” strands), and the 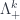 (antisymmetrized products of “raising” strands). We also have isomorphisms (i.e. diagrams that are invertible, using the local moves we’re allowed) for all the relations. This is a categorification of
(antisymmetrized products of “raising” strands). We also have isomorphisms (i.e. diagrams that are invertible, using the local moves we’re allowed) for all the relations. This is a categorification of  . Given such an
. Given such an 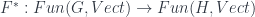 , that just works by composing with
, that just works by composing with  , given by the left and right Kan extension along
, given by the left and right Kan extension along 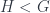 , we get a functors
, we get a functors  , which just considers the obvious action of
, which just considers the obvious action of  , which takes a representation
, which takes a representation ![\mathbf{k}[G] \otimes_{\mathbf{k}[H]} V](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BG%5D+%5Cotimes_%7B%5Cmathbf%7Bk%7D%5BH%5D%7D+V&bg=ffffff&fg=29303b&s=0&c=20201002) , which is a special case of the formula for a Kan extension. (This formula suggests why it’s also natural to see these as functors between module categories
, which is a special case of the formula for a Kan extension. (This formula suggests why it’s also natural to see these as functors between module categories ![\mathbf{k}[G]-mod](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BG%5D-mod&bg=ffffff&fg=29303b&s=0&c=20201002) and
and ![\mathbf{k}[H]-mod](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BH%5D-mod&bg=ffffff&fg=29303b&s=0&c=20201002) ). To talk about the Heisenberg algebra in particular, Khovanov considers these functors for all the symmetric group inclusions
). To talk about the Heisenberg algebra in particular, Khovanov considers these functors for all the symmetric group inclusions 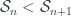 .
.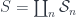 , this is all you need to categorify the Heisenberg algebra. In the
, this is all you need to categorify the Heisenberg algebra. In the  map from
map from  and
and  to
to  . Of course, the second definition implies the first, but not conversely. The objects of the Grothendieck ring are isomorphism classes in
. Of course, the second definition implies the first, but not conversely. The objects of the Grothendieck ring are isomorphism classes in  , and then find that
, and then find that 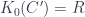 . This seems to be the relation between Khovanov’s categorification of
. This seems to be the relation between Khovanov’s categorification of  , which is “the” one-element set – or, likewise, in
, which is “the” one-element set – or, likewise, in  , from the terminal groupoid, which has only one object and its identity morphism. However, this is a category where the arrows are set maps. When we introduce the idea of a “history “, we’re moving into a category where the arrows are spans,
, from the terminal groupoid, which has only one object and its identity morphism. However, this is a category where the arrows are set maps. When we introduce the idea of a “history “, we’re moving into a category where the arrows are spans,  is still around – only the morphisms in and out are different. Its new special property is that it’s a monoidal unit. So now a map from the monoidal unit is a span
is still around – only the morphisms in and out are different. Its new special property is that it’s a monoidal unit. So now a map from the monoidal unit is a span  . Since the map on the left is unique, by definition of “terminal”, this really just given by the functor
. Since the map on the left is unique, by definition of “terminal”, this really just given by the functor  .
. ), these fibrations are the “stuff types” of Baez and Dolan. This is a groupoid with something of a notion of “underlying set” – although a forgetful functor
), these fibrations are the “stuff types” of Baez and Dolan. This is a groupoid with something of a notion of “underlying set” – although a forgetful functor 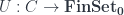 (giving “underlying sets” for objects in a category
(giving “underlying sets” for objects in a category  , where the image of a finite set consists of the set of all “$\Phi$-structured” sets (such as: “graphs on set
, where the image of a finite set consists of the set of all “$\Phi$-structured” sets (such as: “graphs on set  . Notice that the notion of “state” here really depends on what the arrows in the category of states are – histories (i.e. spans), or just plain maps.
. Notice that the notion of “state” here really depends on what the arrows in the category of states are – histories (i.e. spans), or just plain maps.![H = \mathbb{C}[\underline{B}]](https://s0.wp.com/latex.php?latex=H+%3D+%5Cmathbb%7BC%7D%5B%5Cunderline%7BB%7D%5D&bg=ffffff&fg=29303b&s=0&c=20201002) ), which is really what’s defined by one of these ensembles.
), which is really what’s defined by one of these ensembles. , but the concept of state. So it should be a 2-vector in a 2-Hilbert space associated to
, but the concept of state. So it should be a 2-vector in a 2-Hilbert space associated to  . A 2-Hilbert space will be a category of functors into
. A 2-Hilbert space will be a category of functors into  – but as a direct integral of some Hilbert bundle that lives on the space of irreps. Those projections are just part of the definition of such a bundle. The fact that
– but as a direct integral of some Hilbert bundle that lives on the space of irreps. Those projections are just part of the definition of such a bundle. The fact that  for some groupoid
for some groupoid 
 ) is an ETQFT. The construction of the 2-functor uses the fact that you can get spans of groupoids out of cospans of manifolds – and in particular, out of cobordisms. One problem is how to describe
) is an ETQFT. The construction of the 2-functor uses the fact that you can get spans of groupoids out of cospans of manifolds – and in particular, out of cobordisms. One problem is how to describe  so that this works. It’s actually most naturally a cubical 2-category of some kind. The strict version of this concept is a double category – which has (in principle separate) categories of horizontal and vertical of morphisms, as well as square 2-cells. Ideally, one would like a “weak” version, where composition of squares and morphisms can be only weakly associative (and have weak unit laws). A “pseudocategory” implements this where the only higher-dimensional morphisms are the squares, but it turns out to be strict in one direction, and weak in the other. As it happens, it’s a big pain to use only squares for the 2-morphisms.
so that this works. It’s actually most naturally a cubical 2-category of some kind. The strict version of this concept is a double category – which has (in principle separate) categories of horizontal and vertical of morphisms, as well as square 2-cells. Ideally, one would like a “weak” version, where composition of squares and morphisms can be only weakly associative (and have weak unit laws). A “pseudocategory” implements this where the only higher-dimensional morphisms are the squares, but it turns out to be strict in one direction, and weak in the other. As it happens, it’s a big pain to use only squares for the 2-morphisms. “. In the paper as it stands, that’s all I say. What I cut out was a sort of dangling loose end pointing toward
“. In the paper as it stands, that’s all I say. What I cut out was a sort of dangling loose end pointing toward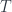 which is the “theory” of such objects, while the functor is a “model” of the theory.
which is the “theory” of such objects, while the functor is a “model” of the theory. for all
for all  and so on. For a category or bicategory, multiplication might be partial – so we need finite limits. A model of a theory in this doctrine is a limit-preserving functor.
and so on. For a category or bicategory, multiplication might be partial – so we need finite limits. A model of a theory in this doctrine is a limit-preserving functor.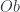 ,
, 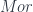 , and
, and  . (This fact already means this is a “multi-sorted” theory, which goes beyond what can be done with another approach to universal algebra based on monads). Funthermore, there are maps between these objects, interpreted as source, target, and identity maps of various sorts. These form diagrams, and since we’re in a finite limit theory, there must be various objects like
. (This fact already means this is a “multi-sorted” theory, which goes beyond what can be done with another approach to universal algebra based on monads). Funthermore, there are maps between these objects, interpreted as source, target, and identity maps of various sorts. These form diagrams, and since we’re in a finite limit theory, there must be various objects like 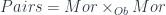 which for sets would have the interpretation “pairs of composable morphisms”. Then there’s a composition map
which for sets would have the interpretation “pairs of composable morphisms”. Then there’s a composition map  … and so on. In short, in describing the axioms for a bicategory in a “nice” way (i.e. in terms of arrows, commuting diagrams, etc.), we’re giving a presentation of a certain category,
… and so on. In short, in describing the axioms for a bicategory in a “nice” way (i.e. in terms of arrows, commuting diagrams, etc.), we’re giving a presentation of a certain category,  , in generators and relations. Then a model of the theory is a functor
, in generators and relations. Then a model of the theory is a functor  – picking out a “bicategory in
– picking out a “bicategory in  , we have:
, we have: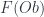 , latex $F(Mor)$, and
, latex $F(Mor)$, and 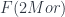
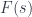 ,
,  and so on
and so on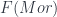 and
and  , where
, where  . One can actually think of this in terms of internalization: these are spans in a category whose objects are spans in
. One can actually think of this in terms of internalization: these are spans in a category whose objects are spans in  in
in  , and so forth. Maybe doing this as weakly as possible would give this tower of increasing weakness.
, and so forth. Maybe doing this as weakly as possible would give this tower of increasing weakness.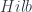 which are relevant to quantum mechanics. Jamie Vicary had, earlier that day, given a talk about n-dimensional TQFT’s and n-categories – specifically, n-Hilbert spaces. I’ll write up their talks in a later, but it was a nice context in which to give the talk.
which are relevant to quantum mechanics. Jamie Vicary had, earlier that day, given a talk about n-dimensional TQFT’s and n-categories – specifically, n-Hilbert spaces. I’ll write up their talks in a later, but it was a nice context in which to give the talk.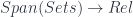
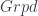

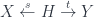 . Say we’re in
. Say we’re in 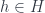 starts and where it ends.
starts and where it ends.
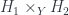 – a fibred product if we’re in
– a fibred product if we’re in  which match at
which match at  .
.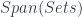 . A relation is an equivalence class of spans, where we only notice whether the set of histories connecting
. A relation is an equivalence class of spans, where we only notice whether the set of histories connecting 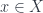 to
to  matrix – so we can think of
matrix – so we can think of  taking an object
taking an object  and a span to the matrix I just mentioned, which faithfully represents
and a span to the matrix I just mentioned, which faithfully represents  can be transported across the span. It lifts to
can be transported across the span. It lifts to 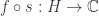 . Getting down the other leg, we add all the contributions of each history ending at a given
. Getting down the other leg, we add all the contributions of each history ending at a given  .
. (or the “weak quotient” of
(or the “weak quotient” of  – a “local” symmetry.
– a “local” symmetry. is a 2-category. In particular, this has two consequences for
is a 2-category. In particular, this has two consequences for 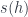 and
and  . In particular, the functors give homomorphisms of the symmetry groups of each object.
. In particular, the functors give homomorphisms of the symmetry groups of each object. . At the morphism level, it ignores everything about the structure of symmetries in the system except how many of them there are. Since a groupoid is a category, the more direct analogy for
. At the morphism level, it ignores everything about the structure of symmetries in the system except how many of them there are. Since a groupoid is a category, the more direct analogy for 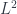 functions only) from
functions only) from  – the category of functors from a groupoid into
– the category of functors from a groupoid into 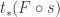 – using
– using  , the adjoint functor to pulling back. This is the 1-morphism level of the 2-functor I call
, the adjoint functor to pulling back. This is the 1-morphism level of the 2-functor I call  in the world of sets. The result is still a “direct sum over histories” – but because we’re dealing with pushing representations through homomorphisms, this adjoint is a bit more complicated than in the 0-category world of
in the world of sets. The result is still a “direct sum over histories” – but because we’re dealing with pushing representations through homomorphisms, this adjoint is a bit more complicated than in the 0-category world of 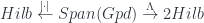
 – could be subjected to the kind of “pull-push” process we’ve just looked at.
– could be subjected to the kind of “pull-push” process we’ve just looked at.