As usual, this write-up process has been taking a while since life does intrude into blogging for some reason. In this case, because for a little less than a week, my wife and I have been on our honeymoon, which was delayed by our moving to Lisbon. We went to the Azores, or rather to São Miguel, the largest of the nine islands. We had a good time, roughly like so:

Now that we’re back, I’ll attempt to wrap up with the summaries of things discussed at the workshop on Higher Gauge Theory, TQFT, and Quantum Gravity. In the previous post I described talks which I roughly gathered under TQFT and Higher Gauge Theory, but the latter really ramifies out in a few different ways. As began to be clear before, higher bundles are classified by higher cohomology of manifolds, and so are gerbes – so in fact these are two slightly different ways of talking about the same thing. I also remarked, in the summary of Konrad Waldorf’s talk, the idea that the theory of gerbes on a manifold is equivalent to ordinary gauge theory on its loop space – which is one way to make explicit the idea that categorification “raises dimension”, in this case from parallel transport of points to that of 1-dimensional loops. Next we’ll expand on that theme, and then finally reach the “Quantum Gravity” part, and draw the connection between this and higher gauge theory toward the end.
Gerbes and Cohomology
The very first workshop speaker, in fact, was Paolo Aschieri, who has done a lot of work relating noncommutative geometry and gravity. In this case, though, he was talking about noncommutative gerbes, and specifically referred to this work with some of the other speakers. To be clear, this isn’t about gerbes with noncommutative group 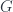 , but about gerbes on noncommutative spaces. To begin with, it’s useful to express gerbes in the usual sense in the right language. In particular, he explain what a gerbe on a manifold
, but about gerbes on noncommutative spaces. To begin with, it’s useful to express gerbes in the usual sense in the right language. In particular, he explain what a gerbe on a manifold  is in concrete terms, giving Hitchin’s definition (viz). A
is in concrete terms, giving Hitchin’s definition (viz). A 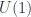 gerbe can be described as “a cohomology class” but it’s more concrete to present it as:
gerbe can be described as “a cohomology class” but it’s more concrete to present it as:
- a collection of line bundles
 associated with double overlaps
associated with double overlaps 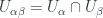 . Note this gets an algebraic structure (multiplication
. Note this gets an algebraic structure (multiplication  of bundles is pointwise
of bundles is pointwise  , with an inverse given by the dual,
, with an inverse given by the dual,  , so we can require…
, so we can require…
 , which helps define…
, which helps define…- transition functions
 on triple overlaps
on triple overlaps  , which are sections of
, which are sections of  . If this product is trivial, there’d be a 1-cocycle condition here, but we only insist on the 2-cocycle condition…
. If this product is trivial, there’d be a 1-cocycle condition here, but we only insist on the 2-cocycle condition…

This is a -gerbe on a commutative space. The point is that one can make a similar definition for a noncommutative space. If the space is associated with the algebra 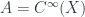 of smooth functions, then a line bundle is a module for
of smooth functions, then a line bundle is a module for  , so if is noncommutative (thought of as a “space” ), a “bundle over is just defined to be an -module. One also has to define an appropriate “covariant derivative” operator
, so if is noncommutative (thought of as a “space” ), a “bundle over is just defined to be an -module. One also has to define an appropriate “covariant derivative” operator 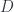 on this module, and the -product must be defined as well, and will be noncommutative (we can think of it as a deformation of the above). The transition functions are sections: that is, elements of the modules in question. his means we can describe a gerbe in terms of a big stack of modules, with a chosen algebraic structure, together with some elements. The idea then is that gerbes can give an interpretation of cohomology of noncommutative spaces as well as commutative ones.
on this module, and the -product must be defined as well, and will be noncommutative (we can think of it as a deformation of the above). The transition functions are sections: that is, elements of the modules in question. his means we can describe a gerbe in terms of a big stack of modules, with a chosen algebraic structure, together with some elements. The idea then is that gerbes can give an interpretation of cohomology of noncommutative spaces as well as commutative ones.
Mauro Spera spoke about a point of view of gerbes based on “transgressions”. The essential point is that an  -gerbe on a space can be seen as the obstruction to patching together a family of
-gerbe on a space can be seen as the obstruction to patching together a family of  -gerbes. Thus, for instance, a 0-gerbe is a -bundle, which is to say a complex line bundle. As described above, a 1-gerbe can be understood as describing the obstacle to patching together a bunch of line bundles, and the obstacle is the ability to find a cocycle
-gerbes. Thus, for instance, a 0-gerbe is a -bundle, which is to say a complex line bundle. As described above, a 1-gerbe can be understood as describing the obstacle to patching together a bunch of line bundles, and the obstacle is the ability to find a cocycle 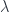 satisfying the requisite conditions. This obstacle is measured by the cohomology of the space. Saying we want to patch together -gerbes on the fibre. He went on to discuss how this manifests in terms of obstructions to string structures on manifolds (already discussed at some length in the post on Hisham Sati’s school talk, so I won’t duplicate here).
satisfying the requisite conditions. This obstacle is measured by the cohomology of the space. Saying we want to patch together -gerbes on the fibre. He went on to discuss how this manifests in terms of obstructions to string structures on manifolds (already discussed at some length in the post on Hisham Sati’s school talk, so I won’t duplicate here).
A talk by Igor Bakovic, “Stacks, Gerbes and Etale Groupoids”, gave a way of looking at gerbes via stacks (see this for instance). The organizing principle is the classification of bundles by the space maps into a classifying space – or, to get the category of principal -bundles on, the category 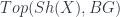 , where
, where 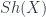 is the category of sheaves on and
is the category of sheaves on and 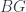 is the classifying topos of -sets. (So we have geometric morphisms between the toposes as the objects.) Now, to get further into this, we use that is equivalent to the category of Étale spaces over – this is a refinement of the equivalence between bundles and presheaves. Taking stalks of a presheaf gives a bundle, and taking sections of a bundle gives a presheaf – and these operations are adjoint.
is the classifying topos of -sets. (So we have geometric morphisms between the toposes as the objects.) Now, to get further into this, we use that is equivalent to the category of Étale spaces over – this is a refinement of the equivalence between bundles and presheaves. Taking stalks of a presheaf gives a bundle, and taking sections of a bundle gives a presheaf – and these operations are adjoint.
The issue at hand is how to categorify this framework to talk about 2-bundles, and the answer is there’s a 2-adjunction between the 2-category 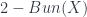 of such things, and
of such things, and ![Fib(X) = [\mathcal{O}(X)^{op},Cat]](https://s0.wp.com/latex.php?latex=Fib%28X%29+%3D+%5B%5Cmathcal%7BO%7D%28X%29%5E%7Bop%7D%2CCat%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , the 2-category of fibred categories over . (That is, instead of looking at “sheaves of sets”, we look at “sheaves of categories” here.) The adjunction, again, involves talking stalks one way, and taking sections the other way. One hard part of this is getting a nice definition of “stalk” for stacks (i.e. for the “sheaves of categories”), and a good part of the talk focused on explaining how to get a nice tractable definition which is (fibre-wise) equivalent to the more natural one.
, the 2-category of fibred categories over . (That is, instead of looking at “sheaves of sets”, we look at “sheaves of categories” here.) The adjunction, again, involves talking stalks one way, and taking sections the other way. One hard part of this is getting a nice definition of “stalk” for stacks (i.e. for the “sheaves of categories”), and a good part of the talk focused on explaining how to get a nice tractable definition which is (fibre-wise) equivalent to the more natural one.
Bakovic did a bunch of this work with Branislav Jurco, who was also there, and spoke about “Nonabelian Bundle 2-Gerbes“. The paper behind that link has more details, which I’ve yet to entirely absorb, but the essential point appears to be to extend the description of “bundle gerbes” associated to crossed modules up to 2-crossed modules. Bundles, with a structure-group , are classified by the cohomology  with coefficients in ; and whereas “bundle-gerbes” with a structure-crossed-module
with coefficients in ; and whereas “bundle-gerbes” with a structure-crossed-module 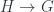 can likewise be described by cohomology
can likewise be described by cohomology  . Notice this is a bit different from the description in terms of higher cohomology
. Notice this is a bit different from the description in terms of higher cohomology  for a -gerbe, which can be understood as a bundle-gerbe using the shifted crossed module
for a -gerbe, which can be understood as a bundle-gerbe using the shifted crossed module 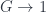 (when is abelian. The goal here is to generalize this part to nonabelian groups, and also pass up to “bundle 2-gerbes” based on a 2-crossed module, or crossed complex of length 2,
(when is abelian. The goal here is to generalize this part to nonabelian groups, and also pass up to “bundle 2-gerbes” based on a 2-crossed module, or crossed complex of length 2, 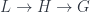 as I described previously for Joao Martins’ talk. This would be classified in terms of cohomology valued in the 2-crossed module. The point is that one can describe such a thing as a bundle over a fibre product, which (I think – I’m not so clear on this part) deals with the same structure of overlaps as the higher cohomology in the other way of describing things.
as I described previously for Joao Martins’ talk. This would be classified in terms of cohomology valued in the 2-crossed module. The point is that one can describe such a thing as a bundle over a fibre product, which (I think – I’m not so clear on this part) deals with the same structure of overlaps as the higher cohomology in the other way of describing things.
Finally, a talk that’s a little harder to classify than most, but which I’ve put here with things somewhat related to string theory, was Alexander Kahle‘s on “T-Duality and Differential K-Theory”, based on work with Alessandro Valentino. This uses the idea of the differential refinement of cohomology theories – in this case, K-theory, which is a generalized cohomology theory, which is to say that K-theory satisfies the Eilenberg-Steenrod axioms (with the dimension axiom relaxed, hence “generalized”). Cohomology theories, including generalized ones, can have differential refinements, which pass from giving topological to geometrical information about a space. So, while K-theory assigns to a space the Grothendieck ring of the category of vector bundles over it, the differential refinement of K-theory does the same with the category of vector bundles with connection. This captures both local and global structures, which turns out to be necessary to describe fields in string theory – specifically, Ramond-Ramond fields. The point of this talk was to describe what happens to these fields under T-duality. This is a kind of duality in string theory between a theory with large strings and small strings. The talk describes how this works, where we have a manifold with fibres at each point 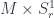 with fibres strings of radius
with fibres strings of radius  and
and  with radius
with radius 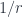 . There’s a correspondence space
. There’s a correspondence space 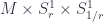 , which has projection maps down into the two situations. Fields, being forms on such a fibration, can be “transferred” through this correspondence space by a “pull-back and push-forward” (with, in the middle, a wedge with a form that mixes the two directions,
, which has projection maps down into the two situations. Fields, being forms on such a fibration, can be “transferred” through this correspondence space by a “pull-back and push-forward” (with, in the middle, a wedge with a form that mixes the two directions,  ). But to be physically the right kind of field, these “forms” actually need to be representing cohomology classes in the differential refinement of K-theory.
). But to be physically the right kind of field, these “forms” actually need to be representing cohomology classes in the differential refinement of K-theory.
Quantum Gravity etc.
Now, part of the point of this workshop was to try to build, or anyway maintain, some bridges between the kind of work in geometry and topology which I’ve been describing and the world of physics. There are some particular versions of physical theories where these ideas have come up. I’ve already touched on string theory along the way (there weren’t many talks about it from a physicist’s point of view), so this will mostly be about a different sort of approach.
Benjamin Bahr gave a talk outlining this approach for our mathematician-heavy audience, with his talk on “Spin Foam Operators” (see also for instance this paper). The point is that one approach to quantum gravity has a theory whose “kinematics” (the description of the state of a system at a given time) is described by “spin networks” (based on  gauge theory), as described back in the pre-school post. These span a Hilbert space, so the “dynamical” issue of such models is how to get operators between Hilbert spaces from “foams” that interpolate between such networks – that is, what kind of extra data they might need, and how to assign amplitudes to faces and edges etc. to define an operator, which (assuming a “local” theory where distant parts of the foam affect the result independently) will be of the form:
gauge theory), as described back in the pre-school post. These span a Hilbert space, so the “dynamical” issue of such models is how to get operators between Hilbert spaces from “foams” that interpolate between such networks – that is, what kind of extra data they might need, and how to assign amplitudes to faces and edges etc. to define an operator, which (assuming a “local” theory where distant parts of the foam affect the result independently) will be of the form:

where 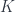 is a particular complex (foam),
is a particular complex (foam), 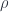 is a way of assigning irreps to faces of the foam, and
is a way of assigning irreps to faces of the foam, and 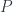 is the assignment of intertwiners to edges. Later on, one can take a discrete version of a path integral by summing over all these
is the assignment of intertwiners to edges. Later on, one can take a discrete version of a path integral by summing over all these 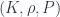 . Here we have a product over faces and one over vertices, with an amplitude
. Here we have a product over faces and one over vertices, with an amplitude 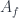 assigned (somehow – this is the issue) to faces. The trace is over all the representation spaces assigned to the edges that are incident to a vertex (this is essentially the only consistent way to assign an amplitude to a vertex). If we also consider spacetimes with boundary, we need some amplitudes
assigned (somehow – this is the issue) to faces. The trace is over all the representation spaces assigned to the edges that are incident to a vertex (this is essentially the only consistent way to assign an amplitude to a vertex). If we also consider spacetimes with boundary, we need some amplitudes 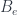 at the boundary edges, as well. A big part of the work with such models is finding such amplitudes that meet some nice conditions.
at the boundary edges, as well. A big part of the work with such models is finding such amplitudes that meet some nice conditions.
Some of these conditions are inherently necessary – to ensure the theory is invariant under gauge transformations, or (formally) changing orientations of faces. Others are considered optional, though to me “functoriality” (that the way of deriving operators respects the gluing-together of foams) seems unavoidable – it imposes that the boundary amplitudes have to be found from the in one specific way. Some other nice conditions might be: that 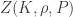 depends only on the topology of (which demands that the operators be projections); that
depends only on the topology of (which demands that the operators be projections); that  is invariant under subdivision of the foam (which implies the amplitudes have to be
is invariant under subdivision of the foam (which implies the amplitudes have to be 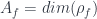 ).
).
Assuming all these means the only choice is exactly which sub-projection  is of the projection onto the gauge-invariant part of the representation space for the faces attached to edge
is of the projection onto the gauge-invariant part of the representation space for the faces attached to edge  . The rest of the talk discussed this, including some examples (models for BF-theory, the Barrett-Crane model and the more recent EPRL/FK model), and finished up by discussing issues about getting a nice continuum limit by way of “coarse graining”.
. The rest of the talk discussed this, including some examples (models for BF-theory, the Barrett-Crane model and the more recent EPRL/FK model), and finished up by discussing issues about getting a nice continuum limit by way of “coarse graining”.
On a related subject, Bianca Dittrich spoke about “Dynamics and Diffeomorphism Symmetry in Discrete Quantum Gravity”, which explained the nature of some of the hard problems with this sort of discrete model of quantum gravity. She began by asking what sort of models (i.e. which choices of amplitudes) in such discrete models would actually produce a nice continuum theory – since gravity, classically, is described in terms of spacetimes which are continua, and the quantum theory must look like this in some approximation. The point is to think of these as “coarse-graining” of a very fine (perfect, in the limit) approximation to the continuum by a triangulation with a very short length-scale for the edges. Coarse graining means discarding some of the edges to get a coarser approximation (perhaps repeatedly). If the happens to be triangulation-independent, then coarse graining makes no difference to the result, nor does the converse process of refining the triangulation. So one question is: if we expect the continuum limit to be diffeomorphism invariant (as is General Relativity), what does this say at the discrete level? The relation between diffeomorphism invariance and triangulation invariance has been described by Hendryk Pfeiffer, and in the reverse direction by Dittrich et al.
Actually constructing the dynamics for a system like this in a nice way (“canonical dynamics with anomaly-free constraints”) is still a big problem, which Bianca suggested might be approached by this coarse-graining idea. Now, if a theory is topological (here we get the link to TQFT), such as electromagnetism in 2D, or (linearized) gravity in 3D, coarse graining doesn’t change much. But otherwise, changing the length scale means changing the action for the continuum limit of the theory. This is related to renormalization: one starts with a “naive” guess at a theory, then refines it (in this case, by the coarse-graining process), which changes the action for the theory, until arriving at (or approximating to) a fixed point. Bianca showed an example, which produces a really huge, horrible action full of very complicated terms, which seems rather dissatisfying. What’s more, she pointed out that, unless the theory is topological, this always produces an action which is non-local – unlike the “naive” discrete theory. That is, the action can’t be described in terms of a bunch of non-interacting contributions from the field at individual points – instead, it’s some function which couples the field values at distant points (albeit in a way that falls off exponentially as the points get further apart).
In a more specific talk, Aleksandr Mikovic discussed “Finiteness and Semiclassical Limit of EPRL-FK Spin Foam Models”, looking at a particular example of such models which is the (relatively) new-and-improved candidate for quantum gravity mentioned above. This was a somewhat technical talk, which I didn’t entirely follow, but roughly, the way he went at this was through the techniques of perturbative QFT. That is, by looking at the theory in terms of an “effective action”, instead of some path integral over histories 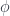 with action
with action  – which looks like
– which looks like  . Starting with some classical history
. Starting with some classical history  – a stationary point of the action
– a stationary point of the action 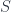 – the effective action
– the effective action  is an integral over small fluctuations around it of
is an integral over small fluctuations around it of  .
.
He commented more on the distinction between the question of triangulation independence (which is crucial for using spin foams to give invariants of manifolds) and the question of whether the theory gives a good quantum theory of gravity – that’s the “semiclassical limit” part. (In light of the above, this seems to amount to asking if “diffeomorphism invariance” really extends through to the full theory, or is only approximately true, in the limiting case). Then the “finiteness” part has to do with the question of getting decent asymptotic behaviour for some of those weights mentioned above so as to give a nice effective action (if not necessarily triangulation independence). So, for instance, in the Ponzano-Regge model (which gives a nice invariant for manifolds), the vertex amplitudes  are found by the 6j-symbols of representations. The asymptotics of the 6j symbols then becomes an issue – Alekandr noted that to get a theory with a nice effective action, those 6j-symbols need to be scaled by a certain factor. This breaks triangulation independence (hence means we don’t have a good manifold invariant), but gives a physically nicer theory. In the case of 3D gravity, this is not what we want, but as he said, there isn’t a good a-priori reason to think it can’t give a good theory of 4D gravity.
are found by the 6j-symbols of representations. The asymptotics of the 6j symbols then becomes an issue – Alekandr noted that to get a theory with a nice effective action, those 6j-symbols need to be scaled by a certain factor. This breaks triangulation independence (hence means we don’t have a good manifold invariant), but gives a physically nicer theory. In the case of 3D gravity, this is not what we want, but as he said, there isn’t a good a-priori reason to think it can’t give a good theory of 4D gravity.
Now, making a connection between these sorts of models and higher gauge theory, Aristide Baratin spoke about “2-Group Representations for State Sum Models”. This is a project Baez, Freidel, and Wise, building on work by Crane and Sheppard (see my previous post, where Derek described the geometry of the representation theory for some 2-groups). The idea is to construct state-sum models where, at the kinematical level, edges are labelled by 2-group representations, faces by intertwiners, and tetrahedra by 2-intertwiners. (This assumes the foam is a triangulation – there’s a certain amount of back-and-forth in this area between this, and the Poincaré dual picture where we have 4-valent vertices). He discussed this in a couple of related cases – the Euclidean and Poincaré 2-groups, which are described by crossed modules with base groups  or
or  respectively, acting on the abelian group (of automorphisms of the identity)
respectively, acting on the abelian group (of automorphisms of the identity)  in the obvious way. Then the analogy of the 6j symbols above, which are assigned to tetrahedra (or dually, vertices in a foam interpolating two kinematical states), are now 10j symbols assigned to 4-simplexes (or dually, vertices in the foam).
in the obvious way. Then the analogy of the 6j symbols above, which are assigned to tetrahedra (or dually, vertices in a foam interpolating two kinematical states), are now 10j symbols assigned to 4-simplexes (or dually, vertices in the foam).
One nice thing about this setup is that there’s a good geometric interpretation of the kinematics – irreducible representations of these 2-groups pick out orbits of the action of the relevant 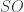 on . These are “mass shells” – radii of spheres in the Euclidean case, or proper length/time values that pick out hyperboloids in the Lorentzian case of . Assigning these to edges has an obvious geometric meaning (as a proper length of the edge), which thus has a continuous spectrum. The areas and volumes interpreting the intertwiners and 2-intertwiners start to exhibit more of the discreteness you see in the usual formulation with representations of the groups themselves. Finally, Aristide pointed out that this model originally arose not from an attempt to make a quantum gravity model, but from looking at Feynman diagrams in flat space (a sort of “quantum flat space” model), which is suggestively interesting, if not really conclusively proving anything.
on . These are “mass shells” – radii of spheres in the Euclidean case, or proper length/time values that pick out hyperboloids in the Lorentzian case of . Assigning these to edges has an obvious geometric meaning (as a proper length of the edge), which thus has a continuous spectrum. The areas and volumes interpreting the intertwiners and 2-intertwiners start to exhibit more of the discreteness you see in the usual formulation with representations of the groups themselves. Finally, Aristide pointed out that this model originally arose not from an attempt to make a quantum gravity model, but from looking at Feynman diagrams in flat space (a sort of “quantum flat space” model), which is suggestively interesting, if not really conclusively proving anything.
Finally, Laurent Freidel gave a talk, “Classical Geometry of Spin Network States” which was a way of challenging the idea that these states are exclusively about “quantum geometries”, and tried to give an account of how to interpret them as discrete, but classical. That is, the quantization of the classical phase space  (the cotangent bundle of connections-mod-gauge) involves first a discretization to a spin-network phase space
(the cotangent bundle of connections-mod-gauge) involves first a discretization to a spin-network phase space  , and then a quantization to get a Hilbert space
, and then a quantization to get a Hilbert space  , and the hard part is the first step. The point is to see what the classical phase space is, and he describes it as a (symplectic) quotient
, and the hard part is the first step. The point is to see what the classical phase space is, and he describes it as a (symplectic) quotient  , which starts by assigning $T^*(SU(2))$ to each edge, then reduced by gauge transformations. The puzzle is to interpret the states as geometries with some discrete aspect.
, which starts by assigning $T^*(SU(2))$ to each edge, then reduced by gauge transformations. The puzzle is to interpret the states as geometries with some discrete aspect.
The answer is that one thinks of edges as describing (dual) faces, and vertices as describing some polytopes. For each  , there’s a
, there’s a  -dimensional “shape space” of convex polytopes with -faces and a given fixed area
-dimensional “shape space” of convex polytopes with -faces and a given fixed area 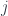 . This has a canonical symplectic structure, where lengths and interior angles at an edge are the canonically conjugate variables. Then the whole phase space describes ways of building geometries by gluing these things (associated to vertices) together at the corresponding faces whenever the two vertices are joined by an edge. Notice this is a bit strange, since there’s no particular reason the faces being glued will have the same shape: just the same area. An area-1 pentagon and an area-1 square associated to the same edge could be glued just fine. Then the classical geometry for one of these configurations is build of a bunch of flat polyhedra (i.e. with a flat metric and connection on them). Measuring distance across a face in this geometry is a little strange. Given two points inside adjacent cells, you measure orthogonal distance to the matched faces, and add in the distance between the points you arrive at (orthogonally) – assuming you glued the faces at the centre. This is a rather ugly-seeming geometry, but it’s symplectically isomorphic to the phase space of spin network states – so it’s these classical geometries that spin-foam QG is a quantization of. Maybe the ugliness should count against this model of quantum gravity – or maybe my aesthetic sense just needs work.
. This has a canonical symplectic structure, where lengths and interior angles at an edge are the canonically conjugate variables. Then the whole phase space describes ways of building geometries by gluing these things (associated to vertices) together at the corresponding faces whenever the two vertices are joined by an edge. Notice this is a bit strange, since there’s no particular reason the faces being glued will have the same shape: just the same area. An area-1 pentagon and an area-1 square associated to the same edge could be glued just fine. Then the classical geometry for one of these configurations is build of a bunch of flat polyhedra (i.e. with a flat metric and connection on them). Measuring distance across a face in this geometry is a little strange. Given two points inside adjacent cells, you measure orthogonal distance to the matched faces, and add in the distance between the points you arrive at (orthogonally) – assuming you glued the faces at the centre. This is a rather ugly-seeming geometry, but it’s symplectically isomorphic to the phase space of spin network states – so it’s these classical geometries that spin-foam QG is a quantization of. Maybe the ugliness should count against this model of quantum gravity – or maybe my aesthetic sense just needs work.
(Laurent also gave another talk, which was originally scheduled as one of the school talks, but ended up being a very interesting exposition of the principle of “Relativity of Localization”, which is hard to shoehorn into the themes I’ve used here, and was anyway interesting enough that I’ll devote a separate post to it.)
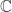


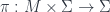
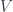
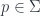
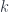

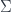
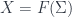
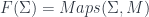


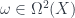

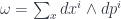
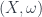
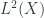


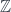 -graded group: that is, a tower of groups of “cocycles”, one group for each
-graded group: that is, a tower of groups of “cocycles”, one group for each 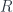 is a cohomology theory, it can be “twisted” over
is a cohomology theory, it can be “twisted” over  into the “
into the “ ). The main result is that, while topological twists are classified by appropriate gerbes on
). The main result is that, while topological twists are classified by appropriate gerbes on  “… and yet there aren’t all that many examples, and very few large ones, known.
“… and yet there aren’t all that many examples, and very few large ones, known.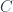 acted on by a group
acted on by a group 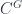 has objects which consist of an object
has objects which consist of an object 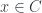 which is fixed by the action of
which is fixed by the action of 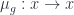 for each
for each  , satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in
, satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in  for some group
for some group 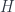 ) – or a weakened version of such a thing (it’s Morita equivalent to ).
) – or a weakened version of such a thing (it’s Morita equivalent to ).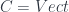 , then
, then 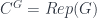 (in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in
(in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in  , we get an adjoint pair of functors between
, we get an adjoint pair of functors between 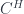 , which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a
, which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a  . The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.
. The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.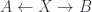
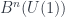 , the classifying space for
, the classifying space for 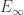 -rings.
-rings.
 -algebra approach used in noncommutative geometry. One motivation of quantales is to say that they simultaneously incorporate the generalizations made in both of these directions – so that both locales and
-algebra approach used in noncommutative geometry. One motivation of quantales is to say that they simultaneously incorporate the generalizations made in both of these directions – so that both locales and  (“meet”) and
(“meet”) and 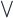 (“join”). These operations take the role of the intersection and union of open sets. So to say it formally resembles a lattice of open sets means that the lattice is closed under arbitrary joins, and finite meets, and satisfies the distributive law:
(“join”). These operations take the role of the intersection and union of open sets. So to say it formally resembles a lattice of open sets means that the lattice is closed under arbitrary joins, and finite meets, and satisfies the distributive law: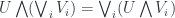
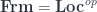 .
. , so while it is special, it isn’t unique. One vital fact here is that any topological space (via the lattice of open sets) produces a locale, and the locale is enough to identify the space – so
, so while it is special, it isn’t unique. One vital fact here is that any topological space (via the lattice of open sets) produces a locale, and the locale is enough to identify the space – so  is an embedding. (For convenience, I’m eliding over the fact that the spaces have to be “sober” – for example, Hausdorff.) In terms of logic, we could imagine that the space is a “state space”, and the truth values in the logic identify for which states a given proposition is true. There’s nothing particularly exotic about this: “it is raining” is a statement whose truth is local, in that it depends on where and when you happen to look.
is an embedding. (For convenience, I’m eliding over the fact that the spaces have to be “sober” – for example, Hausdorff.) In terms of logic, we could imagine that the space is a “state space”, and the truth values in the logic identify for which states a given proposition is true. There’s nothing particularly exotic about this: “it is raining” is a statement whose truth is local, in that it depends on where and when you happen to look. are locales that come from topological spaces, there are no extra morphisms in
are locales that come from topological spaces, there are no extra morphisms in  that don’t come from continuous maps in
that don’t come from continuous maps in 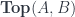 . So the category of locales makes the category of topological spaces bigger only by adding more objects – not inventing new morphisms. The analogous noncommutative statement turns out not to be true for quantales, which is a little red-flag warning which Pedro Resende pointed out to me.
. So the category of locales makes the category of topological spaces bigger only by adding more objects – not inventing new morphisms. The analogous noncommutative statement turns out not to be true for quantales, which is a little red-flag warning which Pedro Resende pointed out to me. : the category of locally compact, Hausdorff, topological spaces is (up to equivalence) the opposite of the category of commutative
: the category of locally compact, Hausdorff, topological spaces is (up to equivalence) the opposite of the category of commutative 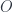 determines an ideal – namely, the subspace of functions which vanish on
determines an ideal – namely, the subspace of functions which vanish on  . Note that unlike the meet, this isn’t assumed to be commutative – this is the point where the generalization happens. So in particular, any locate gives a quantale with
. Note that unlike the meet, this isn’t assumed to be commutative – this is the point where the generalization happens. So in particular, any locate gives a quantale with  . So does any
. So does any  . Consider two distinct lines through the origin of
. Consider two distinct lines through the origin of 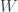 , there is an orthogonal complement
, there is an orthogonal complement 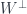 .
.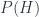 . This is one of those orthocomplemented lattices again, since projections and subspaces are closely related. There’s a quantale that can be formed out of its endomorphisms,
. This is one of those orthocomplemented lattices again, since projections and subspaces are closely related. There’s a quantale that can be formed out of its endomorphisms, 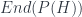 , where the product is composition. In any quantale, one can talk about the “right” elements (and the “left” elements, and “two sided” elements), by analogy with right/left/two-sided ideals – these are elements which, if you take the product with the maximal element,
, where the product is composition. In any quantale, one can talk about the “right” elements (and the “left” elements, and “two sided” elements), by analogy with right/left/two-sided ideals – these are elements which, if you take the product with the maximal element,  , the result is less than or equal to what you started with:
, the result is less than or equal to what you started with:  means
means  is a right element. The right elements of the quantale I just mentioned happen to form a lattice which is just isomorphic to
is a right element. The right elements of the quantale I just mentioned happen to form a lattice which is just isomorphic to  of a space
of a space  of schemes equipped with maps into
of schemes equipped with maps into 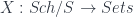 by
by  . (That is, the usual way a space determines a representable sheaf). There are also differential-geometric versions of gerbes.
. (That is, the usual way a space determines a representable sheaf). There are also differential-geometric versions of gerbes. over a space
over a space  , such that none of the
, such that none of the  is empty.
is empty.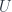 , all the objects
, all the objects 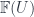 are isomorphic (i.e.
are isomorphic (i.e.  needn’t be empty – only some cover such that local objects exist – but where they do, they’re all “the same”. These conditions can also be summarized in terms of the fibred category
needn’t be empty – only some cover such that local objects exist – but where they do, they’re all “the same”. These conditions can also be summarized in terms of the fibred category 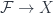 . There are two maps from
. There are two maps from  – the projection and the diagonal. The conditions respectively say these two maps are, locally, epi (i.e. surjective).
– the projection and the diagonal. The conditions respectively say these two maps are, locally, epi (i.e. surjective). is actually a sheaf of algebras over some scheme
is actually a sheaf of algebras over some scheme 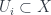 , we have:
, we have: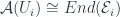
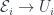 . A special case is when
. A special case is when 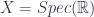 is just a point, in which case an Azumaya algebra
is just a point, in which case an Azumaya algebra  . So Azumaya algebras are not too complicated to describe.
. So Azumaya algebras are not too complicated to describe. for an Azumaya algebra is also not too complicated: a splitting is a way to represent an algebra as endomorphisms of a vector bundle – which in this case may only be possible locally. Over an given
for an Azumaya algebra is also not too complicated: a splitting is a way to represent an algebra as endomorphisms of a vector bundle – which in this case may only be possible locally. Over an given  , where
, where 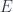 is a vector bundle over
is a vector bundle over  is an isomorphism. The morphisms are bundle isomorphisms that commute with the
is an isomorphism. The morphisms are bundle isomorphisms that commute with the 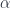 . So, roughly: if
. So, roughly: if  over
over  ). Then
). Then 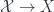 is a gerbe over
is a gerbe over  over a neighborhood
over a neighborhood  where
where  is an isomorphism of line bundles. That is, the objects locally look like
is an isomorphism of line bundles. That is, the objects locally look like  roots of
roots of  on
on 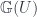 and the automorphism group
and the automorphism group 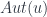 for each object
for each object  over
over 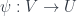 of open sets.) So the band is, so to speak, the “local symmetry group over
of open sets.) So the band is, so to speak, the “local symmetry group over 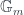 , where over any given neighborhood,
, where over any given neighborhood,  , where
, where  is the group of units in the base field: that is, the group
is the group of units in the base field: that is, the group  consists of all the invertible sections in the structure sheaf of
consists of all the invertible sections in the structure sheaf of  to the automorphism that acts through multiplication by
to the automorphism that acts through multiplication by 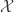 associated to a line bundle is banded by the group of
associated to a line bundle is banded by the group of ![[F] \in H^2(X,\mathbb{G})](https://s0.wp.com/latex.php?latex=%5BF%5D+%5Cin+H%5E2%28X%2C%5Cmathbb%7BG%7D%29&bg=ffffff&fg=29303b&s=0&c=20201002) . This class can be thought of as “the obstruction to the existence of a global object”. So, in the case of an Azumaya algebra, it’s the obstruction to
. This class can be thought of as “the obstruction to the existence of a global object”. So, in the case of an Azumaya algebra, it’s the obstruction to 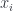 in
in  . Then there are isomorphisms comparing the different pullbacks:
. Then there are isomorphisms comparing the different pullbacks:  , and so on. (The lowered indices denote which of the
, and so on. (The lowered indices denote which of the 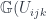 (an isomorphism corresponding to what, for sheaves of sets, would be an identity). This is
(an isomorphism corresponding to what, for sheaves of sets, would be an identity). This is  . The existence of this cocycle means that we’re getting an element in
. The existence of this cocycle means that we’re getting an element in 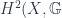 , which we denote
, which we denote ![[\mathbb{F}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathbb%7BF%7D%5D&bg=ffffff&fg=29303b&s=0&c=20201002) . If a global object exists, then all our local objects are restrictions of a global one, the cocycle will always turn out to be the identity, so this class is trivial. A non-trivial class implies an obstruction to gluing the local objects into global ones.
. If a global object exists, then all our local objects are restrictions of a global one, the cocycle will always turn out to be the identity, so this class is trivial. A non-trivial class implies an obstruction to gluing the local objects into global ones. and rank
and rank  , and also a “coarse” moduli space called
, and also a “coarse” moduli space called  . Roughly, the actual space
. Roughly, the actual space 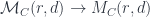 making the fine moduli space into a category fibred in groupoids – more than that, it’s a stack – and more than that, it’s a gerbe. That is, there’s always a cover of
making the fine moduli space into a category fibred in groupoids – more than that, it’s a stack – and more than that, it’s a gerbe. That is, there’s always a cover of ![[\star / G ] = BG](https://s0.wp.com/latex.php?latex=%5B%5Cstar+%2F+G+%5D+%3D+BG&bg=ffffff&fg=29303b&s=0&c=20201002) consists of
consists of 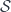 is a functor
is a functor 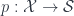 where the preimage over
where the preimage over 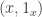 is a groupoid (that is, all the morphisms mapping to an identity are invertible).
is a groupoid (that is, all the morphisms mapping to an identity are invertible). one gets a (weak) functor from
one gets a (weak) functor from  for each object
for each object  . Specifying this and showing it is a weak functor takes a little work. But in particular, there are properties on CFG’s a stack is such a functor into
. Specifying this and showing it is a weak functor takes a little work. But in particular, there are properties on CFG’s a stack is such a functor into  with the extra property that descent data are effective. This is a weak version of the condition for a sheaf.
with the extra property that descent data are effective. This is a weak version of the condition for a sheaf. (topological spaces), or
(topological spaces), or  (affine schemes), or something else – the classical version has
(affine schemes), or something else – the classical version has  , the category of open sets on a topological space. The main thing is that
, the category of open sets on a topological space. The main thing is that  . This is a collection
. This is a collection  of arrows satisfying some conditions that capture the intuitive idea of “open cover”.
of arrows satisfying some conditions that capture the intuitive idea of “open cover”. can also be represented in
can also be represented in 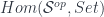 (by the Yoneda embedding) as the sheaf
(by the Yoneda embedding) as the sheaf 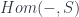 which gives, for each space
which gives, for each space  for any
for any  which satisfy some conditions that capture the intuitive idea of covering
which satisfy some conditions that capture the intuitive idea of covering 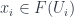 , and isomorphisms between the restrictions (by
, and isomorphisms between the restrictions (by  ) to overlaps
) to overlaps  , where the isomorphisms satisfy some cocycle condition ensuring that restrictions to
, where the isomorphisms satisfy some cocycle condition ensuring that restrictions to 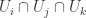 are equal. The datum is effective if all there is a “global” object
are equal. The datum is effective if all there is a “global” object 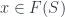 where
where 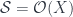 , where it says we can glue functions on local patches that agree on overlaps, and find that they must have come by restricting a global function on
, where it says we can glue functions on local patches that agree on overlaps, and find that they must have come by restricting a global function on 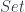 (or some other 1-category), but the point for stacks is that we have a weak functor
(or some other 1-category), but the point for stacks is that we have a weak functor 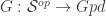 . That is, the values are in groupoids, which naturally form a 2-category. So the descent can be weakened – instead of an equality in the cocycle condition, we get an isomorphism, which has to be coherent. Part of the point of describing stacks as “sheaves of groupoids” is as a weakening this way of describing a space, to an “up to equivalence” kind of condition.
. That is, the values are in groupoids, which naturally form a 2-category. So the descent can be weakened – instead of an equality in the cocycle condition, we get an isomorphism, which has to be coherent. Part of the point of describing stacks as “sheaves of groupoids” is as a weakening this way of describing a space, to an “up to equivalence” kind of condition.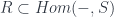 – that is, for each space
– that is, for each space  , in a way that gets along with composition of maps (which is how they resemble ideals). Any covering defines a seive – as the subfunctor of maps which factor through the covering maps – but more than one covering might define the same sieve (rather the same way an ideal can be presented in terms of different generators).
, in a way that gets along with composition of maps (which is how they resemble ideals). Any covering defines a seive – as the subfunctor of maps which factor through the covering maps – but more than one covering might define the same sieve (rather the same way an ideal can be presented in terms of different generators). and
and  , where
, where 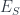 and
and  are some sheaves on
are some sheaves on  is a groupoid. The functor
is a groupoid. The functor  as having objects which are compatible collections of objects from
as having objects which are compatible collections of objects from  and isomorphisms between their restrictions – that is, descent data – and morphisms being compatible maps. So equivalence of these (2-)functors ends up being the stack condition.
and isomorphisms between their restrictions – that is, descent data – and morphisms being compatible maps. So equivalence of these (2-)functors ends up being the stack condition. – a map which induces isomorphisms between homotopy groups of
– a map which induces isomorphisms between homotopy groups of 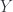 (as far as homotopy theory can detect,
(as far as homotopy theory can detect, 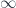 -categories, for instance), is what makes the study of
-categories, for instance), is what makes the study of 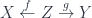
 which commutes with those in the cocycle. These form a category
which commutes with those in the cocycle. These form a category  . The point of introducing this is to say that there is a correspondence between components in this category – that is,
. The point of introducing this is to say that there is a correspondence between components in this category – that is,  and homotopy classes of maps from
and homotopy classes of maps from ![[X,Y]](https://s0.wp.com/latex.php?latex=%5BX%2CY%5D&bg=ffffff&fg=29303b&s=0&c=20201002) in homotopy theory).
in homotopy theory).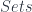 , where weak equivalence is isomorphism, then
, where weak equivalence is isomorphism, then 