One talk at the workshop was nominally a school talk by Laurent Freidel, but it’s interesting and distinctive enough in its own right that I wanted to consider it by itself. It was based on this paper on the “Principle of Relative Locality”. This isn’t so much a new theory, as an exposition of what ought to happen when one looks at a particular limit of any putative theory that has both quantum field theory and gravity as (different) limits of it. This leads through some ideas, such as curved momentum space, which have been kicking around for a while. The end result is a way of accounting for apparently non-local interactions of particles, by saying that while the particles themselves “see” the interactions as local, distant observers might not.
Whereas Einstein’s gravity describes a regime where Newton’s gravitational constant 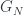 is important but Planck’s constant
is important but Planck’s constant 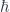 is negligible, and (special-relativistic) quantum field theory assumes significant but not. Both of these assume there is a special velocity scale, given by the speed of light
is negligible, and (special-relativistic) quantum field theory assumes significant but not. Both of these assume there is a special velocity scale, given by the speed of light  , whereas classical mechanics assumes that all three can be neglected (i.e. and are zero, and is infinite). The guiding assumption is that these are all approximations to some more fundamental theory, called “quantum gravity” just because it accepts that both and (as well as ) are significant in calculating physical effects. So GR and QFT incorporate two of the three constants each, and classical mechanics incorporates neither. The “principle of relative locality” arises when we consider a slightly different approximation to this underlying theory.
, whereas classical mechanics assumes that all three can be neglected (i.e. and are zero, and is infinite). The guiding assumption is that these are all approximations to some more fundamental theory, called “quantum gravity” just because it accepts that both and (as well as ) are significant in calculating physical effects. So GR and QFT incorporate two of the three constants each, and classical mechanics incorporates neither. The “principle of relative locality” arises when we consider a slightly different approximation to this underlying theory.
This approximation works with a regime where and are each negligible, but the ratio is not – this being related to the Planck mass 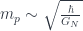 . The point is that this is an approximation with no special length scale (“Planck length”), but instead a special energy scale (“Planck mass”) which has to be preserved. Since energy and momentum are different parts of a single 4-vector, this is also a momentum scale; we expect to see some kind of deformation of momentum space, at least for momenta that are bigger than this scale. The existence of this scale turns out to mean that momenta don’t add linearly – at least, not unless they’re very small compared to the Planck scale.
. The point is that this is an approximation with no special length scale (“Planck length”), but instead a special energy scale (“Planck mass”) which has to be preserved. Since energy and momentum are different parts of a single 4-vector, this is also a momentum scale; we expect to see some kind of deformation of momentum space, at least for momenta that are bigger than this scale. The existence of this scale turns out to mean that momenta don’t add linearly – at least, not unless they’re very small compared to the Planck scale.
So what is “Relative Locality”? In the paper linked above, it’s stated like so:
Physics takes place in phase space and there is no invariant global projection that gives a description of processes in spacetime. From their measurements local observers can construct descriptions of particles moving and interacting in a spacetime, but different observers construct different spacetimes, which are observer-dependent slices of phase space.
Motivation
This arises from taking the basic insight of general relativity – the requirement that physical principles should be invariant under coordinate transformations (i.e. diffeomorphisms) – and extend it so that instead of applying just to spacetime, it applies to the whole of phase space. Phase space (which, in this limit where 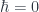 , replaces the Hilbert space of a truly quantum theory) is the space of position-momentum configurations (of things small enough to treat as point-like, in a given fixed approximation). Having no means we don’t need to worry about any dynamical curvature of “spacetime” (which doesn’t exist), and having no Planck length means we can blithely treat phase space as a manifold with coordinates valued in the real line (which has no special scale). Yet, having a special mass/momentum scale says we should see some purely combined “quantum gravity” effects show up.
, replaces the Hilbert space of a truly quantum theory) is the space of position-momentum configurations (of things small enough to treat as point-like, in a given fixed approximation). Having no means we don’t need to worry about any dynamical curvature of “spacetime” (which doesn’t exist), and having no Planck length means we can blithely treat phase space as a manifold with coordinates valued in the real line (which has no special scale). Yet, having a special mass/momentum scale says we should see some purely combined “quantum gravity” effects show up.
The physical idea is that phase space is an accurate description of what we can see and measure locally. Observers (whom we assume small enough to be considered point-like) can measure their own proper time (they “have a clock”) and can detect momenta (by letting things collide with them and measuring the energy transferred locally and its direction). That is, we “see colors and angles” (i.e. photon energies and differences of direction). Beyond this, one shouldn’t impose any particular theory of what momenta do: we can observe the momenta of separate objects and see what results when they interact and deduce rules from that. As an extension of standard physics, this model is pretty conservative. Now, conventionally, phase space would be the cotangent bundle of spacetime  . This model is based on the assumption that objects can be at any point, and wherever they are, their space of possible momenta is a vector space. Being a bundle, with a global projection onto
. This model is based on the assumption that objects can be at any point, and wherever they are, their space of possible momenta is a vector space. Being a bundle, with a global projection onto  (taking
(taking  to
to  ), is exactly what this principle says doesn’t necessarily obtain. We still assume that phase space will be some symplectic manifold. But we don’t assume a priori that momentum coordinates give a projection whose fibres happen to be vector spaces, as in a cotangent bundle.
), is exactly what this principle says doesn’t necessarily obtain. We still assume that phase space will be some symplectic manifold. But we don’t assume a priori that momentum coordinates give a projection whose fibres happen to be vector spaces, as in a cotangent bundle.
Now, a symplectic manifold still looks locally like a cotangent bundle (Darboux’s theorem). So even if there is no universal “spacetime”, each observer can still locally construct a version of “spacetime” by slicing up phase space into position and momentum coordinates. One can, by brute force, extend the spacetime coordinates quite far, to distant points in phase space. This is roughly analogous to how, in special relativity, each observer can put their own coordinates on spacetime and arrive at different notions of simultaneity. In general relativity, there are issues with trying to extend this concept globally, but it can be done under some conditions, giving the idea of “space-like slices” of spacetime. In the same way, we can construct “spacetime-like slices” of phase space.
Geometrizing Algebra
Now, if phase space is a cotangent bundle, momenta can be added (the fibres of the bundle are vector spaces). Some more recent ideas about “quasi-Hamiltonian spaces” (initially introduced by Alekseev, Malkin and Meinrenken) conceive of momenta as “group-valued” – rather than taking values in the dual of some Lie algebra (the way, classically, momenta are dual to velocities, which live in the Lie algebra of infinitesimal translations). For small momenta, these are hard to distinguish, so even group-valued momenta might look linear, but the premise is that we ought to discover this by experiment, not assumption. We certainly can detect “zero momentum” and for physical reasons can say that given two things with two momenta  , there’s a way of combining them into a combined momentum
, there’s a way of combining them into a combined momentum 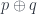 . Think of doing this physically – transfer all momentum from one particle to another, as seen by a given observer. Since the same momentum at the observer’s position can be either coming in or going out, this operation has a “negative” with
. Think of doing this physically – transfer all momentum from one particle to another, as seen by a given observer. Since the same momentum at the observer’s position can be either coming in or going out, this operation has a “negative” with  .
.
We do have a space of momenta at any given observer’s location – the total of all momenta that can be observed there, and this space now has some algebraic structure. But we have no reason to assume up front that  is either commutative or associative (let alone that it makes momentum space at a given observer’s location into a vector space). One can interpret this algebraic structure as giving some geometry. The commutator for gives a metric on momentum space. This is a bilinear form which is implicitly defined by the “norm” that assigns a kinetic energy to a particle with a given momentum. The associator given by
is either commutative or associative (let alone that it makes momentum space at a given observer’s location into a vector space). One can interpret this algebraic structure as giving some geometry. The commutator for gives a metric on momentum space. This is a bilinear form which is implicitly defined by the “norm” that assigns a kinetic energy to a particle with a given momentum. The associator given by  , infinitesimally near
, infinitesimally near 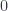 where this makes sense, gives a connection. This defines a “parallel transport” of a finite momentum
where this makes sense, gives a connection. This defines a “parallel transport” of a finite momentum  in the direction of a momentum
in the direction of a momentum  by saying infinitesimally what happens when adding
by saying infinitesimally what happens when adding  to .
to .
Various additional physical assumptions – like the momentum-space “duals” of the equivalence principle (that the combination of momenta works the same way for all kinds of matter regardless of charge), or the strong equivalence principle (that inertial mass and rest mass energy per the relation  are the same) and so forth can narrow down the geometry of this metric and connection. Typically we’ll find that it needs to be Lorentzian. With strong enough symmetry assumptions, it must be flat, so that momentum space is a vector space after all – but even with fairly strong assumptions, as with general relativity, there’s still room for this “empty space” to have some intrinsic curvature, in the form of a momentum-space “dual cosmological constant”, which can be positive (so momentum space is closed like a sphere), zero (the vector space case we usually assume) or negative (so momentum space is hyperbolic).
are the same) and so forth can narrow down the geometry of this metric and connection. Typically we’ll find that it needs to be Lorentzian. With strong enough symmetry assumptions, it must be flat, so that momentum space is a vector space after all – but even with fairly strong assumptions, as with general relativity, there’s still room for this “empty space” to have some intrinsic curvature, in the form of a momentum-space “dual cosmological constant”, which can be positive (so momentum space is closed like a sphere), zero (the vector space case we usually assume) or negative (so momentum space is hyperbolic).
This geometrization of what had been algebraic is somewhat analogous to what happened with velocities (i.e. vectors in spacetime)) when the theory of special relativity came along. Insisting that the “invariant” scale be the same in every reference system meant that the addition of velocities ceased to be linear. At least, it did if you assume that adding velocities has an interpretation along the lines of: “first, from rest, add velocity v to your motion; then, from that reference frame, add velocity w”. While adding spacetime vectors still worked the same way, one had to rephrase this rule if we think of adding velocities as observed within a given reference frame – this became  (scaling so
(scaling so  and assuming the velocities are in the same direction). When velocities are small relative to , this looks roughly like linear addition. Geometrizing the algebra of momentum space is thought of a little differently, but similar things can be said: we think operationally in terms of combining momenta by some process. First transfer (group-valued) momentum to a particle, then momentum – the connection on momentum space tells us how to translate these momenta into the “reference frame” of a new observer with momentum shifted relative to the starting point. Here again, the special momentum scale
and assuming the velocities are in the same direction). When velocities are small relative to , this looks roughly like linear addition. Geometrizing the algebra of momentum space is thought of a little differently, but similar things can be said: we think operationally in terms of combining momenta by some process. First transfer (group-valued) momentum to a particle, then momentum – the connection on momentum space tells us how to translate these momenta into the “reference frame” of a new observer with momentum shifted relative to the starting point. Here again, the special momentum scale  (which is also a mass scale since a momentum has a corresponding kinetic energy) is a “deformation” parameter – for momenta that are small compared to this scale, things seem to work linearly as usual.
(which is also a mass scale since a momentum has a corresponding kinetic energy) is a “deformation” parameter – for momenta that are small compared to this scale, things seem to work linearly as usual.
There’s some discussion in the paper which relates this to DSR (either “doubly” or “deformed” special relativity), which is another postulated limit of quantum gravity, a variation of SR with both a special velocity and a special mass/momentum scale, to consider “what SR looks like near the Planck scale”, which treats spacetime as a noncommutative space, and generalizes the Lorentz group to a Hopf algebra which is a deformation of it. In DSR, the noncommutativity of “position space” is directly related to curvature of momentum space. In the “relative locality” view, we accept a classical phase space, but not a classical spacetime within it.
Physical Implications
We should understand this scale as telling us where “quantum gravity effects” should start to become visible in particle interactions. This is a fairly large scale for subatomic particles. The Planck mass as usually given is about 21 micrograms: small for normal purposes, about the size of a small sand grain, but very large for subatomic particles. Converting to momentum units with , this is about 6 kg m/s: on the order of the momentum of a kicked soccer ball or so. For a subatomic particle this is a lot.
This scale does raise a question for many people who first hear this argument, though – that quantum gravity effects should become apparent around the Planck mass/momentum scale, since macro-objects like the aforementioned soccer ball still seem to have linearly-additive momenta. Laurent explained the problem with this intuition. For interactions of big, extended, but composite objects like soccer balls, one has to calculate not just one interaction, but all the various interactions of their parts, so the “effective” mass scale where the deformation would be seen becomes 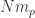 where
where 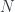 is the number of particles in the soccer ball. Roughly, the point is that a soccer ball is not a large “thing” for these purposes, but a large conglomeration of small “things”, whose interactions are “fundamental”. The “effective” mass scale tells us how we would have to alter the physical constants to be able to treat it as a “thing”. (This is somewhat related to the question of “effective actions” and renormalization, though these are a bit more complicated.)
is the number of particles in the soccer ball. Roughly, the point is that a soccer ball is not a large “thing” for these purposes, but a large conglomeration of small “things”, whose interactions are “fundamental”. The “effective” mass scale tells us how we would have to alter the physical constants to be able to treat it as a “thing”. (This is somewhat related to the question of “effective actions” and renormalization, though these are a bit more complicated.)
There are a number of possible experiments suggested in the paper, which Laurent mentioned in the talk. One involves a kind of “twin paradox” taking place in momentum space. In “spacetime”, a spaceship travelling a large loop at high velocity will arrive where it started having experienced less time than an observer who remained there (because of the Lorentzian metric) – and a dual phenomenon in momentum space says that particles travelling through loops (also in momentum space) should arrive displaced in space because of the relativity of localization. This could be observed in particle accelerators where particles make several transits of a loop, since the effect is cumulative. Another effect could be seen in astronomical observations: if an observer is observing some distant object via photons of different wavelengths (hence momenta), she might “localize” the object differently – that is, the two photons travel at “the same speed” the whole way, but arrive at different times because the observer will interpret the object as being at two different distances for the two photons.
This last one is rather weird, and I had to ask how one would distinguish this effect from a variable speed of light (predicted by certain other ideas about quantum gravity). How to distinguish such effects seems to be not quite worked out yet, but at least this is an indication that there are new, experimentally detectible, effects predicted by this “relative locality” principle. As Laurent emphasized, once we’ve noticed that not accepting this principle means making an a priori assumption about the geometry of momentum space (even if only in some particular approximation, or limit, of a true theory of quantum gravity), we’re pretty much obliged to stop making that assumption and do the experiments. Finding our assumptions were right would simply be revealing which momentum space geometry actually obtains in the approximation we’re studying.
A final note about the physical interpretation: this “relative locality” principle can be discovered by looking (in the relevant limit) at a Lagrangian for free particles, with interactions described in terms of momenta. It so happens that one can describe this without referencing a “real” spacetime: the part of the action that allows particles to interact when “close” only needs coordinate functions, which can certainly exist here, but are an observer-dependent construct. The conservation of (non-linear) momenta is specified via a Lagrange multiplier. The whole Lagrangian formalism for the mechanics of colliding particles works without reference to spacetime. Now, even though all the interactions (specified by the conservation of momentum terms) happen “at one location”, in that there will be an observer who sees them happening in the momentum space of her own location. But an observer at a different point may disagree about whether the interaction was local – i.e. happened at a single point in spacetime. Thus “relativity of localization”.
Again, this is no more bizarre (mathematically) than the fact that distant, relatively moving, observers in special relativity might disagree about simultaneity, whether two events happened at the same time. They have their own coordinates on spacetime, and transferring between them mixes space coordinates and time coordinates, so they’ll disagree whether the time-coordinate values of two events are the same. Similarly, in this phase-space picture, two different observers each have a coordinate system for splitting phase space into “spacetime” and “energy-momentum” coordinates, but switching between them may mix these two pieces. Thus, the two observers will disagree about whether the spacetime-coordinate values for the different interacting particles are the same. And so, one observer says the interaction is “local in spacetime”, and the other says it’s not. The point is that it’s local for the particles themselves (thinking of them as observers). All that’s going on here is the not-very-astonishing fact that in the conventional picture, we have no problem with interactions being nonlocal in momentum space (particles with very different momenta can interact as long as they collide with each other)… combined with the inability to globally and invariantly distinguish position and momentum coordinates.
What this means, philosophically, can be debated, but it does offer some plausibility to the claim that space and time are auxiliary, conceptual additions to what we actually experience, which just account for the relations between bits of matter. These concepts can be dispensed with even where we have a classical-looking phase space rather than Hilbert space (where, presumably, this is even more true).
…
Edit: On a totally unrelated note, I just noticed this post by Alex Hoffnung over at the n-Category Cafe which gives a lot of detail on issues relating to spans in bicategories that I had begun to think more about recently in relation to developing a higher-gauge-theoretic version of the construction I described for ETQFT. In particular, I’d been thinking about how the 2-group analog of restriction and induction for representations realizes the various kinds of duality properties, where we have adjunctions, biadjunctions, and so forth, in which units and counits of the various adjunctions have further duality. This observation seems to be due to Jim Dolan, as far as I can see from a brief note in HDA II. In that case, it’s really talking about the star-structure of the span (tri)category, but looking at the discussion Alex gives suggests to me that this theme shows up throughout this subject. I’ll have to take a closer look at the draft paper he linked to and see if there’s more to say…
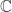


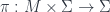
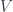
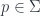
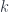

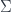
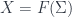
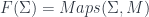


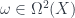


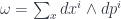


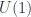
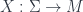 into some target manifold, or rather
into some target manifold, or rather 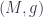 , since we need a metric to integrate and find differentials. Given this, we can define the crucial physics ingredient, an action functional
, since we need a metric to integrate and find differentials. Given this, we can define the crucial physics ingredient, an action functional![S[X] = \int_{\Sigma} g_{ij} dX^i \wedge (\star d X^j)](https://s0.wp.com/latex.php?latex=S%5BX%5D+%3D+%5Cint_%7B%5CSigma%7D+g_%7Bij%7D+dX%5Ei+%5Cwedge+%28%5Cstar+d+X%5Ej%29&bg=ffffff&fg=29303b&s=0&c=20201002)
 are the differentials of the map into
are the differentials of the map into 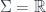 is just its worldline. In that case, minimizing the action functional above says that the particle moves along geodesics.
is just its worldline. In that case, minimizing the action functional above says that the particle moves along geodesics.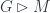 that describes “rigid” symmetries of the theory (for Minkowski space we might pick the Poincare group, or perhaps the Lorentz group if we want to fix an origin point), then the action functional on the space
that describes “rigid” symmetries of the theory (for Minkowski space we might pick the Poincare group, or perhaps the Lorentz group if we want to fix an origin point), then the action functional on the space 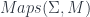 is invariant in the direction of any of the symmetries. One can use this to reduce
is invariant in the direction of any of the symmetries. One can use this to reduce  , and get a corresponding
, and get a corresponding  to integrate over
to integrate over  , and then just considers replacing this with some generic groupoid that doesn’t necessarily arise from a group of rigid symmetries on some underlying
, and then just considers replacing this with some generic groupoid that doesn’t necessarily arise from a group of rigid symmetries on some underlying 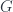 – so called Killing vectors – is zero. So this equation can generalize to a case where there are vectors where the Lie derivative is zero – a so-called “generalized Killing equation”. They may not generate isometries, but can be treated similarly. What they do give, if you integrate these vectors, is a foliation of
– so called Killing vectors – is zero. So this equation can generalize to a case where there are vectors where the Lie derivative is zero – a so-called “generalized Killing equation”. They may not generate isometries, but can be treated similarly. What they do give, if you integrate these vectors, is a foliation of 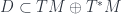 of the tangent-plus-cotangent bundle over
of the tangent-plus-cotangent bundle over  and
and  supersymmetric field theories.
supersymmetric field theories.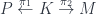
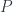 , which we call
, which we call 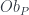 – a set of functions, differential forms, vector bundles, cohomology classes, etc. They are pulled back to
– a set of functions, differential forms, vector bundles, cohomology classes, etc. They are pulled back to 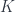 , and then “pushed forward” to
, and then “pushed forward” to 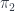 , so we have an integral transform. The image of
, so we have an integral transform. The image of 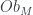 , and it consists of data satisfying, typically, some PDE’s.In the case of the PW transform,
, and it consists of data satisfying, typically, some PDE’s.In the case of the PW transform, 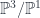 and
and 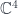 and the fields are principal
and the fields are principal 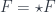 , where
, where  is the
is the 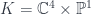 ).
).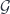 with connection. Wolf’s talk explained how there is a Penrose-Ward transform between a certain class of higher gauge theories (on the one hand) and an
with connection. Wolf’s talk explained how there is a Penrose-Ward transform between a certain class of higher gauge theories (on the one hand) and an 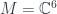 , and
, and 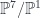 , there is a similar correspondence between certain holomorphic 2-bundles on
, there is a similar correspondence between certain holomorphic 2-bundles on 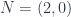 supersymmetric field theory.
supersymmetric field theory.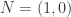 supersymmetric theory. However, unlike the
supersymmetric theory. However, unlike the 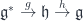
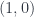 -gauge model”.
-gauge model”.