This is the second post of my thoughts inspired mainly by reading Fernando Zalamea’s “Synthetic Philosophy of Contemporary Mathematics” (and also a few other sources). The first part is here.
I do have a few issues with the Zalamea book: mainly, as a reader, pinning down what a lot of the sentences really mean can be hard. This might be a combination perfectly reasonable things: the fact that it’s doing philosophy – and it’s not analytic philosophy, which aspires to math-like rigour. (Indeed, one of the many ideas the book throws around is that of “synthetic philosophy”, modelled not after formal logic, but sheaf theory, with many local points of view and ways of relating them in areas where they overlap. Intuitively appealing, though it’s hard to see how to make it rigorous in the same way.)
So, many of the ideas are still formative, and the terms used to describe them are sometimes new coinages. Then, too, the combination of philosophical jargon and the fact that it’s translated from Spanish probably contribute. So I give the author the benefit of the doubt on this point and interpret the best I can. Even so, it’s still difficult for me to say exactly what some of it is saying. In any case, here I wanted to break down my understanding of some themes it is pointing out. There is more there than I have space to deal with here, but these are some major ones.
I had a somewhat similar response to David Corfield’s book, “Toward a Philosophy of Real Mathematics” (which Zalamea mentions in a chapter where he acknowledges some authors who have engaged the kind of issues he’s interested in). That is, both of them do well at pointing out topics which haven’t received much attention, but the main strength is by pointing out areas of actual mathematical activity, and describing what they’re like (for example, Corfield’s chapter on higher category theory, and Zalamea’s account of Grothendieck’s work). They both feel sort of preliminary, though, in that they’re pointing out areas where a lot more people need to study, argue, and generally thrash out various positions on the issues before (at least as far as I can see) one could hope to say the issues raised have actually been dealt with.
Themes
In any case, part of the point is that for a philosophical take on what mathematicians are actually studying, we need to look at some details. In the previous post I outlined the summary (from philosopher Albert Lautman) of the themes of “Elementary” and “Classical” mathematics. Lautman introduced five themes apropos to the “Modern” period – characterizing what was new compared to the “Classical” (say, pre-1900 or so). Zalamea’s claim, which seems correct to me, is that all of these themes are still present today, but some new ones have been added.
That is, mathematics is cumulative: all the qualities from previous periods stay important, but as it develops, new aspects of mathematics become visible. Thus, Lautman had five points, which are somewhat detailed, but the stand-out points to my mind include:
The existence of a great many different axiomatic systems and theories, which are not reducible to each other, but are related in various ways . Think of the profusion of different algebraic gadgets, such as groups, rings, quandles, magmas, and so on, each of which has its own particular flavour. Whereas Classical mathematics did a lot with, say, the real number system, the Modern period not only invented a bunch of other number systems and algebras, but also a range of different axiom systems for describing different generalizations. The same could be said in analysis: the work on the Calculus in the Classical period leads into the definition of a metric space and then a topological space in the Modern period, and an increasing profusion of specific classes of them with different properties (think of all the various separation axioms, for example, and the web of implications relating them).
The study of a rich class of examples of different axiomatic systems. Here the standout example to me is the classification of the finite groups, where the “semantics” of the classification is much more complex than the “syntax” of the theory. This reminds me of the game of Go (a.k.a. Wei Chi in China, or Baduk in Korea), which has gained some recent fame because of the famous AlphaGo victories. The analogy: that the rules of the game are very simple, but the actual practice of play is very difficult to master, and the variety of examples of games is huge. This is, essentially, because of a combinatorial explosion, and somewhat the same principle is at work in mathematics: the theory of groups has, essentially, just three axioms on one set with three structures (the unit, the inverse, and the multiplication – a 0-ary, unary, and binary operation respectively), so the theory is quite simple. Yet the classification of all the examples is complicated and full of lots of exceptions (like the sporadic simple groups), to the point that it was only finished in Contemporary times. Similar things could be said about topological spaces.
A unity of methods beyond apparent variety. An example cited being the connection between the Galois group of field extensions and the group of deck transformations of a certain kind of branched cover of spaces. In either case, the idea is to study a mathematical object by way of its group of automorphisms over some fixed base object – and in particular to classify intermediate objects by way of the subgroups of this big group. Here, the “base object” could refer to either a sub-field (which is a sub-object in the category of fields) or a base space for the cover (which is not – it’s a quotient, or more generically the target of a projection morphism). These are conceptually different kinds of things on the face of it, but the mechanism of studying “homomorphisms over” them is similar. In fact, following through the comparison reveals a unification, by considering the fields of functions on the spaces: a covering space then has a function field which is an extension of the base case, and the two apparently different situations turn out to correspond exactly.
A “dialectical movement that is a back-and-forth between the One and the Many”. This is one of those jargon-sounding terms (especially the Hegelian-sounding term “dialectic”) and is a bit abstract. The examples given include:
- The way multiple variants on some idea are thought up, which in turn get unified into a more general theory, which in turn spawns its own variants, and so on. So, as people study different axiom systems for set theory, and their models, this diversity gets unified into the study of the general principles of how such systems all fit together. That is, as “meta-mathematics”, which considers which models satisfy a given theorem, which axioms are required to prove it, etc.
- The way branches of mathematics (algebra, geometry, analysis, etc.) diverge and develop their own distinct characters, only to be re-unified by mixing them together in new subjects: algebraic geometry, analytic number theory, geometric analysis, etc. intil they again seem like parts of a big interrelated whole. Beyond these obvious cases, the supposedly different sub-disciplines develop distinctive ideas, tools, and methods, but then borrow them from each other as fast as they specialize. This back-and-forth between specialization and cross-fertilization is thus an example of “dialectic”.
Zalamea suggests that in the Contemporary period, all these themes are still present, but that some new ones have become important as well:
“Structural Impurity of Arithmetic” – this is related to subjects outside my range of experience, like the Weil Conjectures and the Langlands Program, so I don’t have much to say about it, except to note that, by way of arithmetic functions like zeta functions, they relate number theory to algebraic curves and geometry, and constitute a huge research program that came into being in the Contemporary period (specifically the late 1960’s and early 1970’s). (Edward Frenkel described the Langlands program as “a kind of grand unified theory of mathematics” for this among other reasons.)
Geometrization of Mathematics – essentially, the migration of tools and methods originally developed for like the way topos theory turns logic into a kind of geometry in which the topology of a space provides the algebra of possible truth values. This feeds into the pervasive use of sheaves in modern mathematics, etc. Or, again, the whole field of noncommutative geometry, geometric ideas about space are interpreted as (necessarily commutative) algebra of functions on that space with pointwise multiplication: differential operators like the Lagrangian, for instance, capture metric geometry, while bundles over a space have an interpretation in terms of modules over the algebra. These geometric concepts can be applied to noncommutative algebras 
“Schematization”, and becoming detached from foundations: in particular, the idea that what it means to study, for instance, “groups” is best understood in terms of the properties of the category of groups, and that an equivalent category, where the objects have some different construction, is just as good. You see this especially in the world of 
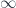
“Fluxion and Deformation” of the boundaries of some previously fixed subject. “Fluxion” is one of those bits of jargon-sounding words which is suggestive, but I’m not entirely clear if it has a precise measing. This gets at the whole area of deformation theory, quantization (in all its various guises), and so on. That is, what’s happening here is that previously-understood structures which seemed to be discrete come to be understood as points on a continuum. Thus, for instance, we have 
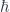
There’s also reflexivity of modern mathematics, theories applied to themselves. This is another one of those cases where it’s less clear to me what the term is meant to suggest (though examples given include fixed point theorems and classification theorems.)
There’s a list near the beginning of notable mathematicians who illustrate
Zalamea synthesizes these into three big trends described with newly coined terms: “eidal“, “quiddital“, and “archaeal” mathematics. He recognizes these are just convenient rules of thumb for characterizing broad aspects of contemporary research, rather than rigorously definable ideas or subfields. This is a part of the book which I find more opaque than the rest – but essentially the distinction seems to be as follows.
Roughly, eidal mathematics (from the Greek eidos or “idea”) seems to describe the kind that involves moving toward the abstract, and linking apparently unrelated fields of study. One big example referenced here is the Langlands program, which is a bunch of conjectures connecting number theory to geometry. Also under this umbrella he references category theory, especially via Lawvere, which subsumes many different fields into a common framework – each being the study of some particular category such as Top, perhaps by relating it to some other category (such as, in algebraic topology, Grp).
The new term quiddital mathematics (from Latin quidditas, “what exists” or literally “whatness”) appears to refer to the sort which is intimately connected to physics. The way ideas that originate in physics have driven mathematics isn’t totally new: Calculus is a classical example. But more recently, the study of operator algebras was driven by quantum mechanics, index theory which links differential operators and topology was driven by quantum field theory, and there’s a whole plethora of mathematics that has grown out of String Theory, CFT, TQFT, and so forth – which may or may not turn out to be real physics, but were certainly inspired by theorizing about it. And, while it hasn’t had as deep an effect on pure mathematics, as far as I know, I imagine this category would include those areas of study that arose out of other applied studies, such as the theory of networks or the dynamics of large complex systems.
The third new coinage, archaeal mathematics (from arche, or “origin”, also giving the word “archetype”) is another one whose meaning is harder for me to pin down, because the explanation is quite abstract. In the structure of the explanation, this seems to be playing a role that mediates between the first two: something that mediates moving between very abstract notions and concrete realizations of them. One essential idea here is the finding of “invariants”, though what this really seems to mean is more like finding a universal structure of a given type. A simple case might be that between the axioms of groups, and particular examples that show up in practice, we might have various free groups – they’re concrete but pure examples of the theory, and other examples come from imposing more relations on them.
I’m not entirely sure about these three categories, but I do think there’s a good point here. This is that there’s a move away from the specifics and toward general principles. The huge repertoire of “contemparary” mathematics can be sort of overwhelming, and highly detailed. The five themes listed by Lautman, or Zalamea’s additional five, are an attempt to find trends, or deal descriptively with that repertoire. But it’s still, in some ways, a taxonomy: a list of features. Reducing the scheme to these three, whether this particular system makes sense to you or not, is more philosophical: rather than giving a taxonomy, it’s an effort to find underlying reasons why these themes and not others are generating the mathematics we’re doing. So, while I’m not completely convinced about this system as an account of what contemporary mathematics is about, I do find that thinking about this question sheds light on the mass of current math.
Some Thoughts
In particular, a question that I wonder about, which a project like this might help answer, is the question of whether the mathematics we’re studying today is inevitable. If, as the historical account suggests, mathematics is a time-bound process, we might well ask whether it could have gone differently. Would we expect, say, extraterrestrials, or artificial intelligences, or even human beings in isolated cultures, to discover essentially the same things as ourselves? That is, to what extent is the mathematics we’ve got culturally dependent, and
In Part I, I made an analogy between mathematics and biology, which was mainly meant to suggest why a philosophy of mathematics that goes beyond foundational questions – like the ontology of what mathematical objects are, and the logic of how proof works – is important. That is to say, mathematical questions themselves are worth studying, to see their structure, what kinds of issues they are asking about (as distinct from issues they raise by their mere existence), and so on. The analogy with biology had another face: namely, that what you discover when you ask about the substance of what mathematics looks at is that it evolves over time – in particular, that it’s cumulative. The division of mathematical practice into periods that Zalamea describes in the book (culminating in “Contemporary” mathematics, the current areas of interest) may be arbitrary, but it conveys this progression.
This biological analogy is not in the book, though I doubt it’s original to me. However, it is one that occurs to me when considering the very historically-grounded argument that is there. It’s reminiscent, to my mind, of the question of whether mathematics is “invented or discovered”. We could equally well ask whether evolution “invents” or “discovers” its products. That is, one way of talking about evolution pictures the forms of living things as pre-existing possibilities in some “fitness landscape”, and the historical process of evolving amounts to a walk across the landscape, finding local optima. Increases in the “height” of the fitness function lead, more or less by definition, to higher rates of reproduction, and therefore get reinforced, and so we end up in particular regions of the landscape.
This is a contentious – or at least very simplified – picture, since some would deny that the space of all possibilities could be specified in advance (for example, Lee Smolin and Stuart Kauffman have argued for this view.) But suppose for the moment it’s the case and let’s complete the analogy: we could imagine mathematics, similarly, as a pre-existing space of possibilities, which is explored over time. What corresponds to the “fitness” function is, presumably, whatever it is about a piece of mathematics that makes it interesting or uninteresting, and ensures that people continue to develop it.
I don’t want to get too hung up on this analogy. One of the large-scale features Zalamea finds in contemporary mathematics is precisely one that makes it different from evolution in biology. Namely, while there is a tendency to diversification (the way evolution leads to speciation and an increase in the diversity of species over time), there is also a tendency for ideas in one area of mathematics to find application in another – as if living things had a tendency to observe each other and copy each others’ innovations. Evolution doesn’t work that way, and the reason why not has to do with specifics of exactly how living things evolve: sexual reproduction, and the fact that most organisms no longer transfer genes horizontally across species, but only vertically across generations. The pattern Zalamea points out suggests that, whatever method mathematicians are using to explore the landscape of possible mathematics, it has some very different features. One of which seems to be that it rewards results or concepts in one sub-discipline for which it’s easy to find analogies and apply them into many different areas. This tendency works against what might otherwise be a trend toward rampant diversification.
Still, given this historical outlook, one high-level question would be to try to describe what features make a piece of mathematics more rewarding and encourage its development. We would then expect that over time, the theorems and frameworks that get developed will have more of those properties. This would be for reasons that aren’t so much intrinsic to the nature of mathematics as for historical reasons. Then again, if we had a satisfactory high-level account of what current mathematics is about – something like what the three-way division into eidal, quiddital, and archaeal mathematics is aiming at – that would give us a way to ask whether only certain themes, and only certain subjects and theorems, could really succeed.
I’m not sure how much this gains us within mathematics, but it might tell us how we ought to regard the mathematics we have.
 . This means that it is, in itself, an orbifold! (Someone raised size concerns here: obviously, a category which is one of its own objects presents foundational issues. So you do have to restrict to orbifolds in a universe of some given maximum size, and then you get that the
. This means that it is, in itself, an orbifold! (Someone raised size concerns here: obviously, a category which is one of its own objects presents foundational issues. So you do have to restrict to orbifolds in a universe of some given maximum size, and then you get that the  over the groupoid of finite sets and bijections
over the groupoid of finite sets and bijections 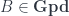 can be seen as generalizing vector spaces with a specified basis (consisting of the cardinalities 0, 1, 2, … of the finite sets). Individual maps into
can be seen as generalizing vector spaces with a specified basis (consisting of the cardinalities 0, 1, 2, … of the finite sets). Individual maps into  are “species”, and play the role of vectors. The whole apparatus of groupoidification gives a way to understand this: the groupoid cardinality of the fibre over each
are “species”, and play the role of vectors. The whole apparatus of groupoidification gives a way to understand this: the groupoid cardinality of the fibre over each  , the category (no longer a groupoid) of finite sets and injections, which carry information about how structures “restrict” along injections. The talk discussed how this gives rise to coalgebras. An example of this would be the
, the category (no longer a groupoid) of finite sets and injections, which carry information about how structures “restrict” along injections. The talk discussed how this gives rise to coalgebras. An example of this would be the 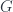 -bundles: in terms of local trivializations and gluing functions; in terms of a bundle over
-bundles: in terms of local trivializations and gluing functions; in terms of a bundle over  with a free, proper action of
with a free, proper action of  . The first corresponds to a picture involving anafunctors and a complex of
. The first corresponds to a picture involving anafunctors and a complex of 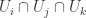 and so on; the third generalizes naturally by simply taking
and so on; the third generalizes naturally by simply taking 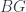 to by any space, not just a homotopy 1-type. The talk concentrated on the middle term of the three. A big part of it amounted to coming up with a suitable definition for a “principal” action of an
to by any space, not just a homotopy 1-type. The talk concentrated on the middle term of the three. A big part of it amounted to coming up with a suitable definition for a “principal” action of an 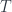 in a model category $M$, and taking the homotopy category. The question has to do with the relation between the two possible orders in which this can be done, and in particular the fact that the two orders give different results.
in a model category $M$, and taking the homotopy category. The question has to do with the relation between the two possible orders in which this can be done, and in particular the fact that the two orders give different results. , and for that reason is surely bound to be at least mathematically important. Martin Wolf’s talk, “
, and for that reason is surely bound to be at least mathematically important. Martin Wolf’s talk, “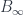 -algebras” (DG2A’s stands for “differential graded 2-algebras”) was quite interesting to me, partly because of the nice combinatorial correspondence it used between certain special kinds of tile-arrangements and particular kinds of trees with coloured nodes. These form elements of those 2-algebras in question, and a lot of it involved describing the combinatorial operations that correspond to composition, the differential, and other algebraic structures.
-algebras” (DG2A’s stands for “differential graded 2-algebras”) was quite interesting to me, partly because of the nice combinatorial correspondence it used between certain special kinds of tile-arrangements and particular kinds of trees with coloured nodes. These form elements of those 2-algebras in question, and a lot of it involved describing the combinatorial operations that correspond to composition, the differential, and other algebraic structures.
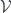 associated with the CFT’s. Matrix factorizations work like this: start with the polynomial ring
associated with the CFT’s. Matrix factorizations work like this: start with the polynomial ring ![S = k[x_1,x_2,\dots,x_n]](https://s0.wp.com/latex.php?latex=S+%3D+k%5Bx_1%2Cx_2%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=29303b&s=0&c=20201002) , and pick a polynomial
, and pick a polynomial  . If the dimension of the quotient ring of
. If the dimension of the quotient ring of 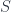 by all the derivatives of
by all the derivatives of 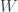 is finite-dimensional, it’s a “potential”.
is finite-dimensional, it’s a “potential”.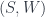 , which consists of
, which consists of 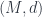 , where
, where  is a free
is a free  -graded
-graded 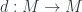 is a “twisted differential” – an
is a “twisted differential” – an 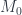 to
to 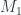 and vice versa) such that
and vice versa) such that 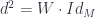 . (That is, the differential is a kind of “square root” of the potential, in this special degree-1 sense.) There is a whole bicategory of such matrix factorizations, called
. (That is, the differential is a kind of “square root” of the potential, in this special degree-1 sense.) There is a whole bicategory of such matrix factorizations, called 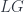 (for “Landau-Ginzburg”). Its objects are algebras with a potential,
(for “Landau-Ginzburg”). Its objects are algebras with a potential,  to
to 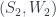 are matrix factorizations for
are matrix factorizations for 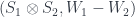 (which can be defined in a natural way), which can be composed by a kind of tensor product of modules, and the 2-morphisms are just bimodule maps.
(which can be defined in a natural way), which can be composed by a kind of tensor product of modules, and the 2-morphisms are just bimodule maps. of representations of some vertex algebra associated to a CFT. There are some partial results to the effect that there are monoidal equivalences between certain subcategories of these in particular cases (namely, for special potentials
of representations of some vertex algebra associated to a CFT. There are some partial results to the effect that there are monoidal equivalences between certain subcategories of these in particular cases (namely, for special potentials  , which is to say covariant functors which take manifolds into simplicial sets (or, more generally, some other model of
, which is to say covariant functors which take manifolds into simplicial sets (or, more generally, some other model of  in simplicial sets so that, up to homotopy, there’s an equivalence between concordance classes of fields (which might be, say, connections on bundles, or geometric structures, or various other things) and maps into the classifying space. Then, that this classifying space can be built as a homotopy colimit in a particular way. This theorem seems like a snazzier version of the
in simplicial sets so that, up to homotopy, there’s an equivalence between concordance classes of fields (which might be, say, connections on bundles, or geometric structures, or various other things) and maps into the classifying space. Then, that this classifying space can be built as a homotopy colimit in a particular way. This theorem seems like a snazzier version of the  , which takes some category of spacetimes to a category of algebras, which are supposed to be the algebra of operators on the fields on that bit of spacetime. Then breaking down spacetime into regions, you get a net of algebras that fit together in a particular way. The axioms for AQFT say things like: the algebras for two spacelike-separated regions of space should commute with each other (as subalgebras inside the one associated to a larger region containing both). This gets at the idea that the theory is causal – acting on one region doesn’t affect the other, if there’s no timelike path from one to the other. The other conditions say that when one region is embedded in another, the algebra is also embedded; and that if a small region contains a Cauchy surface for a larger region, the two algebras are actually isomorphic (i.e. having a Cauchy surface determines the whole region). These regions get patched together by local-to-global gluing condition which makes the functor into a cosheaf (not a sheaf: it’s covariant because in general bigger regions have bigger algebras of observables). The problem was that this framework is not enough to account for things like gauge theories, essentially because the gluing has some flexibility up to gauge equivalence. So the talk describes how to extend the framework of AQFT to
, which takes some category of spacetimes to a category of algebras, which are supposed to be the algebra of operators on the fields on that bit of spacetime. Then breaking down spacetime into regions, you get a net of algebras that fit together in a particular way. The axioms for AQFT say things like: the algebras for two spacelike-separated regions of space should commute with each other (as subalgebras inside the one associated to a larger region containing both). This gets at the idea that the theory is causal – acting on one region doesn’t affect the other, if there’s no timelike path from one to the other. The other conditions say that when one region is embedded in another, the algebra is also embedded; and that if a small region contains a Cauchy surface for a larger region, the two algebras are actually isomorphic (i.e. having a Cauchy surface determines the whole region). These regions get patched together by local-to-global gluing condition which makes the functor into a cosheaf (not a sheaf: it’s covariant because in general bigger regions have bigger algebras of observables). The problem was that this framework is not enough to account for things like gauge theories, essentially because the gluing has some flexibility up to gauge equivalence. So the talk describes how to extend the framework of AQFT to  being used depends on what system one wants to model. But functors into
being used depends on what system one wants to model. But functors into 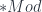 , of
, of 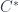 -algebras and bimodules, are seen as assigning algebraic data to physical content. There are a lot of details out of the theory of
-algebras and bimodules, are seen as assigning algebraic data to physical content. There are a lot of details out of the theory of  and
and  (the
(the 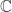 ; sigma models generalise this to the space of maps
; sigma models generalise this to the space of maps  for some other target space. These are determined by their values pointwise, so of course are local.
for some other target space. These are determined by their values pointwise, so of course are local. (the previous examples being described by trivial bundles
(the previous examples being described by trivial bundles 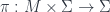 ), where the fields are sections of the bundle. Lagrangian physics is then described by a form on the
), where the fields are sections of the bundle. Lagrangian physics is then described by a form on the 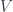 , i.e. the bundle whose fibre over
, i.e. the bundle whose fibre over 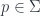 consists of the space describing the possible first
consists of the space describing the possible first 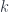 derivatives of a section over that point.
derivatives of a section over that point. for taking some space with structure – say a (pseudo-)Riemannian manifold
for taking some space with structure – say a (pseudo-)Riemannian manifold 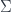 – and produce a moduli space
– and produce a moduli space 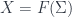 of fields. The Sigma models happen to be representable functors:
of fields. The Sigma models happen to be representable functors: 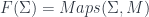 for some
for some  from which we picked target spaces
from which we picked target spaces 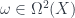 . Intuitively,
. Intuitively,  describes how the space, locally, can be split into conjugate variables. In the phase space for a particle in
describes how the space, locally, can be split into conjugate variables. In the phase space for a particle in 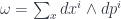 ; many other systems have analogous conjugate variables. But what really matters is the form
; many other systems have analogous conjugate variables. But what really matters is the form 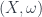 to do this. The Hilbert space is a space of sections of some bundle whose sections look like copies of the complex numbers, called the “
to do this. The Hilbert space is a space of sections of some bundle whose sections look like copies of the complex numbers, called the “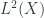 (for some measure compatible with
(for some measure compatible with  -form called a (pre-)
-form called a (pre-) over manifolds). This will give a higher analog of the Hilbert space.
over manifolds). This will give a higher analog of the Hilbert space.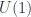 , or in general an
, or in general an 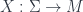 into some target manifold, or rather
into some target manifold, or rather 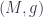 , since we need a metric to integrate and find differentials. Given this, we can define the crucial physics ingredient, an action functional
, since we need a metric to integrate and find differentials. Given this, we can define the crucial physics ingredient, an action functional![S[X] = \int_{\Sigma} g_{ij} dX^i \wedge (\star d X^j)](https://s0.wp.com/latex.php?latex=S%5BX%5D+%3D+%5Cint_%7B%5CSigma%7D+g_%7Bij%7D+dX%5Ei+%5Cwedge+%28%5Cstar+d+X%5Ej%29&bg=ffffff&fg=29303b&s=0&c=20201002)
 are the differentials of the map into
are the differentials of the map into 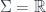 is just its worldline. In that case, minimizing the action functional above says that the particle moves along geodesics.
is just its worldline. In that case, minimizing the action functional above says that the particle moves along geodesics.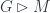 that describes “rigid” symmetries of the theory (for Minkowski space we might pick the Poincare group, or perhaps the Lorentz group if we want to fix an origin point), then the action functional on the space
that describes “rigid” symmetries of the theory (for Minkowski space we might pick the Poincare group, or perhaps the Lorentz group if we want to fix an origin point), then the action functional on the space 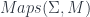 is invariant in the direction of any of the symmetries. One can use this to reduce
is invariant in the direction of any of the symmetries. One can use this to reduce 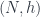 , and get a corresponding
, and get a corresponding  to integrate over
to integrate over 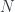 .
.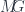 , and then just considers replacing this with some generic groupoid that doesn’t necessarily arise from a group of rigid symmetries on some underlying
, and then just considers replacing this with some generic groupoid that doesn’t necessarily arise from a group of rigid symmetries on some underlying 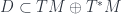 of the tangent-plus-cotangent bundle over
of the tangent-plus-cotangent bundle over  and
and  supersymmetric field theories.
supersymmetric field theories.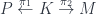
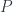 , which we call
, which we call 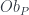 – a set of functions, differential forms, vector bundles, cohomology classes, etc. They are pulled back to
– a set of functions, differential forms, vector bundles, cohomology classes, etc. They are pulled back to 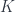 , and then “pushed forward” to
, and then “pushed forward” to 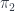 , so we have an integral transform. The image of
, so we have an integral transform. The image of 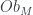 , and it consists of data satisfying, typically, some PDE’s.In the case of the PW transform,
, and it consists of data satisfying, typically, some PDE’s.In the case of the PW transform, 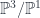 and
and 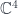 and the fields are principal
and the fields are principal 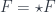 , where
, where  is the
is the 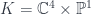 ).
).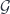 with connection. Wolf’s talk explained how there is a Penrose-Ward transform between a certain class of higher gauge theories (on the one hand) and an
with connection. Wolf’s talk explained how there is a Penrose-Ward transform between a certain class of higher gauge theories (on the one hand) and an 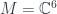 , and
, and 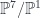 , there is a similar correspondence between certain holomorphic 2-bundles on
, there is a similar correspondence between certain holomorphic 2-bundles on 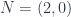 supersymmetric field theory.
supersymmetric field theory.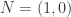 supersymmetric theory. However, unlike the
supersymmetric theory. However, unlike the 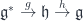
 -gauge model”.
-gauge model”.
 -valued 1-forms, where
-valued 1-forms, where 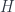 is the group of morphisms based at
is the group of morphisms based at 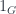 . If we think of connections as functors from the fundamental 2-groupoid
. If we think of connections as functors from the fundamental 2-groupoid 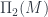 into
into 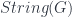 (a homotopy 2-type) is fibred over the classifying space for
(a homotopy 2-type) is fibred over the classifying space for 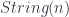 , the string 2-group associated to
, the string 2-group associated to 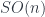 . This is the one that determines whether a given manifold can support a “string structure”. A string structure on
. This is the one that determines whether a given manifold can support a “string structure”. A string structure on 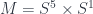 . This particular
. This particular  , and because of how the lifting works, this is also
, and because of how the lifting works, this is also 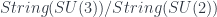 . This quotient means there’s a string bundle
. This quotient means there’s a string bundle 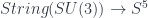 whose fibre is
whose fibre is 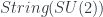 .
.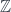 -graded group: that is, a tower of groups of “cocycles”, one group for each
-graded group: that is, a tower of groups of “cocycles”, one group for each 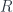 is a cohomology theory, it can be “twisted” over
is a cohomology theory, it can be “twisted” over  into the “
into the “ “… and yet there aren’t all that many examples, and very few large ones, known.
“… and yet there aren’t all that many examples, and very few large ones, known.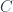 acted on by a group
acted on by a group 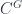 has objects which consist of an object
has objects which consist of an object 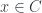 which is fixed by the action of
which is fixed by the action of 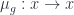 for each
for each  , satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in
, satisfying a bunch of unsurprising conditions like being compatible with the group operation. The morphisms are maps in  for some group
for some group 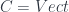 , then
, then 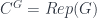 (in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in
(in particular, a “group-theoretical fusion category”). What’s more, this construction is functorial in  , we get an adjoint pair of functors between
, we get an adjoint pair of functors between 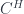 , which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a
, which in our special case are just the induced-representation and restricted-representation functors for that subgroup inclusion. That is, we have a  . The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.
. The “infinity” part means we allow morphisms between field configurations of all orders (2-morphisms, 3-morphisms, etc.). The “topos” part means that all sorts of reasonable constructions can be done – for example, pullbacks. The “differentially cohesive” part captures the sort of structure that ensures we can really treat these as spaces of the suitable kind: “cohesive” means that we have a notion of connected components around (it’s implemented by having a bunch of adjoint functors between spaces and points). The “differential” part is meant to allow for the sort of structures discussed above under “differential cohomology” – really, that we can capture geometric structure, as in gauge theories, and not just topological structure.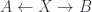
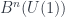 , the classifying space for
, the classifying space for  -gerbes. That is, we don’t just have these “spaces”, but these spaces equipped with one of those pieces of cohomological twisting data discussed up above. That enters the quantization like an action (it’s WHAT you integrate in a path integral).
-gerbes. That is, we don’t just have these “spaces”, but these spaces equipped with one of those pieces of cohomological twisting data discussed up above. That enters the quantization like an action (it’s WHAT you integrate in a path integral).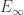 -rings.
-rings.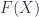 . For example,
. For example, 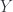 , this defines a vector space of linear combinations of fields, modulo relations, called
, this defines a vector space of linear combinations of fields, modulo relations, called  , where
, where  . The dual space of
. The dual space of 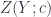 – in keeping with the principle that quantum states are functionals that we can evaluate on “classical” fields.
– in keeping with the principle that quantum states are functionals that we can evaluate on “classical” fields. .
. 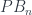 fits inside them. In particular, the slide moves satisfy some of the same relations as the braid group – the Yang-Baxter equations.
fits inside them. In particular, the slide moves satisfy some of the same relations as the braid group – the Yang-Baxter equations. . Every loop braid could be “closed up” to a 4D knotted surface, though not every knotted surface would be of this form. For one thing, our loops have a trivial embedding in 3D space here – to get every possible knotted surface, we’d need to have knots and links sliding around, braiding through each other, merging and splitting, etc. Knotted surfaces are much more complex than knotted circles, just as the topology of embedded circles is more complex than that of embedded points.
. Every loop braid could be “closed up” to a 4D knotted surface, though not every knotted surface would be of this form. For one thing, our loops have a trivial embedding in 3D space here – to get every possible knotted surface, we’d need to have knots and links sliding around, braiding through each other, merging and splitting, etc. Knotted surfaces are much more complex than knotted circles, just as the topology of embedded circles is more complex than that of embedded points. : representations on spaces where each loop is attached some
: representations on spaces where each loop is attached some 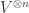 (a tensor product of
(a tensor product of 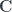 can be described in terms of its group of automorphisms: all the ways the object can be transformed which leave it “the same”. This fits our understanding of “symmetry” when the morphisms can really be interpreted as transformations of some sort. So let’s suppose the object is a set with some structure, and the morphisms are set-maps that preserve the structure: for example, the objects could be sets of vertices and edges of a graph, so that morphisms are maps of the underlying data that preserve incidence relations. So a symmetry of an object is a way of transforming it into itself – and an invertible one at that – and these automorphisms naturally form a group
can be described in terms of its group of automorphisms: all the ways the object can be transformed which leave it “the same”. This fits our understanding of “symmetry” when the morphisms can really be interpreted as transformations of some sort. So let’s suppose the object is a set with some structure, and the morphisms are set-maps that preserve the structure: for example, the objects could be sets of vertices and edges of a graph, so that morphisms are maps of the underlying data that preserve incidence relations. So a symmetry of an object is a way of transforming it into itself – and an invertible one at that – and these automorphisms naturally form a group 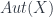 . More generally, we can talk about an action of a group
. More generally, we can talk about an action of a group 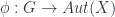 .
. is faithful: you can tell morphisms in
is faithful: you can tell morphisms in 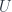 forgets about – or, conversely, that the structure on objects of
forgets about – or, conversely, that the structure on objects of 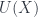 .
.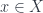 and
and  , then
, then  and
and 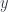 are “symmetric” points under some transformation. As Weinstein’s article illustrates nicely, though, there is no assumption that the given transformation actually extends to the entire object
are “symmetric” points under some transformation. As Weinstein’s article illustrates nicely, though, there is no assumption that the given transformation actually extends to the entire object 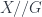 for short. Its morphisms consist of pairs such that
for short. Its morphisms consist of pairs such that  is a morphism taking
is a morphism taking 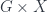 .
.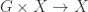 . It is not hard to show that this map is an action in another standard sense. Namely, if we have a real action
. It is not hard to show that this map is an action in another standard sense. Namely, if we have a real action 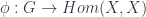 , then this map is just
, then this map is just 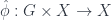 , which moves one of the arguments to the left side. If
, which moves one of the arguments to the left side. If 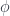 was a functor, then $\hat{\phi}$ satisfies the “action” condition, namely that the following square commutes:
was a functor, then $\hat{\phi}$ satisfies the “action” condition, namely that the following square commutes: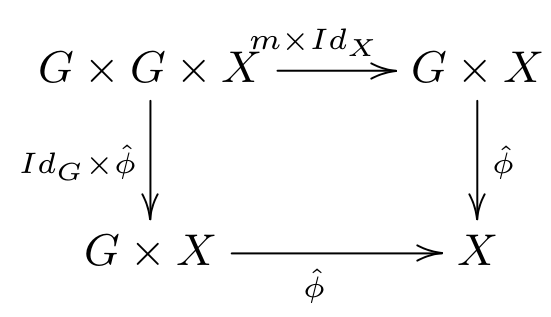
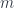 is the multiplication in
is the multiplication in  : we are thinking of
: we are thinking of 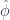 must be in the same category,
must be in the same category, 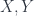 , there is an object
, there is an object 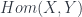 , the internal hom. In this case, it’s
, the internal hom. In this case, it’s  which appears in the diagram. Such an internal hom is supposed to be a dual to
which appears in the diagram. Such an internal hom is supposed to be a dual to  ): this is exactly what lets us talk about
): this is exactly what lets us talk about  , the category of topological spaces, where there is indeed a faithful underlying set functor. But although talking explicitly about elements of
, the category of topological spaces, where there is indeed a faithful underlying set functor. But although talking explicitly about elements of 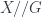 relates global and local symmetries, it played no particular role in the construction.
relates global and local symmetries, it played no particular role in the construction.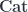 , which is a closed monoidal 2-category, which is a
, which is a closed monoidal 2-category, which is a 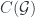 if it comes from a given 2-group. (In our paper, we keep these distinct by using the term “categorical group” for the second. The group axioms amount to saying that we have a monoidal category
if it comes from a given 2-group. (In our paper, we keep these distinct by using the term “categorical group” for the second. The group axioms amount to saying that we have a monoidal category 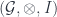 . Its objects are the morphisms of the 2-group, and the composition becomes the monoidal product
. Its objects are the morphisms of the 2-group, and the composition becomes the monoidal product 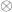 .)
.)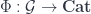 . The object being acted on,
. The object being acted on, 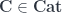 , is the unique object
, is the unique object 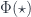 – so that the 2-functor amounts to a monoidal functor from the categorical group
– so that the 2-functor amounts to a monoidal functor from the categorical group  . Notice that here we’re taking advantage of the fact that
. Notice that here we’re taking advantage of the fact that 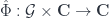 , which corresponds to the 2-functor
, which corresponds to the 2-functor 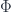 , and satisfies an action axiom like the square above, with
, and satisfies an action axiom like the square above, with  for each 2-group morphism
for each 2-group morphism 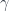 – each of which consists of a function between objects of
– each of which consists of a function between objects of 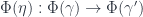 for 2-morphisms
for 2-morphisms 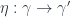 in the 2-group – each of which consists of a function from objects to morphisms of
in the 2-group – each of which consists of a function from objects to morphisms of 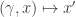 is just given by
is just given by 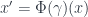 . The map taking pairs of morphisms
. The map taking pairs of morphisms 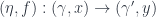 to morphisms of
to morphisms of 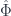 are equivalent, it should be no surprise that we ought to be able to reconstruct the other two parts of
are equivalent, it should be no surprise that we ought to be able to reconstruct the other two parts of 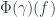 or
or 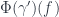 ), and the natural transformation maps (which give
), and the natural transformation maps (which give 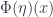 or
or 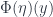 ). In fact, there are only two sensible ways to combine these four bits of information, and the fact that
). In fact, there are only two sensible ways to combine these four bits of information, and the fact that 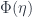 is natural means precisely that they’re the same, so:
is natural means precisely that they’re the same, so: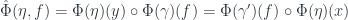
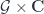 , and the target functor is just the action map
, and the target functor is just the action map 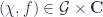 looks like:
looks like: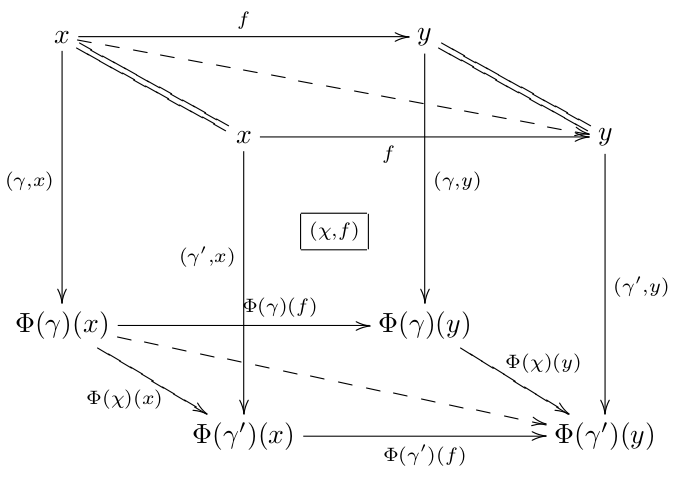

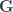 -objects on the set of
-objects on the set of 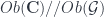 . Meanwhile, the horizontal morphisms and squares make up the transformation groupoid
. Meanwhile, the horizontal morphisms and squares make up the transformation groupoid 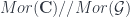 . These are the object-category and morphism-category of the transpose of the double-category we started with.
. These are the object-category and morphism-category of the transpose of the double-category we started with. and
and 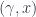 , the only 2-morphisms which can appear are those taking
, the only 2-morphisms which can appear are those taking  which has the same effect on
which has the same effect on 