There is no abiding thing in what we know. We change from weaker to stronger lights, and each more powerful light pierces our hitherto opaque foundations and reveals fresh and different opacities below. We can never foretell which of our seemingly assured fundamentals the next change will not affect.
H.G. Wells, A Modern Utopia
So there’s a recent paper by some physicists, two of whom work just across the campus from me at IST, which purports to explain the Pioneer Anomaly, ultimately using a computer graphics technique, Phong shading. The point being that they use this to model more accurately than has been done before how much infrared radiation is radiating and reflecting off various parts of the Pioneer spacecraft. They claim that with the new, more accurate model, the net force from this radiation is just enough to explain the anomalous acceleration.
Well, plainly, any one paper needs to be rechecked before you can treat it as definitive, but this sort of result looks good for conventional General Relativity, when some people had suggested the anomaly was evidence some other theory was needed. Other anomalies in the predictions of GR – the rotational profiles of galaxies, or redshift data, have also suggested alternative theories. In order to preserve GR exactly on large scales, you have to introduce things like Dark Matter and Dark Energy, and suppose that something like 97% of the mass-energy of the universe is otherwise invisible. Such Dark entities might exist, of course, but I worry it’s kind of circular to postulate them on the grounds that you need them to make GR explain observations, while also claiming this makes sense because GR is so well tested.
In any case, this refined calculation about Pioneer is a reminder that usually the more conservative extension of your model is better. It’s not so obvious to me whether a modified theory of gravity, or an unknown and invisible majority of the universe is more conservative.
And that’s the best segue I can think of into this next post, which is very different from recent ones.
Fundamentals
I was thinking recently about “fundamental” theories. At the HGTQGR workshop we had several talks about the most popular physical ideas into which higher gauge theory and TQFT have been infiltrating themselves recently, namely string theory and (loop) quantum gravity. These aren’t the only schools of thought about what a “quantum gravity” theory should look like – but they are two that have received a lot of attention and work. Each has been described (occasionally) as a “fundamental” theory of physics, in the sense of one which explains everything else. There has been a debate about this, since they are based on different principles. The arguments against string theory are various, but a crucial one is that no existing form of string theory is “background independent” in the same way that General Relativity is. This might be because string theory came out of a community grounded in particle physics – it makes sense to perturb around some fixed background spacetime in that context, because no experiment with elementary particles is going to have a measurable effect on the universe at infinity. “M-theory” is supposed to correct this defect, but so far nobody can say just what it is. String theorists criticize LQG on various grounds, but one of the more conceptually simple ones would be that it can’t be a unified theory of physics, since it doesn’t incorporate forces other than gravity.
There is, of course, some philosophical debate about whether either of these properties – background independence, or unification – is really crucial to a fundamental theory. I don’t propose to answer that here (though for the record my hunch at he moment is that both of them are important and will hold up over time). In fact, it’s “fundamental theory” itself that I’m thinking about here.
As I suggested in one of my first posts explaining the title of this blog, I expect that we’ll need lots of theories to get a grip on the world: a whole “atlas”, where each “map” is a theory, each dealing with a part of the whole picture, and overlapping somewhat with others. But theories are formal entities that involve symbols and our brain’s ability to manipulate symbols. Maybe such a construct could account for all the observable phenomena of the world – but a-priori it seems odd to assume that. The fact that they can provide various limits and approximations has made them useful, from an evolutionary point of view, and the tendency to confuse symbols and reality in some ways is a testament to that (it hasn’t hurt so much as to be selected out).
One little heuristic argument – not at all conclusive – against this idea involves Kolmogorov complexity: wanting to explain all the observed data about the universe is in some sense to “compress” the data. If we can account for the observations – say, with a short description of some physical laws and a bunch of initial conditions, which is what a “fundamental theory” suggests – then we’ve found an upper bound on its Kolmogorov complexity. If the universe actually contains such a description, then that must also be a lower bound on its complexity. Thus, any complete description of the universe would have to be as big as the whole universe.
Well, as I said, this argument fails to be very convincing. Partly because it assumes a certain form of the fundamental theory (in particular, a deterministic one), but mainly because it doesn’t rule out that there is indeed a very simple set of physical laws, but there are limits to the precision with which we could use them to simulate the whole world because we can’t encode the state of the universe perfectly. We already knew that. At most, that lack of precision puts some practical limits on our ability to confirm that a given set of physical laws we’ve written down is empirically correct. It doesn’t preclude there being one, or even our finding it (without necessarily being perfectly certain). The way Einstein put it (in this address, by the way) was “As far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality.” But a lack of certainty doesn’t mean they aren’t there.
However, this got me thinking about fundamental theories from the point of view of epistemology, and how we handle knowledge.
Reduction
First, there’s a practical matter. The idea of a fundamental theory is the logical limit of one version of reductionism. This is the idea that the behaviour of things should be explained in terms of smaller, simpler things. I have no problem with this notion, unless you then conclude that once you’ve found a “more fundamental” theory, the old one should be discarded.
For example: we have a “theory of chemistry”, which says that the constituents of matter are those found on the periodic table of elements. This theory comes in various degrees of sophistication: for instance, you can start to learn the periodic table without knowing that there are often different isotopes of a given element, and only knowing the 91 naturally occurring elements (everything up to Uranium, except Technicium). This gives something like Mendeleev’s early version of the table. You could come across these later refinements by finding a gap in the theory (Technicium, say), or a disagreement with experiment (discovering isotopes by measuring atomic weights). But even a fairly naive version of the periodic table, along with some concepts about atomic bonds, gives a good explanation of a huge range of chemical reactions under normal conditions. It can’t explain, for example, how the Sun shines – but it explains a lot within its proper scope.
Where this theory fits in a fuller picture of the world has at least two directions: more fundamental, and less fundamental, theories. What I mean by less “fundamental” is that some things are supposed to be explained by this theory of chemistry: the great abundance of proteins and other organic chemicals, say. The behaviour of the huge variety of carbon compounds predicted by basic chemistry is supposed to explain all these substances and account for how they behave. The millions of organic compounds that show up in nature, and their complicated behaviour, is supposed to be explained in terms of just a few elements that they’re made of – mostly carbon, hydrogen, oxygen, nitrogen, sulfur, phosphorus, plus the odd trace element.
By “more fundamental”, I mean that the periodic table itself can start to seem fairly complicated, especially once you start to get more sophisticated, including transuranic elements, isotopes, radioactive decay rates, and the like. So it was explained in terms of a theory of the atom. Again, there are refinements, but the Bohr model of the atom ought to do the job: a nucleus made of protons and neutrons, and surrounded by shells of electrons. We can add that these are governed by the Dirac equation, and then the possible states for electrons bound to a nucleus ought to explain the rows and columns of the periodic table. Better yet, they’re supposed to explain exactly the spectral lines of each element – the frequencies of light atoms absorb and emit – by the differences of energy levels between the shells.
Well, this is great, but in practice it has limits. Hardly anyone disputes that the Bohr model is approximately right, and should explain the periodic table etc. The problem is that it’s largely an intractable problem to actually solve the Schroedinger equation for the atom and use the results to predict the emission spectrum, chemical properties, melting point, etc. of, say, Vanadium… On the other hand, it’s equally hard to use a theory of chemistry to adequately predict how proteins will fold. Protein conformation prediction is a hard problem, and while it’s chugging along and making progress, the point is a theory of chemistry alone isn’t enough: any successful method must rely on a whole extra body of knowledge. This suggests our best bet at understanding all these phenomena is to have a whole toolbox of different theories, each one of which has its own body of relevant mathematics, its own domain-specific ontology, and some sense of how its concepts relate to those in other theories in the tookbox. (This suggests a view of how mathematics relates to the sciences which seems to me to reflect actual practice: it pervades all of them, in a different way than the way a “more fundamental” theory underlies a less fundamental one. Which tends to spoil the otherwise funny XKCD comic on the subject…)
If one “explains” one theory in terms of another (or several others), then we may be able to put them into at least a partial order. The mental image I have in mind is the “theoretical atlas” – a bunch of “charts” (the theories) which cover different parts of a globe (our experience, or the data we want to account for), and which overlap in places. Some are subsets of others (are completely explained by them, in principle). Then we’d like to find a minimal (or is it maximal) element of this order: something which accounts for all the others, at least in principle. In that mental image, it would be a map of the whole globe (or a dense subset of the surface, anyway). Because, of course, the Bohr model, though in principle sufficient to account for chemistry, needs an explanation of its own: why are atoms made this way, instead of some other way? This ends up ramifying out into something like the Standard Model of particle physics. Once we have that, we would still like to know why elementary particles work this way, instead of some other way…
An Explanatory Trilemma
There’s a problem here, which I think is unavoidable, and which rather ruins that nice mental image. It has to do with a sort of explanatory version of Agrippa’s Trilemma, which is an observation in epistemology that goes back to Agrippa the Skeptic. It’s also sometimes called “Munchausen’s Trilemma”, and it was originally made about justifying beliefs. I think a slightly different form of it can be applied to explanations, where instead of “how do I know X is true?”, the question you repeatedly ask is “why does it happen like X?”
So, the Agrippa Trilemma as classically expressed might lead to a sequence of questions about observation. Q: How do we know chemical substances are made of elements? A: Because of some huge body of evidence. Q: How do we know this evidence is valid? A: Because it was confirmed by a bunch of experimental data. Q: How do we know that our experiments were done correctly? And so on. In mathematics, it might ask a series of questions about why a certain theorem is true, which we chase back through a series of lemmas, down to a bunch of basic axioms and rules of inference. We could be asked to justify these, but typically we just posit them. The Trilemma says that there are three ways this sequence of justifications can end up:
- we arrive at an endpoint of premises that don’t require any justification
- we continue indefinitely in a chain of justifications that never ends
- we continue in a chain of justifications that eventually becomes circular
None of these seems to be satisfactory for an experimental science, which is partly why we say that there’s no certainty about empirical knowledge. In mathematics, the first option is regarded as OK: all statements in mathematics are “really” of the form if axioms A, B, C etc. are assumed, then conclusions X, Y, Z etc. eventually follow. We might eventually find that some axioms don’t apply to the things we’re interested in, and cease to care about those statements, but they’ll remain true. They won’t be explanations of anything very much, though. If we’re looking at reality, it’s not enough to assume axioms A, B, C… We also want to check them, test them, see if they’re true – and we can’t be completely sure with only a finite amount of evidence.
The explanatory variation on Agrippa’s Trilemma, which I have in mind, deals with a slightly different problem. Supposing the axioms seem to be true, and accepting provisionally that they are, we also have another question, which if anything is even more basic to science: we want to know WHY they’re true – we look for an explanation.
This is about looking for coherence, rather than confidence, in our knowledge (or at any rate, theories). But a similar problem appears. Suppose that elementary chemistry has explained organic chemistry; that atomic physics has explained why chemistry is how it is; and that the Standard model explains why atomic physics is how it is. We still want to know why the Standard Model is the way it is, and so on. Each new explanation gives an account for one phenomenon in terms of different, more basic phenomenon. The Trilemma suggests the following options:
- we arrive at an endpoint of premises that don’t require any explanation
- we continue indefinitely in a chain of explanations that never ends
- we continue in a chain of explanations that eventually becomes circular
Unless we accept option 1, we don’t have room for a “fundamental theory”.
Here’s the key point: this isn’t even a position about physics – it’s about epistemology, and what explanations are like, or maybe rather what our behaviour is like with regard to explanations. The standard version of Agrippa’s Trilemma is usually taken as an argument for something like fallibilism: that our knowledge is always uncertain. This variation isn’t talking about the justification of beliefs, but the sufficiency of explanation. It says that the way our mind works is such that there can’t be one final summation of the universe, one principle, which accounts for everything – because it would either be unaccounted for itself, or because it would have to account for itself by circular reasoning.
This might be a dangerous statement to make, or at least a theological one (theology isn’t as dangerous as it used to be): reasoning that things are the way they are “because God made it that way” is a traditional answer of the first type. True or not, I don’t think you can really call an “explanation”, since it would work equally well if things were some other way. In fact, it’s an anti-explanation: if you accept an uncaused-cause anywhere along the line, the whole motivation for asking after explanations unravels. Maybe this sort of answer is a confession of humility and acceptance of limited understanding, where we draw the line and stop demanding further explanations. I don’t see that we all need to draw that line in the same place, though, so the problem hasn’t gone away.
What seems likely to me is that this problem can’t be made to go away. That the situation we’ll actually be in is (2) on the list above. That while there might not be any specific thing that scientific theories can’t explain, neither could there be a “fundamental theory” that will be satisfying to the curious forever. Instead, we have an asymptotic approach to explanation, as each thing we want to explain gets picked up somewhere along the line: “We change from weaker to stronger lights, and each more powerful light pierces our hitherto opaque foundations and reveals fresh and different opacities below.”
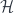 . A Hilbert basis for
. A Hilbert basis for  will only be a subspace of
will only be a subspace of  , has a Hilbert basis consisting of sequences like
, has a Hilbert basis consisting of sequences like  with just a single nonzero entry. This is a countably infinite set. However, not all square-summable sequences can be written as a finite linear combination of these. Using the axiom of choice (!) it’s possible to prove that there is some vector-space basis, but it will be a uncountably infinite. In fact, no Hilbert space has countably-infinite vector-space dimension.
with just a single nonzero entry. This is a countably infinite set. However, not all square-summable sequences can be written as a finite linear combination of these. Using the axiom of choice (!) it’s possible to prove that there is some vector-space basis, but it will be a uncountably infinite. In fact, no Hilbert space has countably-infinite vector-space dimension. of one another if they produce matching regions about the origin of size
of one another if they produce matching regions about the origin of size  – then the thing is to study cohomology of such spaces, and so forth).
– then the thing is to study cohomology of such spaces, and so forth). is still true, but the proof I have in my thesis (in the special case where the groupoids are flat connection groupoids on spaces) has a problem. Since that affects the Part 4 of “Spans and Vector Spaces” which I was going to post, I’ll put that off for a while as I get the proof straightened out.
is still true, but the proof I have in my thesis (in the special case where the groupoids are flat connection groupoids on spaces) has a problem. Since that affects the Part 4 of “Spans and Vector Spaces” which I was going to post, I’ll put that off for a while as I get the proof straightened out.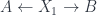 and
and 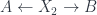 . Picking basis objects for
. Picking basis objects for  and
and  (namely, objects
(namely, objects 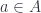 and
and 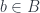 , plus representations
, plus representations 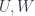 of their automorphism groups) gives a subgroupoid of of
of their automorphism groups) gives a subgroupoid of of 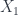 , consisting of those objects
, consisting of those objects  which are sent to
which are sent to  and
and  under the maps in the span. It also gives a vector space which is built as a colimit of some vector spaces associated to these objects. Assuming
under the maps in the span. It also gives a vector space which is built as a colimit of some vector spaces associated to these objects. Assuming ![W^{\ast} \otimes_{\mathbb{C}[Aut(x)]} U](https://s0.wp.com/latex.php?latex=W%5E%7B%5Cast%7D+%5Cotimes_%7B%5Cmathbb%7BC%7D%5BAut%28x%29%5D%7D+U&bg=ffffff&fg=29303b&s=0&c=20201002) for each of the
for each of the 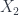 .
. making the obvious diagram commute. Then because of that commutation, we also have a span of groupoids over each of the choices
making the obvious diagram commute. Then because of that commutation, we also have a span of groupoids over each of the choices  of objects, and so then the question becomes, partly, how to get a linear map between the vector spaces we just constructed. If you have bases for all the vector spaces here, it’s not too bad: vectors can be seen as complex-valued functions on the basis. We can push these through the span just as we’ve been talking about in the last few posts here: first pull back a function along one leg by composition, then push forward along the other leg. The push-forward will involve a sum over some objects, and some normalizing factors having to do with the groupoid cardinalities of the groupoids in the span.
of objects, and so then the question becomes, partly, how to get a linear map between the vector spaces we just constructed. If you have bases for all the vector spaces here, it’s not too bad: vectors can be seen as complex-valued functions on the basis. We can push these through the span just as we’ve been talking about in the last few posts here: first pull back a function along one leg by composition, then push forward along the other leg. The push-forward will involve a sum over some objects, and some normalizing factors having to do with the groupoid cardinalities of the groupoids in the span. . I’d hoped that Schur’s lemma (that intertwiners from
. I’d hoped that Schur’s lemma (that intertwiners from 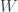 to itself, or from
to itself, or from 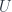 to itself, have to be multiples of the identity) would get out of this problem, but I’m not sure it does. So there is a problem with the construction I was trying to use.
to itself, have to be multiples of the identity) would get out of this problem, but I’m not sure it does. So there is a problem with the construction I was trying to use.