Marco Mackaay recently pointed me at a paper by Mikhail Khovanov, which describes a categorification of the Heisenberg algebra 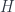 (or anyway its integral form
(or anyway its integral form 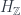 ) in terms of a diagrammatic calculus. This is very much in the spirit of the Khovanov-Lauda program of categorifying Lie algebras, quantum groups, and the like. (There’s also another one by Sabin Cautis and Anthony Licata, following up on it, which I fully intend to read but haven’t done so yet. I may post about it later.)
) in terms of a diagrammatic calculus. This is very much in the spirit of the Khovanov-Lauda program of categorifying Lie algebras, quantum groups, and the like. (There’s also another one by Sabin Cautis and Anthony Licata, following up on it, which I fully intend to read but haven’t done so yet. I may post about it later.)
Now, as alluded to in some of the slides I’ve from recent talks, Jamie Vicary and I have been looking at a slightly different way to answer this question, so before I talk about the Khovanov paper, I’ll say a tiny bit about why I was interested.
Groupoidification
The Weyl algebra (or the Heisenberg algebra – the difference being whether the commutation relations that define it give real or imaginary values) is interesting for physics-related reasons, being the algebra of operators associated to the quantum harmonic oscillator. The particular approach to categorifying it that I’ve worked with goes back to something that I wrote up here, and as far as I know, originally was suggested by Baez and Dolan here. This categorification is based on “stuff types” (Jim Dolan’s term, based on “structure types”, a.k.a. Joyal’s “species”). It’s an example of the groupoidification program, the point of which is to categorify parts of linear algebra using the category 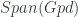 . This has objects which are groupoids, and morphisms which are spans of groupoids: pairs of maps
. This has objects which are groupoids, and morphisms which are spans of groupoids: pairs of maps  . Since I’ve already discussed the backgroup here before (e.g. here and to a lesser extent here), and the papers I just mentioned give plenty more detail (as does “Groupoidification Made Easy“, by Baez, Hoffnung and Walker), I’ll just mention that this is actually more naturally a 2-category (maps between spans are maps
. Since I’ve already discussed the backgroup here before (e.g. here and to a lesser extent here), and the papers I just mentioned give plenty more detail (as does “Groupoidification Made Easy“, by Baez, Hoffnung and Walker), I’ll just mention that this is actually more naturally a 2-category (maps between spans are maps  making everything commute). It’s got a monoidal structure, is additive in a fairly natural way, has duals for morphisms (by reversing the orientation of spans), and more. Jamie Vicary and I are both interested in the quantum harmonic oscillator – he did this paper a while ago describing how to construct one in a general symmetric dagger-monoidal category. We’ve been interested in how the stuff type picture fits into that framework, and also in trying to examine it in more detail using 2-linearization (which I explain here).
making everything commute). It’s got a monoidal structure, is additive in a fairly natural way, has duals for morphisms (by reversing the orientation of spans), and more. Jamie Vicary and I are both interested in the quantum harmonic oscillator – he did this paper a while ago describing how to construct one in a general symmetric dagger-monoidal category. We’ve been interested in how the stuff type picture fits into that framework, and also in trying to examine it in more detail using 2-linearization (which I explain here).
Anyway, stuff types provide a possible categorification of the Weyl/Heisenberg algebra in terms of spans and groupoids. They aren’t the only way to approach the question, though – Khovanov’s paper gives a different (though, unsurprisingly, related) point of view. There are some nice aspects to the groupoidification approach: for one thing, it gives a nice set of pictures for the morphisms in its categorified algebra (they look like groupoids whose objects are Feynman diagrams). Two great features of this Khovanov-Lauda program: the diagrammatic calculus gives a great visual representation of the 2-morphisms; and by dealing with generators and relations directly, it describes, in some sense1, the universal answer to the question “What is a categorification of the algebra with these generators and relations”. Here’s how it works…
Heisenberg Algebra
One way to represent the Weyl/Heisenberg algebra (the two terms refer to different presentations of isomorphic algebras) uses a polynomial algebra ![P_n = \mathbb{C}[x_1,\dots,x_n]](https://s0.wp.com/latex.php?latex=P_n+%3D+%5Cmathbb%7BC%7D%5Bx_1%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) . In fact, there’s a version of this algebra for each natural number
. In fact, there’s a version of this algebra for each natural number  (the stuff-type references above only treat
(the stuff-type references above only treat  , though extending it to “-sorted stuff types” isn’t particularly hard). In particular, it’s the algebra of operators on
, though extending it to “-sorted stuff types” isn’t particularly hard). In particular, it’s the algebra of operators on 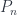 generated by the “raising” operators
generated by the “raising” operators 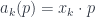 and the “lowering” operators
and the “lowering” operators 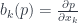 . The point is that this is characterized by some commutation relations. For
. The point is that this is characterized by some commutation relations. For 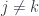 , we have:
, we have:
![[a_j,a_k] = [b_j,b_k] = [a_j,b_k] = 0](https://s0.wp.com/latex.php?latex=%5Ba_j%2Ca_k%5D+%3D+%5Bb_j%2Cb_k%5D+%3D+%5Ba_j%2Cb_k%5D+%3D+0&bg=ffffff&fg=29303b&s=0&c=20201002)
but on the other hand
![[a_k,b_k] = 1](https://s0.wp.com/latex.php?latex=%5Ba_k%2Cb_k%5D+%3D+1&bg=ffffff&fg=29303b&s=0&c=20201002)
So the algebra could be seen as just a free thing generated by symbols  with these relations. These can be understood to be the “raising and lowering” operators for an -dimensional harmonic oscillator. This isn’t the only presentation of this algebra. There’s another one where
with these relations. These can be understood to be the “raising and lowering” operators for an -dimensional harmonic oscillator. This isn’t the only presentation of this algebra. There’s another one where ![[p_k,q_k] = i](https://s0.wp.com/latex.php?latex=%5Bp_k%2Cq_k%5D+%3D+i&bg=ffffff&fg=29303b&s=0&c=20201002) (as in
(as in  ) has a slightly different interpretation, where the
) has a slightly different interpretation, where the  and
and  operators are the position and momentum operators for the same system. Finally, a third one – which is the one that Khovanov actually categorifies – is skewed a bit, in that it replaces the
operators are the position and momentum operators for the same system. Finally, a third one – which is the one that Khovanov actually categorifies – is skewed a bit, in that it replaces the 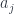 with a different set of
with a different set of 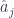 so that the commutation relation actually looks like
so that the commutation relation actually looks like
![[\hat{a}_j,b_k] = b_{k-1}\hat{a}_{j-1}](https://s0.wp.com/latex.php?latex=%5B%5Chat%7Ba%7D_j%2Cb_k%5D+%3D+b_%7Bk-1%7D%5Chat%7Ba%7D_%7Bj-1%7D&bg=ffffff&fg=29303b&s=0&c=20201002)
It’s not instantly obvious that this produces the same result – but the can be rewritten in terms of the , and they generate the same algebra. (Note that for the one-dimensional version, these are in any case the same, taking  .)
.)
Diagrammatic Calculus
To categorify this, in Khovanov’s sense (though see note below1), means to find a category 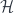 whose isomorphism classes of objects correspond to (integer-) linear combinations of products of the generators of . Now, in the setup, we can say that the groupoid
whose isomorphism classes of objects correspond to (integer-) linear combinations of products of the generators of . Now, in the setup, we can say that the groupoid  , or equvialently
, or equvialently  , represents Fock space. Groupoidification turns this into the free vector space on the set of isomorphism classes of objects. This has some extra structure which we don’t need right now, so it makes the most sense to describe it as
, represents Fock space. Groupoidification turns this into the free vector space on the set of isomorphism classes of objects. This has some extra structure which we don’t need right now, so it makes the most sense to describe it as ![\mathbb{C}[[t]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5B%5Bt%5D%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , the space of power series (where
, the space of power series (where 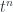 corresponds to the object
corresponds to the object ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=29303b&s=0&c=20201002) ). The algebra itself is an algebra of endomorphisms of this space. It’s this algebra Khovanov is looking at, so the monoidal category in question could really be considered a bicategory with one object, where the monoidal product comes from composition, and the object stands in formally for the space it acts on. But this space doesn’t enter into the description, so we’ll just think of as a monoidal category. We’ll build it in two steps: the first is to define a category
). The algebra itself is an algebra of endomorphisms of this space. It’s this algebra Khovanov is looking at, so the monoidal category in question could really be considered a bicategory with one object, where the monoidal product comes from composition, and the object stands in formally for the space it acts on. But this space doesn’t enter into the description, so we’ll just think of as a monoidal category. We’ll build it in two steps: the first is to define a category  .
.
The objects of are defined by two generators, called 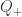 and
and  , and the fact that it’s monoidal (these objects will be the categorifications of
, and the fact that it’s monoidal (these objects will be the categorifications of  and
and  ). Thus, there are objects
). Thus, there are objects  and so forth. In general, if
and so forth. In general, if  is some word on the alphabet
is some word on the alphabet  , there’s an object
, there’s an object 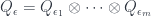 .
.
As in other categorifications in the Khovanov-Lauda vein, we define the morphisms of to be linear combinations of certain planar diagrams, modulo some local relations. (This type of formalism comes out of knot theory – see e.g. this intro by Louis Kauffman). In particular, we draw the objects as sequences of dots labelled  or
or  , and connect two such sequences by a bunch of oriented strands (embeddings of the interval, or circle, in the plane). Each dot is the endpoint of a strand oriented up, and each dot is the endpoint of a strand oriented down. The local relations mean that we can take these diagrams up to isotopy (moving the strands around), as well as various other relations that define changes you can make to a diagram and still represent the same morphism. These relations include things like:
, and connect two such sequences by a bunch of oriented strands (embeddings of the interval, or circle, in the plane). Each dot is the endpoint of a strand oriented up, and each dot is the endpoint of a strand oriented down. The local relations mean that we can take these diagrams up to isotopy (moving the strands around), as well as various other relations that define changes you can make to a diagram and still represent the same morphism. These relations include things like:

which seems visually obvious (imagine tugging hard on the ends on the left hand side to straighten the strands), and the less-obvious:

and a bunch of others. The main ingredients are cups, caps, and crossings, with various orientations. Other diagrams can be made by pasting these together. The point, then, is that any morphism is some  -linear combination of these. (I prefer to assume
-linear combination of these. (I prefer to assume  most of the time, since I’m interested in quantum mechanics, but this isn’t strictly necessary.)
most of the time, since I’m interested in quantum mechanics, but this isn’t strictly necessary.)
The second diagram, by the way, are an important part of categorifying the commutation relations. This would say that  (the commutation relation has become a decomposition of a certain tensor product). The point is that the left hand sides show the composition of two crossings
(the commutation relation has become a decomposition of a certain tensor product). The point is that the left hand sides show the composition of two crossings  and
and 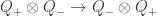 in two different orders. One can use this, plus isotopy, to show the decomposition.
in two different orders. One can use this, plus isotopy, to show the decomposition.
That diagrams are invariant under isotopy means, among other things, that the yanking rule holds:

(and similar rules for up-oriented strands, and zig zags on the other side). These conditions amount to saying that the functors 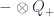 and
and  are two-sided adjoints. The two cups and caps (with each possible orientation) give the units and counits for the two adjunctions. So, for instance, in the zig-zag diagram above, there’s a cup which gives a unit map
are two-sided adjoints. The two cups and caps (with each possible orientation) give the units and counits for the two adjunctions. So, for instance, in the zig-zag diagram above, there’s a cup which gives a unit map  (reading upward), all tensored on the right by . This is followed by a cap giving a counit map
(reading upward), all tensored on the right by . This is followed by a cap giving a counit map  (all tensored on the left by ). So the yanking rule essentially just gives one of the identities required for an adjunction. There are four of them, so in fact there are two adjunctions: one where is the left adjoint, and one where it’s the right adjoint.
(all tensored on the left by ). So the yanking rule essentially just gives one of the identities required for an adjunction. There are four of them, so in fact there are two adjunctions: one where is the left adjoint, and one where it’s the right adjoint.
Karoubi Envelope
Now, so far this has explained where a category comes from – the one with the objects 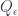 described above. This isn’t quite enough to get a categorification of : it would be enough to get the version with just one and one element, and their powers, but not all the and
described above. This isn’t quite enough to get a categorification of : it would be enough to get the version with just one and one element, and their powers, but not all the and  . To get all the elements of the (integral form of) the Heisenberg algebras, and in particular to get generators that satisfy the right commutation relations, we need to introduce some new objects. There’s a convenient way to do this, though, which is to take the Karoubi envelope of .
. To get all the elements of the (integral form of) the Heisenberg algebras, and in particular to get generators that satisfy the right commutation relations, we need to introduce some new objects. There’s a convenient way to do this, though, which is to take the Karoubi envelope of .
The Karoubi envelope of any category  is a universal way to find a category
is a universal way to find a category 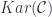 that contains and for which all idempotents split (i.e. have corresponding subobjects). Think of vector spaces, for example: a map
that contains and for which all idempotents split (i.e. have corresponding subobjects). Think of vector spaces, for example: a map  such that
such that 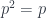 is a projection. That projection corresponds to a subspace
is a projection. That projection corresponds to a subspace  , and
, and 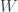 is actually another object in
is actually another object in  , so that splits (factors) as
, so that splits (factors) as  . This might not happen in any general , but it will in . This has, for objects, all the pairs
. This might not happen in any general , but it will in . This has, for objects, all the pairs 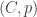 where
where 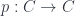 is idempotent (so is contained in as the cases where
is idempotent (so is contained in as the cases where  ). The morphisms
). The morphisms  are just maps
are just maps 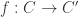 with the compatibility condition that
with the compatibility condition that  (essentially, maps between the new subobjects).
(essentially, maps between the new subobjects).
So which new subobjects are the relevant ones? They’ll be subobjects of tensor powers of our  . First, consider
. First, consider  . Obviously, there’s an action of the symmetric group
. Obviously, there’s an action of the symmetric group  on this, so in fact (since we want a -linear category), its endomorphisms contain a copy of
on this, so in fact (since we want a -linear category), its endomorphisms contain a copy of ![\mathbf{k}[\mathcal{S}_n]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5B%5Cmathcal%7BS%7D_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , the corresponding group algebra. This has a number of different projections, but the relevant ones here are the symmetrizer,:
, the corresponding group algebra. This has a number of different projections, but the relevant ones here are the symmetrizer,:

which wants to be a “projection onto the symmetric subspace” and the antisymmetrizer:

which wants to be a “projection onto the antisymmetric subspace” (if it were in a category with the right sub-objects). The diagrammatic way to depict this is with horizontal bars: so the new object 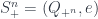 (the symmetrized subobject of
(the symmetrized subobject of  ) is a hollow rectangle, labelled by . The projection from
) is a hollow rectangle, labelled by . The projection from  is drawn with arrows heading into that box:
is drawn with arrows heading into that box:

The antisymmetrized subobject 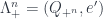 is drawn with a black box instead. There are also
is drawn with a black box instead. There are also  and
and  defined in the same way (and drawn with downward-pointing arrows).
defined in the same way (and drawn with downward-pointing arrows).
The basic fact – which can be shown by various diagram manipulations, is that  . The key thing is that there are maps from the left hand side into each of the terms on the right, and the sum can be shown to be an isomorphism using all the previous relations. The map into the second term involves a cap that uses up one of the strands from each term on the left.
. The key thing is that there are maps from the left hand side into each of the terms on the right, and the sum can be shown to be an isomorphism using all the previous relations. The map into the second term involves a cap that uses up one of the strands from each term on the left.
There are other idempotents as well – for every partition 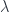 of , there’s a notion of -symmetric things – but ultimately these boil down to symmetrizing the various parts of the partition. The main point is that we now have objects in
of , there’s a notion of -symmetric things – but ultimately these boil down to symmetrizing the various parts of the partition. The main point is that we now have objects in 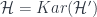 corresponding to all the elements of . The right choice is that the (the new generators in this presentation that came from the lowering operators) correspond to the
corresponding to all the elements of . The right choice is that the (the new generators in this presentation that came from the lowering operators) correspond to the  (symmetrized products of “lowering” strands), and the correspond to the
(symmetrized products of “lowering” strands), and the correspond to the 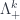 (antisymmetrized products of “raising” strands). We also have isomorphisms (i.e. diagrams that are invertible, using the local moves we’re allowed) for all the relations. This is a categorification of .
(antisymmetrized products of “raising” strands). We also have isomorphisms (i.e. diagrams that are invertible, using the local moves we’re allowed) for all the relations. This is a categorification of .
Some Generalities
This diagrammatic calculus is universal enough to be applied to all sorts of settings where there are functors which are two-sided adjoints of one another (by labelling strands with functors, and the regions of the plane with categories they go between). I like this a lot, since biadjointness of certain functors is essential to the 2-linearization functor 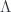 (see my link above). In particular, uses biadjointness of restriction and induction functors between representation categories of groupoids associated to a groupoid homomorphism (and uses these unit and counit maps to deal with 2-morphisms). That example comes from the fact that a (finite-dimensional) representation of a finite group(oid) is a functor into , and a group(oid) homomorphism is also just a functor
(see my link above). In particular, uses biadjointness of restriction and induction functors between representation categories of groupoids associated to a groupoid homomorphism (and uses these unit and counit maps to deal with 2-morphisms). That example comes from the fact that a (finite-dimensional) representation of a finite group(oid) is a functor into , and a group(oid) homomorphism is also just a functor  . Given such an
. Given such an  , there’s an easy “restriction”
, there’s an easy “restriction” 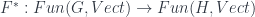 , that just works by composing with . Then in principle there might be two different adjoints
, that just works by composing with . Then in principle there might be two different adjoints  , given by the left and right Kan extension along . But these are defined by colimits and limits, which are the same for (finite-dimensional) vector spaces. So in fact the adjoint is two-sided.
, given by the left and right Kan extension along . But these are defined by colimits and limits, which are the same for (finite-dimensional) vector spaces. So in fact the adjoint is two-sided.
Khovanov’s paper describes and uses exactly this example of biadjointness in a very nice way, albeit in the classical case where we’re just talking about inclusions of finite groups. That is, given a subgroup 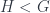 , we get a functors
, we get a functors  , which just considers the obvious action of act on any representation space of
, which just considers the obvious action of act on any representation space of 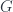 . It has a biadjoint
. It has a biadjoint  , which takes a representation
, which takes a representation 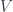 of to
of to ![\mathbf{k}[G] \otimes_{\mathbf{k}[H]} V](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BG%5D+%5Cotimes_%7B%5Cmathbf%7Bk%7D%5BH%5D%7D+V&bg=ffffff&fg=29303b&s=0&c=20201002) , which is a special case of the formula for a Kan extension. (This formula suggests why it’s also natural to see these as functors between module categories
, which is a special case of the formula for a Kan extension. (This formula suggests why it’s also natural to see these as functors between module categories ![\mathbf{k}[G]-mod](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BG%5D-mod&bg=ffffff&fg=29303b&s=0&c=20201002) and
and ![\mathbf{k}[H]-mod](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bk%7D%5BH%5D-mod&bg=ffffff&fg=29303b&s=0&c=20201002) ). To talk about the Heisenberg algebra in particular, Khovanov considers these functors for all the symmetric group inclusions
). To talk about the Heisenberg algebra in particular, Khovanov considers these functors for all the symmetric group inclusions 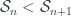 .
.
Except for having to break apart the symmetric groupoid as 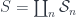 , this is all you need to categorify the Heisenberg algebra. In the categorification, we pick out the interesting operators as those generated by the
, this is all you need to categorify the Heisenberg algebra. In the categorification, we pick out the interesting operators as those generated by the  map from to itself, but “really” (i.e. up to equivalence) this is just all the inclusions taken at once. However, Khovanov’s approach is nice, because it separates out a lot of what’s going on abstractly and uses a general diagrammatic way to depict all these 2-morphisms (this is explained in the first few pages of Aaron Lauda’s paper on ambidextrous adjoints, too). The case of restriction and induction is just one example where this calculus applies.
map from to itself, but “really” (i.e. up to equivalence) this is just all the inclusions taken at once. However, Khovanov’s approach is nice, because it separates out a lot of what’s going on abstractly and uses a general diagrammatic way to depict all these 2-morphisms (this is explained in the first few pages of Aaron Lauda’s paper on ambidextrous adjoints, too). The case of restriction and induction is just one example where this calculus applies.
There’s a fair bit more in the paper, but this is probably sufficient to say here.
1 There are two distinct but related senses of “categorification” of an algebra  here, by the way. To simplify the point, say we’re talking about a ring
here, by the way. To simplify the point, say we’re talking about a ring 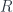 . The first sense of a categorification of is a (monoidal, additive) category
. The first sense of a categorification of is a (monoidal, additive) category 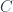 with a “valuation” in that takes
with a “valuation” in that takes 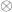 to
to  and
and  to . This is described, with plenty of examples, in this paper by Rafael Diaz and Eddy Pariguan. The other, typical of the Khovanov program, says it is a (monoidal, additive) category whose Grothendieck ring is
to . This is described, with plenty of examples, in this paper by Rafael Diaz and Eddy Pariguan. The other, typical of the Khovanov program, says it is a (monoidal, additive) category whose Grothendieck ring is  . Of course, the second definition implies the first, but not conversely. The objects of the Grothendieck ring are isomorphism classes in . A valuation may identify objects which aren’t isomorphic (or, as in groupoidification, morphisms which aren’t 2-isomorphic).
. Of course, the second definition implies the first, but not conversely. The objects of the Grothendieck ring are isomorphism classes in . A valuation may identify objects which aren’t isomorphic (or, as in groupoidification, morphisms which aren’t 2-isomorphic).
So a categorification of the first sort could be factored into two steps: first take the Grothendieck ring, then take a quotient to further identify things with the same valuation. If we’re lucky, there’s a commutative square here: we could first take the category , find some surjection  , and then find that
, and then find that 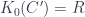 . This seems to be the relation between Khovanov’s categorification of and the one in . This is the sense in which it seems to be the “universal” answer to the problem.
. This seems to be the relation between Khovanov’s categorification of and the one in . This is the sense in which it seems to be the “universal” answer to the problem.




 candidates, and so on until a single winner emerges. In IRV, this is done by transferring the votes for the discarded candidate to their second-choice candidate, recounding, discarding again, and so on. (The proposal in the UK would be to use this system in each constituency to elect individual MP’s.)
candidates, and so on until a single winner emerges. In IRV, this is done by transferring the votes for the discarded candidate to their second-choice candidate, recounding, discarding again, and so on. (The proposal in the UK would be to use this system in each constituency to elect individual MP’s.) , and vote-counting amounts to taking an average of all the vectors. Then assuming one knew in advance what the average were going to be, the incentive in voting is to pick a vector pointing from the actual average to the outcome you want.
, and vote-counting amounts to taking an average of all the vectors. Then assuming one knew in advance what the average were going to be, the incentive in voting is to pick a vector pointing from the actual average to the outcome you want.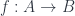 , you get a pair of maps
, you get a pair of maps  and
and  between the vector spaces on
between the vector spaces on  . (Moving from the set to the vector space stands in for moving to quantum mechanics, where a state is a linear combination of the “pure” ones – elements of the set.) The first map is just “precompose with
. (Moving from the set to the vector space stands in for moving to quantum mechanics, where a state is a linear combination of the “pure” ones – elements of the set.) The first map is just “precompose with  “, and the other involves summing over the preimage (it takes the basis vector
“, and the other involves summing over the preimage (it takes the basis vector 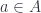 to the basis vector
to the basis vector  . These two maps are (linear) adjoints, if you use the canonical inner products where
. These two maps are (linear) adjoints, if you use the canonical inner products where  gives rise to a linear map
gives rise to a linear map  (and an adjoint linear map going the other way).
(and an adjoint linear map going the other way). with the category
with the category  , and the sum with the direct sum of (finite dimensional) Hilbert spaces gives an analogous story for (finite dimensional) 2-Hilbert spaces, and 2-linear maps.
, and the sum with the direct sum of (finite dimensional) Hilbert spaces gives an analogous story for (finite dimensional) 2-Hilbert spaces, and 2-linear maps. with $\mathbf{Hilb}$). Other issues are basically measure-theoretic, since in various parts of the construction one uses direct sums. For Lie groups, these need to be direct integrals. There are also places where counting measure is used in the case of a discrete group
with $\mathbf{Hilb}$). Other issues are basically measure-theoretic, since in various parts of the construction one uses direct sums. For Lie groups, these need to be direct integrals. There are also places where counting measure is used in the case of a discrete group  isn’t a categorical product – just a monoidal one, in a category Wendt calls
isn’t a categorical product – just a monoidal one, in a category Wendt calls  .
. to
to  consists of:
consists of:
 , the preimage
, the preimage  becomes a measure space (with the obvious subspace sigma-algebra
becomes a measure space (with the obvious subspace sigma-algebra  ), with measure
), with measure 
 can be recovered by integrating against $\nu$: that is, for any measurable
can be recovered by integrating against $\nu$: that is, for any measurable  , (that is,
, (that is, 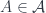 ), we have
), we have .
. relative to
relative to 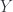 . In particular, there is a forgetful functor
. In particular, there is a forgetful functor  , where
, where 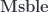 is the category of measurable spaces, taking the disintegration
is the category of measurable spaces, taking the disintegration  to
to 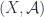 consists of:
consists of: of (separable) Hilbert spaces, for
of (separable) Hilbert spaces, for 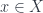
 (of “measurable sections”
(of “measurable sections” 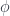 ) (i.e. pointwise inverses to projection maps
) (i.e. pointwise inverses to projection maps  ) with three properties:
) with three properties: is measurable for all
is measurable for all 
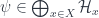 makes the function
makes the function 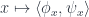 then
then 
 such that for all
such that for all  , the
, the  are dense in
are dense in 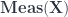 of MFHS’s on
of MFHS’s on  , the prototypical 2-vector space – except that here we have
, the prototypical 2-vector space – except that here we have 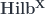 . Yetter describes how to get 2-linear maps (linear functors) between such 2-vector spaces
. Yetter describes how to get 2-linear maps (linear functors) between such 2-vector spaces 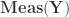 .
. -enriched abelian category – whose objects are MFHS’s, and whose morphisms are the obvious (that is, fields of bounded operators, whose norms give a measurable function). One thing Wendt does is to show that a MFHS
-enriched abelian category – whose objects are MFHS’s, and whose morphisms are the obvious (that is, fields of bounded operators, whose norms give a measurable function). One thing Wendt does is to show that a MFHS  is the usual Borel
is the usual Borel 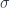 -algebra). If this terminology doesn’t spell it out for you, the point is that for any measurable set
-algebra). If this terminology doesn’t spell it out for you, the point is that for any measurable set 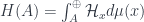
 is the space of sections of
is the space of sections of  with finite norm, where the inner product of two sections
with finite norm, where the inner product of two sections 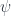 is the integral of
is the integral of  over
over  gives rise to two operations between the categories of sheaves (though it’s convenient here to describe them in terms of MFHS: the sheaves are recovered by integrating as above):
gives rise to two operations between the categories of sheaves (though it’s convenient here to describe them in terms of MFHS: the sheaves are recovered by integrating as above):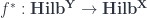
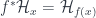 , and
, and
 . That is, one direct-integrates over the preimage.
. That is, one direct-integrates over the preimage. is the analog of what is usually called
is the analog of what is usually called 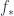 .
. , the more usual underlying category. What’s more, typically one talks about sheaves of sets, or abelian groups, or rings (which give the case of operations on schemes – i.e. topological spaces equipped with well-behaved sheaves of rings) – all of which are nicer categories than the category of Hilbert spaces. In particular, while in the usual picture
, the more usual underlying category. What’s more, typically one talks about sheaves of sets, or abelian groups, or rings (which give the case of operations on schemes – i.e. topological spaces equipped with well-behaved sheaves of rings) – all of which are nicer categories than the category of Hilbert spaces. In particular, while in the usual picture  , this condition fails here because of the requirement that morphisms in
, this condition fails here because of the requirement that morphisms in  are bounded linear maps – instead, there’s a unique extension property.
are bounded linear maps – instead, there’s a unique extension property. is always defined by pulling back along a function
is always defined by pulling back along a function  , where
, where  are corresponding “momentum” variables, which are the other coordinates in a phase space which in simple cases is just the cotangent bundle
are corresponding “momentum” variables, which are the other coordinates in a phase space which in simple cases is just the cotangent bundle  . Here,
. Here, 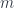 refers to mass, or some equivalent. The familiar case of a moving point particle has “energy = kinetic + potential”, or
refers to mass, or some equivalent. The familiar case of a moving point particle has “energy = kinetic + potential”, or  for some potential function
for some potential function  living on the tangent bundle
living on the tangent bundle 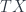 , over the path. The physically realized paths (classically) are critical points of the action, with respect to variations of the path.
, over the path. The physically realized paths (classically) are critical points of the action, with respect to variations of the path.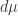 around to integrate against – then a function like
around to integrate against – then a function like 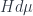 . And this is where the notion of a Gibbs state comes from, though it’s slightly trickier. The idea is that the Gibbs state (in some circumstances called the
. And this is where the notion of a Gibbs state comes from, though it’s slightly trickier. The idea is that the Gibbs state (in some circumstances called the 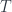 . So, for instance, for a gas in a box, this describes how, at a given temperature, the kinetic energies of the particles are (probably) distributed. Up to a bunch of constants of proportionality, one expects that the weight given to a state (or region in state space) is just
. So, for instance, for a gas in a box, this describes how, at a given temperature, the kinetic energies of the particles are (probably) distributed. Up to a bunch of constants of proportionality, one expects that the weight given to a state (or region in state space) is just  , where
, where  , which is again, up to some constant factors, just the exponential of the Hamiltonian operator. (For pure states,
, which is again, up to some constant factors, just the exponential of the Hamiltonian operator. (For pure states,  , and in general a matrix becomes a state by
, and in general a matrix becomes a state by  which for pure states is just the usual expectation value value for A,
which for pure states is just the usual expectation value value for A,  ).
). (i.e. such that
(i.e. such that 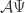 is dense in
is dense in 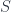 by the fact that, for any
by the fact that, for any 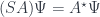
 , where
, where 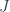 is antiunitary (this is conjugation, after all) and
is antiunitary (this is conjugation, after all) and 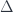 is self-adjoint. We need the self-adjoint part, because the Tomita flow is a one-parameter family of automorphisms given by:
is self-adjoint. We need the self-adjoint part, because the Tomita flow is a one-parameter family of automorphisms given by:
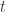 parameter would be an example). So while there are different flows, they’re all “essentially” the same. There’s a unique notion of time flow if we reduce the algebra
parameter would be an example). So while there are different flows, they’re all “essentially” the same. There’s a unique notion of time flow if we reduce the algebra  has a very multivariable-calculus feel to it: you think of curves passing through a point, parametrized by arclength. The have a moving orthogonal frame attached: unit tangent vector, its derivative, and their cross-product. The derivative of the unit tangent is always orthogonal (it’s not changing length), so you can imagine it to be the radius of a circle, with length
has a very multivariable-calculus feel to it: you think of curves passing through a point, parametrized by arclength. The have a moving orthogonal frame attached: unit tangent vector, its derivative, and their cross-product. The derivative of the unit tangent is always orthogonal (it’s not changing length), so you can imagine it to be the radius of a circle, with length  , the radius of curvature. Then you have
, the radius of curvature. Then you have 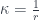 curvature along that path. At any given point on a surface, you get two degrees of freedom – locally, the curve looks like a hyperboloid or an ellipse, or whatever, so there’s actually a curvature form. The determinant gives the Gaussian curvature
curvature along that path. At any given point on a surface, you get two degrees of freedom – locally, the curve looks like a hyperboloid or an ellipse, or whatever, so there’s actually a curvature form. The determinant gives the Gaussian curvature 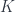 . So it’s a “second derivative” of the surface itself (if you think of it as ). The Gaussian curvature, unlike the curvature in particular directions, is intrinsic – preserved by isometry of the surface, so it’s not really dependent on the embedding. But this fact takes a little thinking to get to. Then there’s the trace – the scalar curvature.
. So it’s a “second derivative” of the surface itself (if you think of it as ). The Gaussian curvature, unlike the curvature in particular directions, is intrinsic – preserved by isometry of the surface, so it’s not really dependent on the embedding. But this fact takes a little thinking to get to. Then there’s the trace – the scalar curvature. in the population of voters
in the population of voters  , a total order on
, a total order on  . This is a function
. This is a function 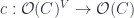 (where
(where  is the set of orders on
is the set of orders on  should satisfy some conditions, of course, and many possible conditions have been defined. Arrow’s theorem is usually stated with five conditions, but an equivalent form uses these:
should satisfy some conditions, of course, and many possible conditions have been defined. Arrow’s theorem is usually stated with five conditions, but an equivalent form uses these: , the restriction
, the restriction 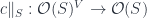 agrees with
agrees with 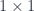 matrices over
matrices over  -bimodule,
-bimodule,  . This is similar to the business of making categories of spans.
. This is similar to the business of making categories of spans. with an embedded graph
with an embedded graph 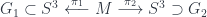
 is branched over a graph containing
is branched over a graph containing  (perhaps strictly). In fact, as they point out, there’s a theorem (due to Alexander) proving that ANY 3-manifold
(perhaps strictly). In fact, as they point out, there’s a theorem (due to Alexander) proving that ANY 3-manifold  can be realized as a branched cover over the 3-sphere, branched at some graph (though perhaps not including a given
can be realized as a branched cover over the 3-sphere, branched at some graph (though perhaps not including a given 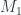 and
and 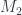 (together with their
(together with their  maps) is a cobordism
maps) is a cobordism  , in a way that’s compatible with the structure of the $lateux M_i$ as branched covers of the 3-sphere. The
, in a way that’s compatible with the structure of the $lateux M_i$ as branched covers of the 3-sphere. The 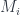 are being included as components of the boundary
are being included as components of the boundary 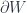 – I’m writing it this way to emphasize that a cobordism is a kind of cospan. Here, it’s a cospan between spans.
– I’m writing it this way to emphasize that a cobordism is a kind of cospan. Here, it’s a cospan between spans. -categories into
-categories into 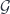 – like taking the groupoid algebra
– like taking the groupoid algebra ![\mathbb{C}[\mathcal{G}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5B%5Cmathcal%7BG%7D%5D&bg=ffffff&fg=29303b&s=0&c=20201002) of
of 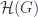 at each object
at each object  which can be post-composed with one
which can be post-composed with one 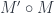 starting at
starting at 